 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoneybee: Locality-enhanced Projector for Multimodal LLM
Dec 11, 2023In Multimodal Large Language Models (MLLMs), a visual projector plays a crucial role in bridging pre-trained vision encoders with LLMs, enabling profound visual understanding while harnessing the LLMs' robust capabilities. Despite the importance of the visual projector, it has been relatively less explored. In this study, we first identify two essential projector properties: (i) flexibility in managing the number of visual tokens, crucial for MLLMs' overall efficiency, and (ii) preservation of local context from visual features, vital for spatial understanding. Based on these findings, we propose a novel projector design that is both flexible and locality-enhanced, effectively satisfying the two desirable properties. Additionally, we present comprehensive strategies to effectively utilize multiple and multifaceted instruction datasets. Through extensive experiments, we examine the impact of individual design choices. Finally, our proposed MLLM, Honeybee, remarkably outperforms previous state-of-the-art methods across various benchmarks, including MME, MMBench, SEED-Bench, and LLaVA-Bench, achieving significantly higher efficiency. Code and models are available at https://github.com/kakaobrain/honeybee.
Learning Pseudo-Labeler beyond Noun Concepts for Open-Vocabulary Object Detection
Dec 04, 2023



Open-vocabulary object detection (OVOD) has recently gained significant attention as a crucial step toward achieving human-like visual intelligence. Existing OVOD methods extend target vocabulary from pre-defined categories to open-world by transferring knowledge of arbitrary concepts from vision-language pre-training models to the detectors. While previous methods have shown remarkable successes, they suffer from indirect supervision or limited transferable concepts. In this paper, we propose a simple yet effective method to directly learn region-text alignment for arbitrary concepts. Specifically, the proposed method aims to learn arbitrary image-to-text mapping for pseudo-labeling of arbitrary concepts, named Pseudo-Labeling for Arbitrary Concepts (PLAC). The proposed method shows competitive performance on the standard OVOD benchmark for noun concepts and a large improvement on referring expression comprehension benchmark for arbitrary concepts.
Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs
Dec 01, 2022We tackle open-world semantic segmentation, which aims at learning to segment arbitrary visual concepts in images, by using only image-text pairs without dense annotations. Existing open-world segmentation methods have shown impressive advances by employing contrastive learning (CL) to learn diverse visual concepts and adapting the learned image-level understanding to the segmentation task. However, these methods based on CL have a discrepancy since it only considers image-text level alignment in training time, while the segmentation task requires region-text level alignment at test time. In this paper, we propose a novel Text-grounded Contrastive Learning (TCL) framework to directly align a text and a region described by the text to address the train-test discrepancy. Our method generates a segmentation mask associated with a given text, extracts grounded image embedding from the masked region, and aligns it with text embedding via TCL. The framework addresses the discrepancy by letting the model learn region-text level alignment instead of image-text level alignment and encourages the model to directly improve the quality of generated segmentation masks. In addition, for a rigorous and fair comparison, we present a unified evaluation protocol with widely used 8 semantic segmentation datasets. TCL achieves state-of-the-art zero-shot segmentation performance with large margins in all datasets. Code is available at https://github.com/kakaobrain/tcl.
