 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
Mar 17, 2026Recent advances in video diffusion transformers have enabled interactive gaming world models that allow users to explore generated environments over extended horizons. However, existing approaches struggle with precise action control and long-horizon 3D consistency. Most prior works treat user actions as abstract conditioning signals, overlooking the fundamental geometric coupling between actions and the 3D world, whereby actions induce relative camera motions that accumulate into a global camera pose within a 3D world. In this paper, we establish camera pose as a unifying geometric representation to jointly ground immediate action control and long-term 3D consistency. First, we define a physics-based continuous action space and represent user inputs in the Lie algebra to derive precise 6-DoF camera poses, which are injected into the generative model via a camera embedder to ensure accurate action alignment. Second, we use global camera poses as spatial indices to retrieve relevant past observations, enabling geometrically consistent revisiting of locations during long-horizon navigation. To support this research, we introduce a large-scale dataset comprising 3,000 minutes of authentic human gameplay annotated with camera trajectories and textual descriptions. Extensive experiments show that our approach substantially outperforms state-of-the-art interactive gaming world models in action controllability, long-horizon visual quality, and 3D spatial consistency.
vla-eval: A Unified Evaluation Harness for Vision-Language-Action Models
Mar 14, 2026Vision Language Action VLA models are typically evaluated using per benchmark scripts maintained independently by each model repository, leading to duplicated code, dependency conflicts, and underspecified protocols. We present vla eval, an open source evaluation harness that decouples model inference from benchmark execution through a WebSocket msgpack protocol with Docker based environment isolation. Models integrate once by implementing a single predict() method; benchmarks integrate once via a four method interface; the full cross evaluation matrix works automatically. A complete evaluation requires only two commands: vla eval serve and vla eval run. The framework supports 13 simulation benchmarks and six model servers. Parallel evaluation via episode sharding and batch inference achieves a 47x throughput improvement, completing 2000 LIBERO episodes in about 18 minutes. Using this infrastructure, we conduct a reproducibility audit of a published VLA model across three benchmarks, finding that all three closely reproduce published values while uncovering undocumented requirements ambiguous termination semantics and hidden normalization statistics that can silently distort results. We additionally release a VLA leaderboard aggregating 657 published results across 17 benchmarks. Framework, evaluation configs, and all reproduction results are publicly available.
Multi-Architecture Multi-Expert Diffusion Models
Jun 08, 2023



Diffusion models have achieved impressive results in generating diverse and realistic data by employing multi-step denoising processes. However, the need for accommodating significant variations in input noise at each time-step has led to diffusion models requiring a large number of parameters for their denoisers. We have observed that diffusion models effectively act as filters for different frequency ranges at each time-step noise. While some previous works have introduced multi-expert strategies, assigning denoisers to different noise intervals, they overlook the importance of specialized operations for high and low frequencies. For instance, self-attention operations are effective at handling low-frequency components (low-pass filters), while convolutions excel at capturing high-frequency features (high-pass filters). In other words, existing diffusion models employ denoisers with the same architecture, without considering the optimal operations for each time-step noise. To address this limitation, we propose a novel approach called Multi-architecturE Multi-Expert (MEME), which consists of multiple experts with specialized architectures tailored to the operations required at each time-step interval. Through extensive experiments, we demonstrate that MEME outperforms large competitors in terms of both generation performance and computational efficiency.
ScoreCL: Augmentation-Adaptive Contrastive Learning via Score-Matching Function
Jun 07, 2023Self-supervised contrastive learning (CL) has achieved state-of-the-art performance in representation learning by minimizing the distance between positive pairs while maximizing that of negative ones. Recently, it has been verified that the model learns better representation with diversely augmented positive pairs because they enable the model to be more view-invariant. However, only a few studies on CL have considered the difference between augmented views, and have not gone beyond the hand-crafted findings. In this paper, we first observe that the score-matching function can measure how much data has changed from the original through augmentation. With the observed property, every pair in CL can be weighted adaptively by the difference of score values, resulting in boosting the performance of the existing CL method. We show the generality of our method, referred to as ScoreCL, by consistently improving various CL methods, SimCLR, SimSiam, W-MSE, and VICReg, up to 3%p in k-NN evaluation on CIFAR-10, CIFAR-100, and ImageNet-100. Moreover, we have conducted exhaustive experiments and ablations, including results on diverse downstream tasks, comparison with possible baselines, and improvement when used with other proposed augmentation methods. We hope our exploration will inspire more research in exploiting the score matching for CL.
