 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoughCL: Finding Better Positive Pairs in Dense Self-supervised Learning
Paper and Code
Nov 21, 2021
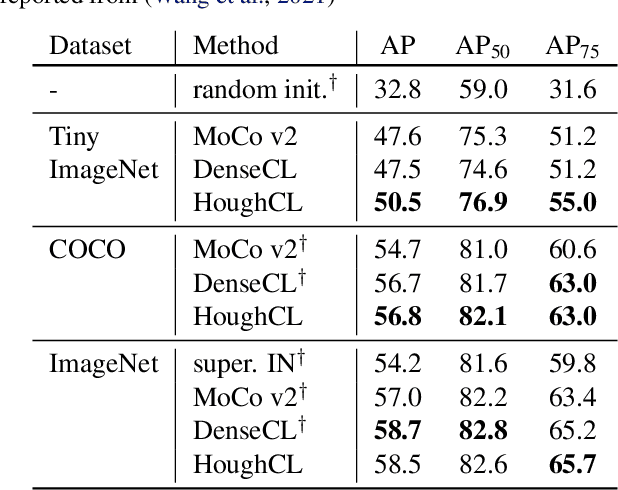
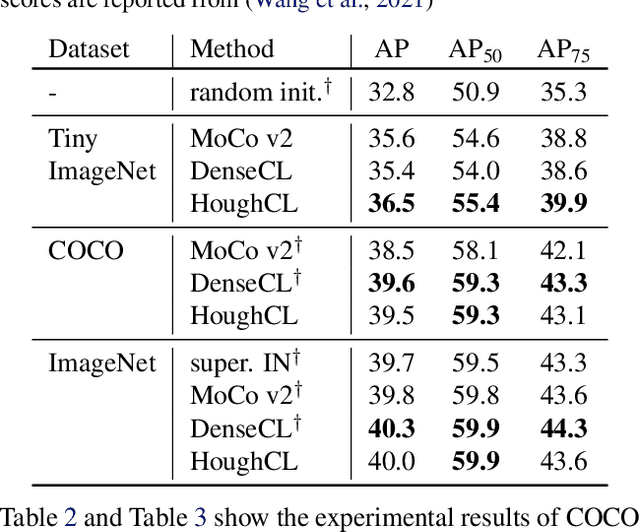
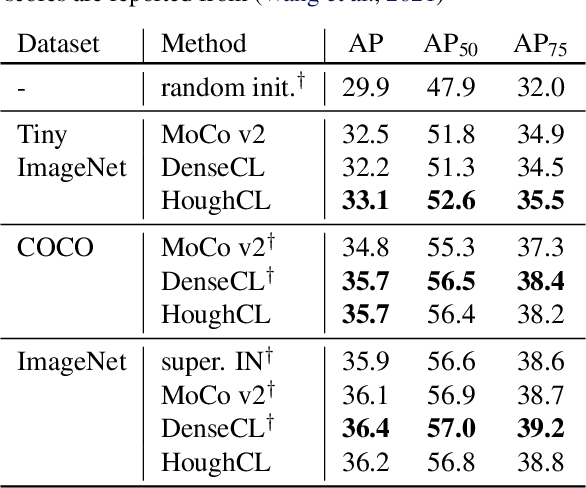
Recently, self-supervised methods show remarkable achievements in image-level representation learning. Nevertheless, their image-level self-supervisions lead the learned representation to sub-optimal for dense prediction tasks, such as object detection, instance segmentation, etc. To tackle this issue, several recent self-supervised learning methods have extended image-level single embedding to pixel-level dense embeddings. Unlike image-level representation learning, due to the spatial deformation of augmentation, it is difficult to sample pixel-level positive pairs. Previous studies have sampled pixel-level positive pairs using the winner-takes-all among similarity or thresholding warped distance between dense embeddings. However, these naive methods can be struggled by background clutter and outliers problems. In this paper, we introduce Hough Contrastive Learning (HoughCL), a Hough space based method that enforces geometric consistency between two dense features. HoughCL achieves robustness against background clutter and outliers. Furthermore, compared to baseline, our dense positive pairing method has no additional learnable parameters and has a small extra computation cost. Compared to previous works, our method shows better or comparable performance on dense prediction fine-tuning tasks.