Domain Generalization by Mutual-Information Regularization with Pre-trained Models
Mar 21, 2022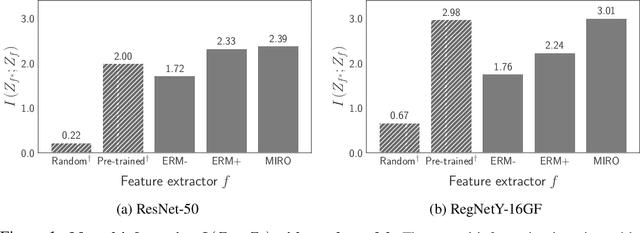
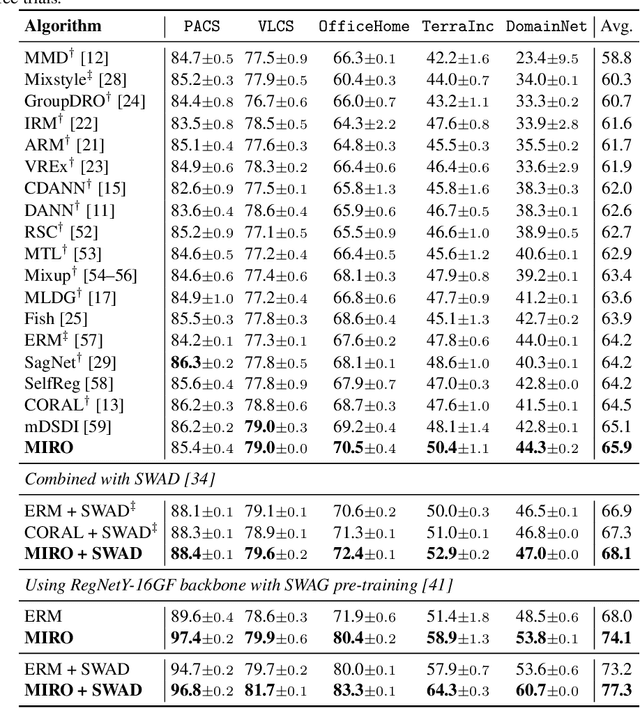
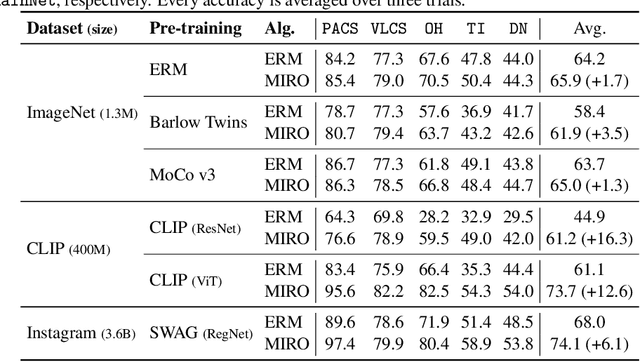
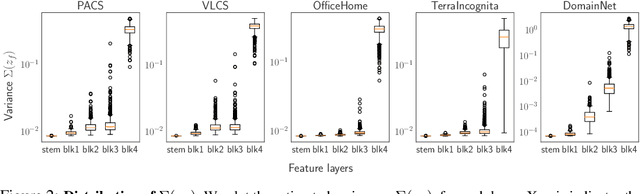
Domain generalization (DG) aims to learn a generalized model to an unseen target domain using only limited source domains. Previous attempts to DG fail to learn domain-invariant representations only from the source domains due to the significant domain shifts between training and test domains. Instead, we re-formulate the DG objective using mutual information with the oracle model, a model generalized to any possible domain. We derive a tractable variational lower bound via approximating the oracle model by a pre-trained model, called Mutual Information Regularization with Oracle (MIRO). Our extensive experiments show that MIRO significantly improves the out-of-distribution performance. Furthermore, our scaling experiments show that the larger the scale of the pre-trained model, the greater the performance improvement of MIRO. Source code is available at https://github.com/kakaobrain/miro.