Addressing Negative Transfer in Diffusion Models
Jun 01, 2023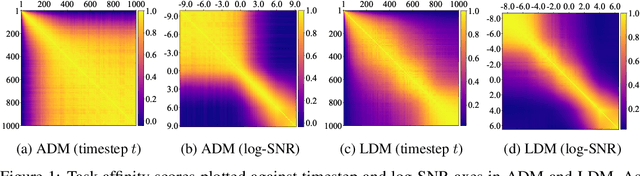
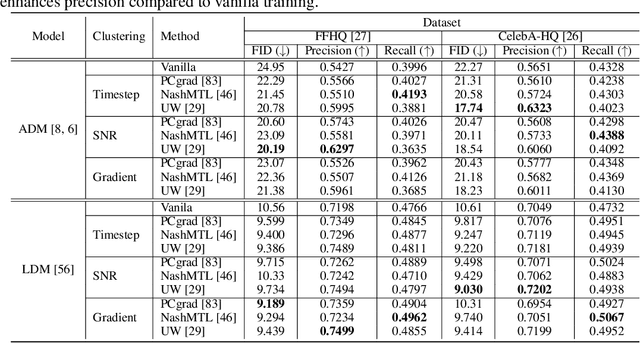
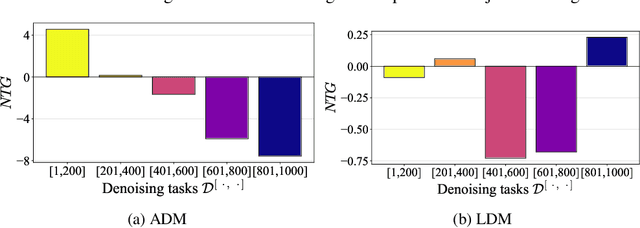

Diffusion-based generative models have achieved remarkable success in various domains. It trains a model on denoising tasks that encompass different noise levels simultaneously, representing a form of multi-task learning (MTL). However, analyzing and improving diffusion models from an MTL perspective remains under-explored. In particular, MTL can sometimes lead to the well-known phenomenon of $\textit{negative transfer}$, which results in the performance degradation of certain tasks due to conflicts between tasks. In this paper, we aim to analyze diffusion training from an MTL standpoint, presenting two key observations: $\textbf{(O1)}$ the task affinity between denoising tasks diminishes as the gap between noise levels widens, and $\textbf{(O2)}$ negative transfer can arise even in the context of diffusion training. Building upon these observations, our objective is to enhance diffusion training by mitigating negative transfer. To achieve this, we propose leveraging existing MTL methods, but the presence of a huge number of denoising tasks makes this computationally expensive to calculate the necessary per-task loss or gradient. To address this challenge, we propose clustering the denoising tasks into small task clusters and applying MTL methods to them. Specifically, based on $\textbf{(O2)}$, we employ interval clustering to enforce temporal proximity among denoising tasks within clusters. We show that interval clustering can be solved with dynamic programming and utilize signal-to-noise ratio, timestep, and task affinity for clustering objectives. Through this, our approach addresses the issue of negative transfer in diffusion models by allowing for efficient computation of MTL methods. We validate the proposed clustering and its integration with MTL methods through various experiments, demonstrating improved sample quality of diffusion models.
Cross Encoding as Augmentation: Towards Effective Educational Text Classification
May 31, 2023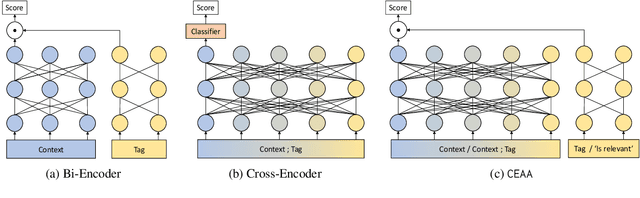
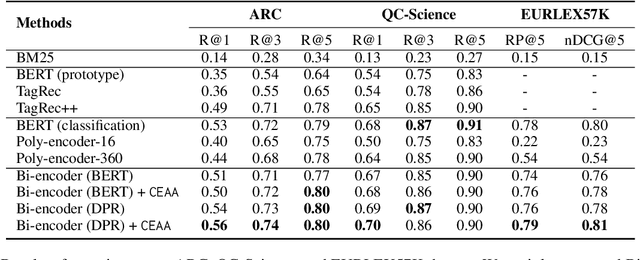
