 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Pseudo-Labeler beyond Noun Concepts for Open-Vocabulary Object Detection
Dec 04, 2023



Open-vocabulary object detection (OVOD) has recently gained significant attention as a crucial step toward achieving human-like visual intelligence. Existing OVOD methods extend target vocabulary from pre-defined categories to open-world by transferring knowledge of arbitrary concepts from vision-language pre-training models to the detectors. While previous methods have shown remarkable successes, they suffer from indirect supervision or limited transferable concepts. In this paper, we propose a simple yet effective method to directly learn region-text alignment for arbitrary concepts. Specifically, the proposed method aims to learn arbitrary image-to-text mapping for pseudo-labeling of arbitrary concepts, named Pseudo-Labeling for Arbitrary Concepts (PLAC). The proposed method shows competitive performance on the standard OVOD benchmark for noun concepts and a large improvement on referring expression comprehension benchmark for arbitrary concepts.
Semantic Grouping Network for Video Captioning
Feb 03, 2021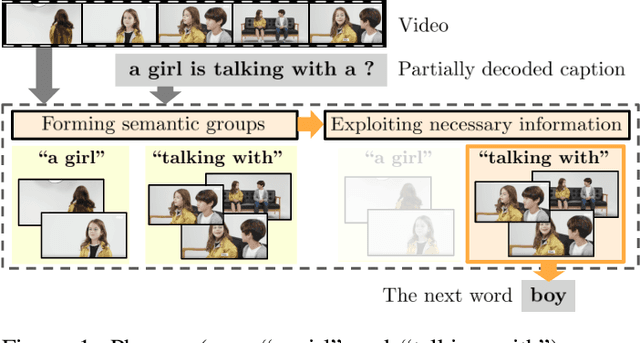
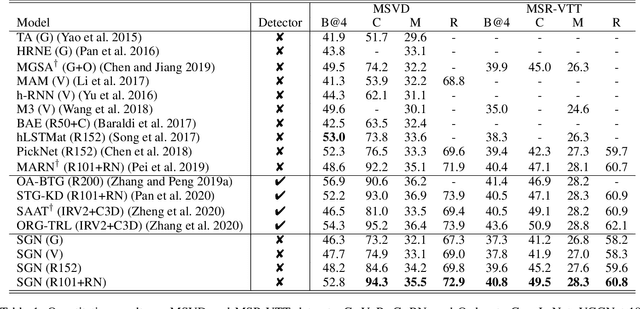

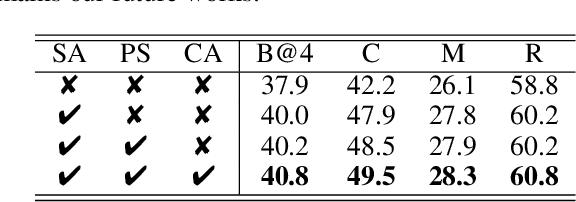
This paper considers a video caption generating network referred to as Semantic Grouping Network (SGN) that attempts (1) to group video frames with discriminating word phrases of partially decoded caption and then (2) to decode those semantically aligned groups in predicting the next word. As consecutive frames are not likely to provide unique information, prior methods have focused on discarding or merging repetitive information based only on the input video. The SGN learns an algorithm to capture the most discriminating word phrases of the partially decoded caption and a mapping that associates each phrase to the relevant video frames - establishing this mapping allows semantically related frames to be clustered, which reduces redundancy. In contrast to the prior methods, the continuous feedback from decoded words enables the SGN to dynamically update the video representation that adapts to the partially decoded caption. Furthermore, a contrastive attention loss is proposed to facilitate accurate alignment between a word phrase and video frames without manual annotations. The SGN achieves state-of-the-art performances by outperforming runner-up methods by a margin of 2.1%p and 2.4%p in a CIDEr-D score on MSVD and MSR-VTT datasets, respectively. Extensive experiments demonstrate the effectiveness and interpretability of the SGN.
VLANet: Video-Language Alignment Network for Weakly-Supervised Video Moment Retrieval
Aug 24, 2020
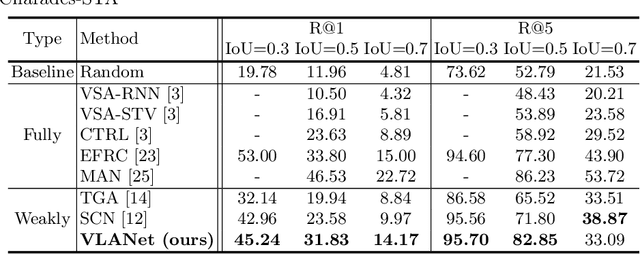
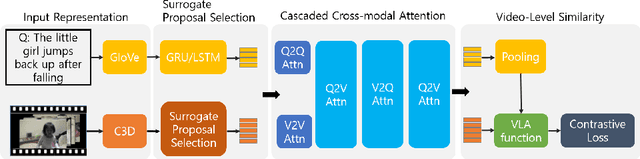
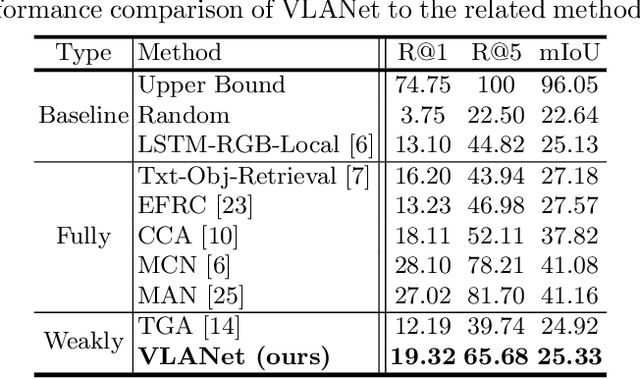
Video Moment Retrieval (VMR) is a task to localize the temporal moment in untrimmed video specified by natural language query. For VMR, several methods that require full supervision for training have been proposed. Unfortunately, acquiring a large number of training videos with labeled temporal boundaries for each query is a labor-intensive process. This paper explores methods for performing VMR in a weakly-supervised manner (wVMR): training is performed without temporal moment labels but only with the text query that describes a segment of the video. Existing methods on wVMR generate multi-scale proposals and apply query-guided attention mechanisms to highlight the most relevant proposal. To leverage the weak supervision, contrastive learning is used which predicts higher scores for the correct video-query pairs than for the incorrect pairs. It has been observed that a large number of candidate proposals, coarse query representation, and one-way attention mechanism lead to blurry attention maps which limit the localization performance. To handle this issue, Video-Language Alignment Network (VLANet) is proposed that learns sharper attention by pruning out spurious candidate proposals and applying a multi-directional attention mechanism with fine-grained query representation. The Surrogate Proposal Selection module selects a proposal based on the proximity to the query in the joint embedding space, and thus substantially reduces candidate proposals which leads to lower computation load and sharper attention. Next, the Cascaded Cross-modal Attention module considers dense feature interactions and multi-directional attention flow to learn the multi-modal alignment. VLANet is trained end-to-end using contrastive loss which enforces semantically similar videos and queries to gather. The experiments show that the method achieves state-of-the-art performance on Charades-STA and DiDeMo datasets.
A Resizable Mini-batch Gradient Descent based on a Multi-Armed Bandit
Feb 27, 2018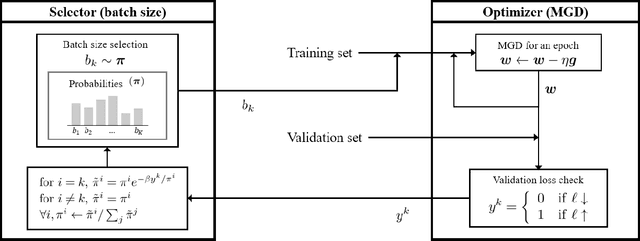