Few-shot Font Generation with Weakly Supervised Localized Representations
Dec 22, 2021

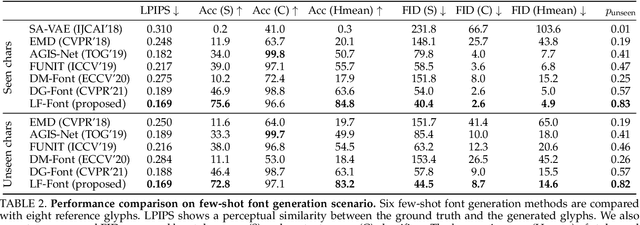
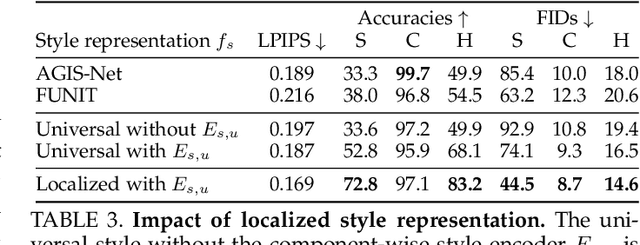
Automatic few-shot font generation aims to solve a well-defined, real-world problem because manual font designs are expensive and sensitive to the expertise of designers. Existing methods learn to disentangle style and content elements by developing a universal style representation for each font style. However, this approach limits the model in representing diverse local styles, because it is unsuitable for complicated letter systems, for example, Chinese, whose characters consist of a varying number of components (often called "radical") -- with a highly complex structure. In this paper, we propose a novel font generation method that learns localized styles, namely component-wise style representations, instead of universal styles. The proposed style representations enable the synthesis of complex local details in text designs. However, learning component-wise styles solely from a few reference glyphs is infeasible when a target script has a large number of components, for example, over 200 for Chinese. To reduce the number of required reference glyphs, we represent component-wise styles by a product of component and style factors, inspired by low-rank matrix factorization. Owing to the combination of strong representation and a compact factorization strategy, our method shows remarkably better few-shot font generation results (with only eight reference glyphs) than other state-of-the-art methods. Moreover, strong locality supervision, for example, location of each component, skeleton, or strokes, was not utilized. The source code is available at https://github.com/clovaai/lffont and https://github.com/clovaai/fewshot-font-generation.
HoughCL: Finding Better Positive Pairs in Dense Self-supervised Learning
Nov 21, 2021
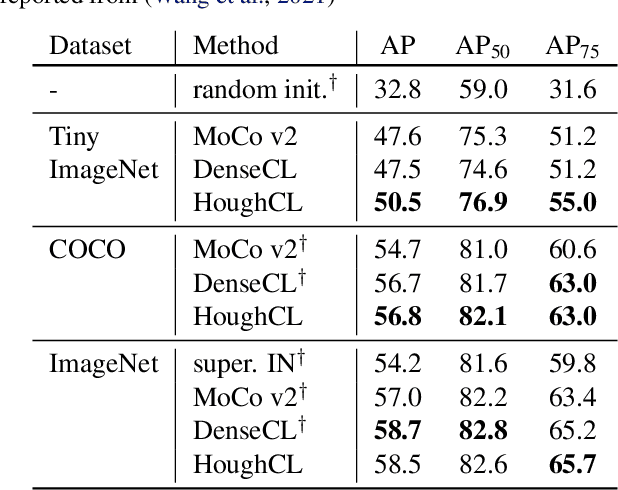
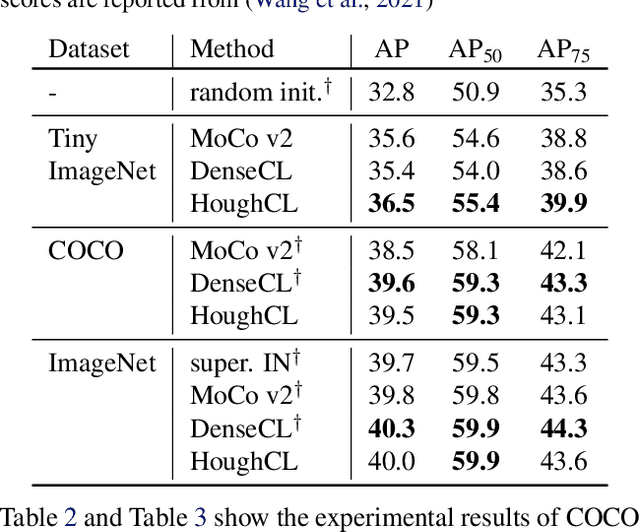
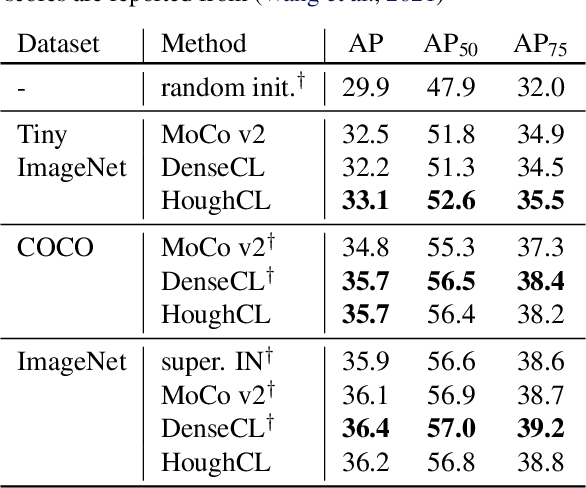
Recently, self-supervised methods show remarkable achievements in image-level representation learning. Nevertheless, their image-level self-supervisions lead the learned representation to sub-optimal for dense prediction tasks, such as object detection, instance segmentation, etc. To tackle this issue, several recent self-supervised learning methods have extended image-level single embedding to pixel-level dense embeddings. Unlike image-level representation learning, due to the spatial deformation of augmentation, it