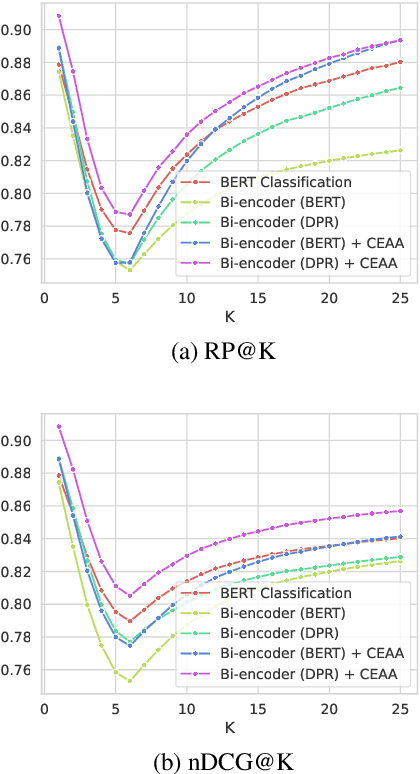
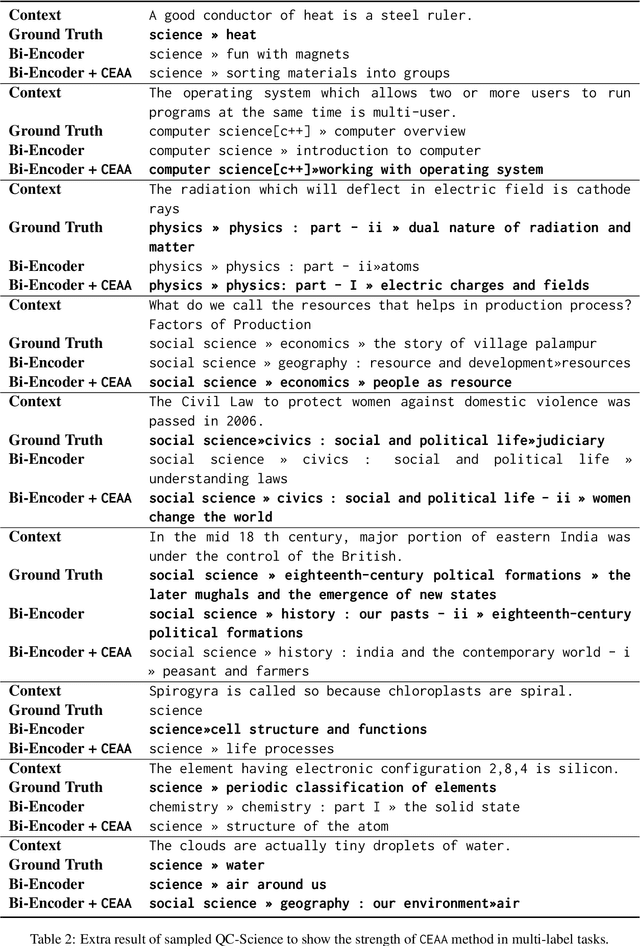
Text classification in education, usually called auto-tagging, is the automated process of assigning relevant tags to educational content, such as questions and textbooks. However, auto-tagging suffers from a data scarcity problem, which stems from two major challenges: 1) it possesses a large tag space and 2) it is multi-label. Though a retrieval approach is reportedly good at low-resource scenarios, there have been fewer efforts to directly address the data scarcity problem. To mitigate these issues, here we propose a novel retrieval approach CEAA that provides effective learning in educational text classification. Our main contributions are as follows: 1) we leverage transfer learning from question-answering datasets, and 2) we propose a simple but effective data augmentation method introducing cross-encoder style texts to a bi-encoder architecture for more efficient inference. An extensive set of experiments shows that our proposed method is effective in multi-label scenarios and low-resource tags compared to state-of-the-art models.
Evaluation of Question Generation Needs More References
May 26, 2023Question generation (QG) is the task of generating a valid and fluent question based on a given context and the target answer. According to various purposes, even given the same context, instructors can ask questions about different concepts, and even the same concept can be written in different ways. However, the evaluation for QG usually depends on single reference-based similarity metrics, such as n-gram-based metric or learned metric, which is not sufficient to fully evaluate the potential of QG methods. To this end, we propose to paraphrase the reference question for a more robust QG evaluation. Using large language models such as GPT-3, we created semantically and syntactically diverse questions, then adopt the simple aggregation of the popular evaluation metrics as the final scores. Through our experiments, we found that using multiple (pseudo) references is more effective for QG evaluation while showing a higher correlation with human evaluations than evaluation with a single reference.