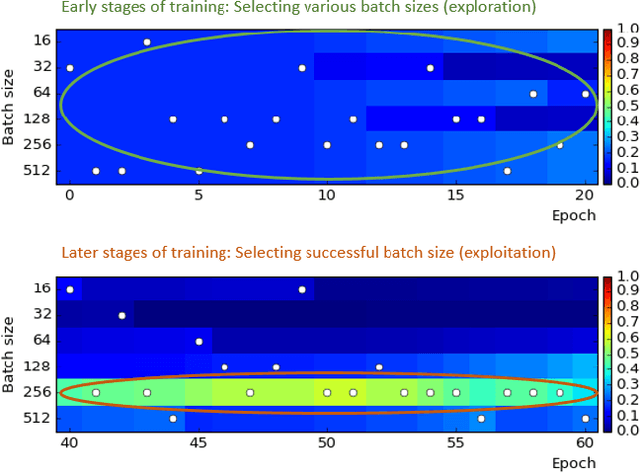
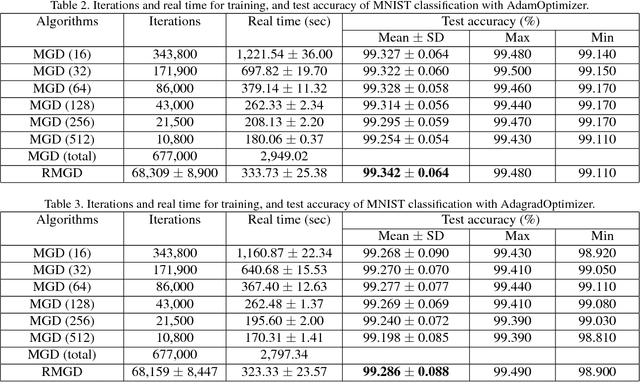
Determining the appropriate batch size for mini-batch gradient descent is always time consuming as it often relies on grid search. This paper considers a resizable mini-batch gradient descent (RMGD) algorithm based on a multi-armed bandit for achieving best performance in grid search by selecting an appropriate batch size at each epoch with a probability defined as a function of its previous success/failure. This probability encourages exploration of different batch size and then later exploitation of batch size with history of success. At each epoch, the RMGD samples a batch size from its probability distribution, then uses the selected batch size for mini-batch gradient descent. After obtaining the validation loss at each epoch, the probability distribution is updated to incorporate the effectiveness of the sampled batch size. The RMGD essentially assists the learning process to explore the possible domain of the batch size and exploit successful batch size. Experimental results show that the RMGD achieves performance better than the best performing single batch size. Furthermore, it, obviously, attains this performance in a shorter amount of time than grid search. It is surprising that the RMGD achieves better performance than grid search.