is difficult to sample pixel-level positive pairs. Previous studies have sampled pixel-level positive pairs using the winner-takes-all among similarity or thresholding warped distance between dense embeddings. However, these naive methods can be struggled by background clutter and outliers problems. In this paper, we introduce Hough Contrastive Learning (HoughCL), a Hough space based method that enforces geometric consistency between two dense features. HoughCL achieves robustness against background clutter and outliers. Furthermore, compared to baseline, our dense positive pairing method has no additional learnable parameters and has a small extra computation cost. Compared to previous works, our method shows better or comparable performance on dense prediction fine-tuning tasks.
Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Experts
Apr 02, 2021
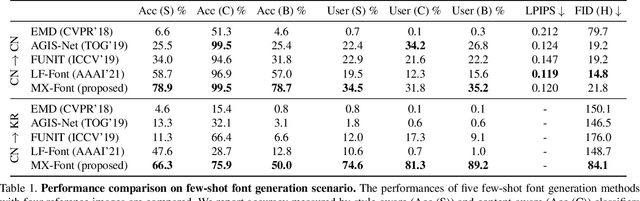
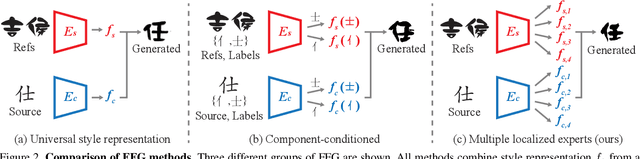

A few-shot font generation (FFG) method has to satisfy two objectives: the generated images should preserve the underlying global structure of the target character and present the diverse local reference style. Existing FFG methods aim to disentangle content and style either by extracting a universal representation style or extracting multiple component-wise style representations. However, previous methods either fail to capture diverse local styles or cannot be generalized to a character with unseen components, e.g., unseen language systems. To mitigate the issues, we propose a novel FFG method, named Multiple Localized Experts Few-shot Font Generation Network (MX-Font). MX-Font extracts multiple style features not explicitly conditioned on component labels, but automatically by multiple experts to represent different local concepts, e.g., left-side sub-glyph. Owing to the multiple experts, MX-Font can capture diverse local concepts and show the generalizability to unseen languages. During training, we utilize component labels as weak supervision to guide each expert to be specialized for different local concepts. We formulate the component assign problem to each expert as the graph matching problem, and solve it by the Hungarian algorithm. We also employ the independence loss and the content-style adversarial loss to impose the content-style disentanglement. In our experiments, MX-Font outperforms previous state-of-the-art FFG methods in the Chinese generation and cross-lingual, e.g., Chinese to Korean, generation. Source code is available at https://github.com/clovaai/mxfont.