Towards Practical Plug-and-Play Diffusion Models
Dec 12, 2022
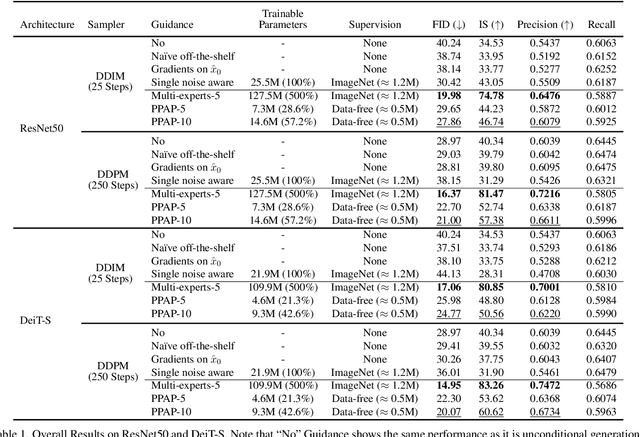


Diffusion-based generative models have achieved remarkable success in image generation. Their guidance formulation allows an external model to plug-and-play control the generation process for various tasks without fine-tuning the diffusion model. However, the direct use of publicly available off-the-shelf models for guidance fails due to their poor performance on noisy inputs. For that, the existing practice is to fine-tune the guidance models with labeled data corrupted with noises. In this paper, we argue that this practice has limitations in two aspects: (1) performing on inputs with extremely various noises is too hard for a single model; (2) collecting labeled datasets hinders scaling up for various tasks. To tackle the limitations, we propose a novel strategy that leverages multiple experts where each expert is specialized in a particular noise range and guides the reverse process at its corresponding timesteps. However, as it is infeasible to manage multiple networks and utilize labeled data, we present a practical guidance framework termed Practical Plug-And-Play (PPAP), which leverages parameter-efficient fine-tuning and data-free knowledge transfer. We exhaustively conduct ImageNet class conditional generation experiments to show that our method can successfully guide diffusion with small trainable parameters and no labeled data. Finally, we show that image classifiers, depth estimators, and semantic segmentation models can guide publicly available GLIDE through our framework in a plug-and-play manner.
Towards Flexible Inductive Bias via Progressive Reparameterization Scheduling
Oct 04, 2022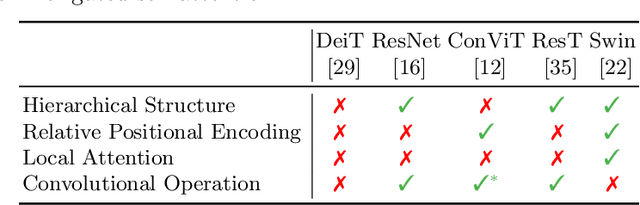
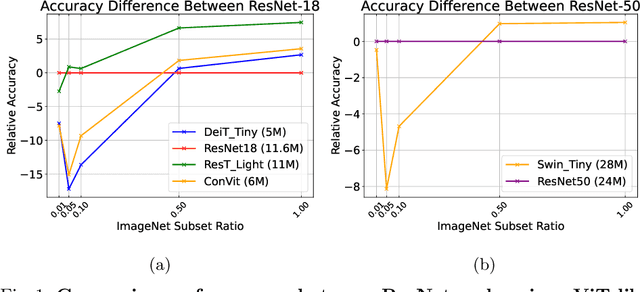
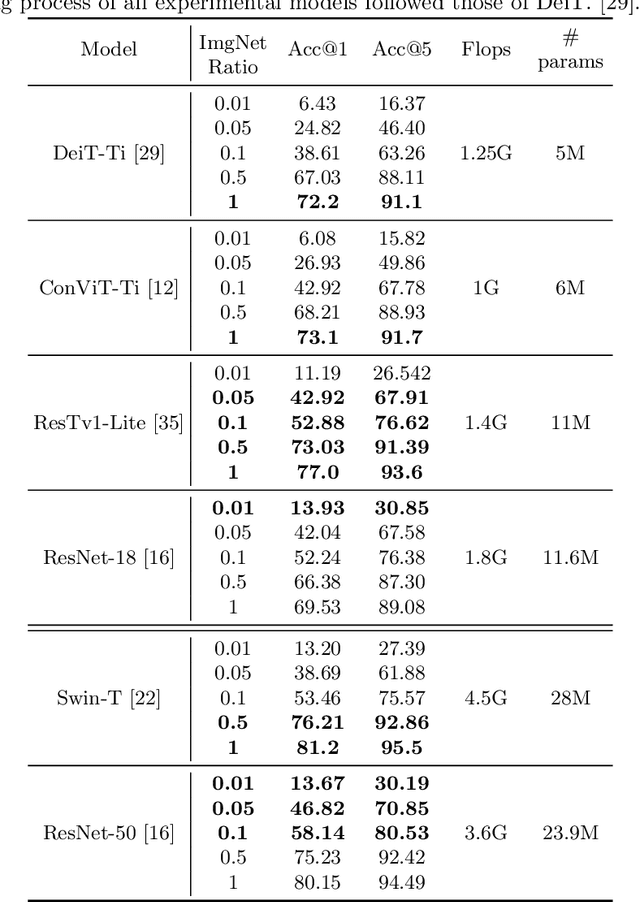
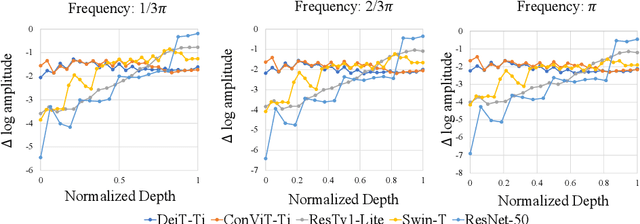