Domain Generalization Needs Stochastic Weight Averaging for Robustness on Domain Shifts
Feb 17, 2021
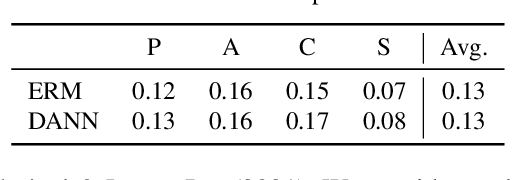
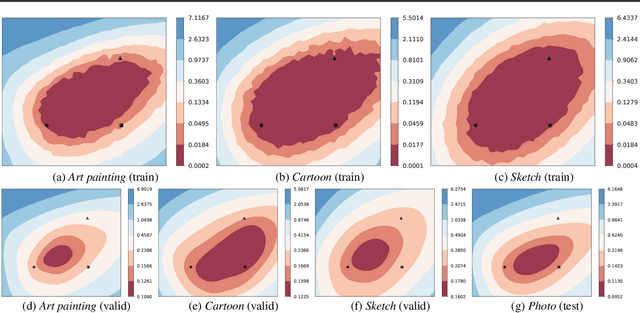
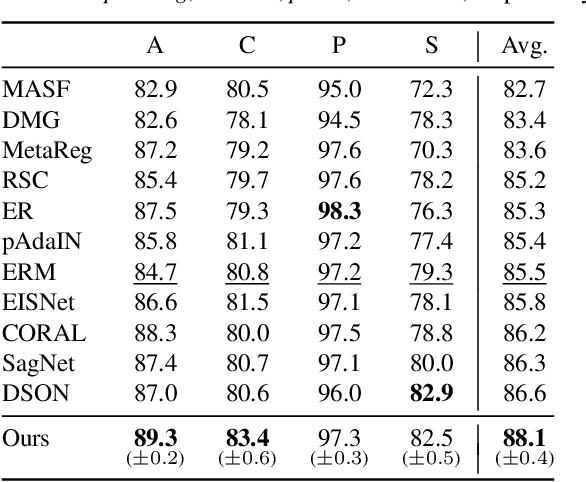
Domain generalization aims to learn a generalizable model to unseen target domains from multiple source domains. Various approaches have been proposed to address this problem. However, recent benchmarks show that most of them do not provide significant improvements compared to the simple empirical risk minimization (ERM) in practical cases. In this paper, we analyze how ERM works in views of domain-invariant feature learning and domain-specific gradient normalization. In addition, we observe that ERM converges to a loss valley shared over multiple training domains and obtain an insight that a center of the valley generalizes better. To estimate the center, we employ stochastic weight averaging (SWA) and provide theoretical analysis describing how SWA supports the generalization bound for an unseen domain. As a result, we achieve state-of-the-art performances over all of widely used domain generalization benchmarks, namely PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet with large margins. Further analysis reveals how SWA operates on domain generalization tasks.
Few-shot Font Generation with Localized Style Representations and Factorization
Sep 23, 2020
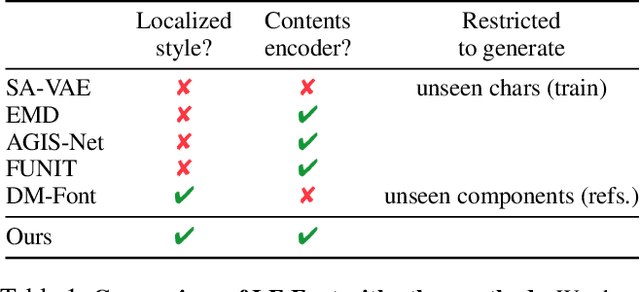
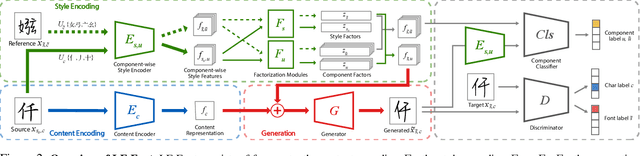
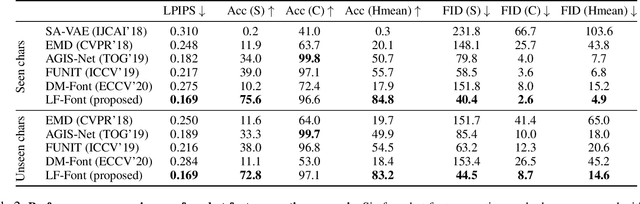
Automatic few-shot font generation is in high demand because manual designs are expensive and sensitive to the expertise of designers. Existing few-shot font generation methods aim to learn to disentangle the style and content element from a few reference glyphs, and mainly focus on a universal style representation for each font style. However, such approach limits the model in representing diverse local styles, and thus makes it unsuitable to the most complicated letter system, e.g., Chinese, whose characters consist of a varying number of components (often called "radical") with a highly complex structure. In this paper, we propose a novel font generation method by learning localized styles, namely component-wise style representations, instead of universal styles. The proposed style representations enable us to synthesize complex local details in text designs. However, learning component-wise styles solely from reference glyphs is infeasible in the few-shot font generation scenario, when a target script has a large number of components, e.g., over 200 for Chinese. To reduce the number of reference glyphs, we simplify component-wise styles by a product of component factor and style factor, inspired by low-rank matrix factorization. Thanks to the combination of strong representation and a compact factorization strategy, our method shows remarkably better few-shot font generation results (with only 8 reference glyph images) than other state-of-the-arts, without utilizing strong locality supervision, e.g., location of each component, skeleton, or strokes. The source code is available at https://github.com/clovaai/lffont.
Few-shot Compositional Font Generation with Dual Memory
May 21, 2020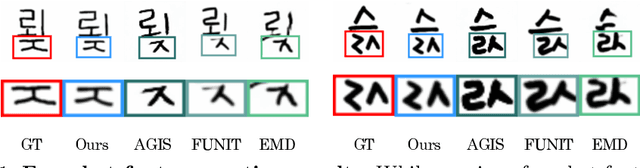
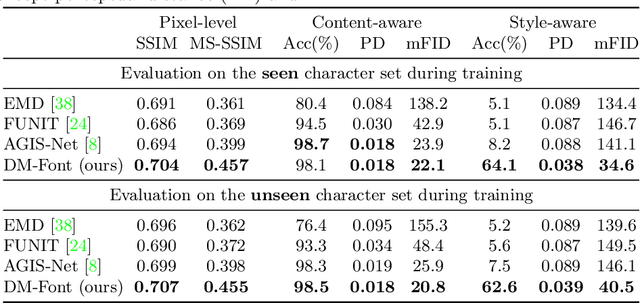
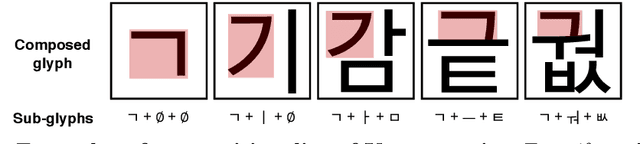
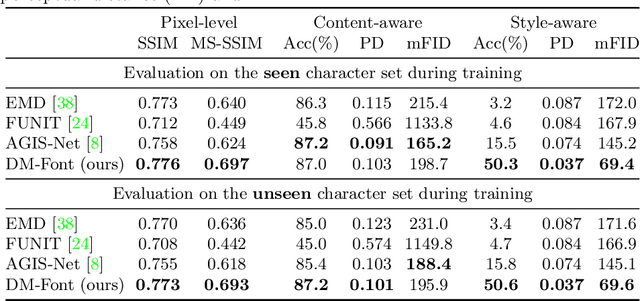
Generating a new font library is a very labor-intensive and time-consuming job for glyph-rich scripts. Despite the remarkable success of existing font generation methods, they have significant drawbacks; they require a large number of reference images to generate a new font set, or they fail to capture detailed styles with a few samples. In this paper, we focus on compositional scripts, a widely used letter system in the world, where each glyph can be decomposed by several components. By utilizing the compositionality of compositional scripts, we propose a novel font generation framework, named Dual Memory-augmented Font Generation Network (DM-Font), which enables us to generate a high-quality font library with only a few samples. We employ memory components and global-context awareness in the generator to take advantage of the compositionality. In the experiments on Korean-handwriting fonts and Thai-printing fonts, we observe that our method generates a significantly better quality of samples with faithful stylization compared to the state-of-the-art generation methods in quantitatively and qualitatively.