There are two de facto standard architectures in recent computer vision: Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). Strong inductive biases of convolutions help the model learn sample effectively, but such strong biases also limit the upper bound of CNNs when sufficient data are available. On the contrary, ViT is inferior to CNNs for small data but superior for sufficient data. Recent approaches attempt to combine the strengths of these two architectures. However, we show these approaches overlook that the optimal inductive bias also changes according to the target data scale changes by comparing various models' accuracy on subsets of sampled ImageNet at different ratios. In addition, through Fourier analysis of feature maps, the model's response patterns according to signal frequency changes, we observe which inductive bias is advantageous for each data scale. The more convolution-like inductive bias is included in the model, the smaller the data scale is required where the ViT-like model outperforms the ResNet performance. To obtain a model with flexible inductive bias on the data scale, we show reparameterization can interpolate inductive bias between convolution and self-attention. By adjusting the number of epochs the model stays in the convolution, we show that reparameterization from convolution to self-attention interpolates the Fourier analysis pattern between CNNs and ViTs. Adapting these findings, we propose Progressive Reparameterization Scheduling (PRS), in which reparameterization adjusts the required amount of convolution-like or self-attention-like inductive bias per layer. For small-scale datasets, our PRS performs reparameterization from convolution to self-attention linearly faster at the late stage layer. PRS outperformed previous studies on the small-scale dataset, e.g., CIFAR-100.
HoughCL: Finding Better Positive Pairs in Dense Self-supervised Learning
Nov 21, 2021
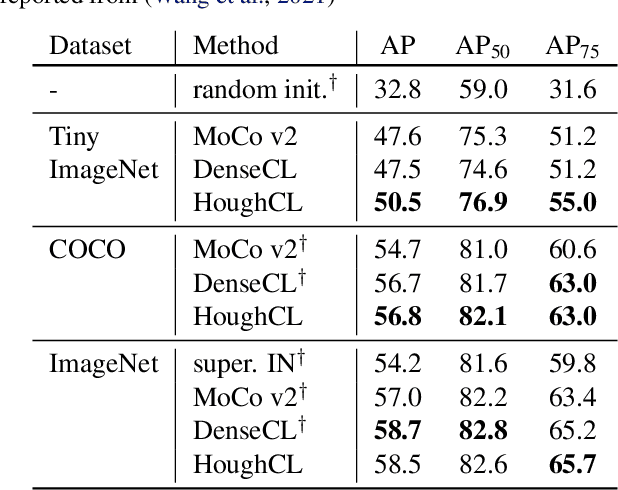
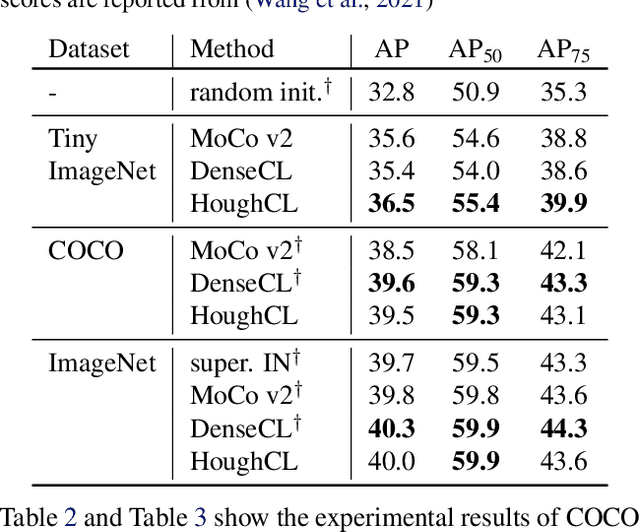
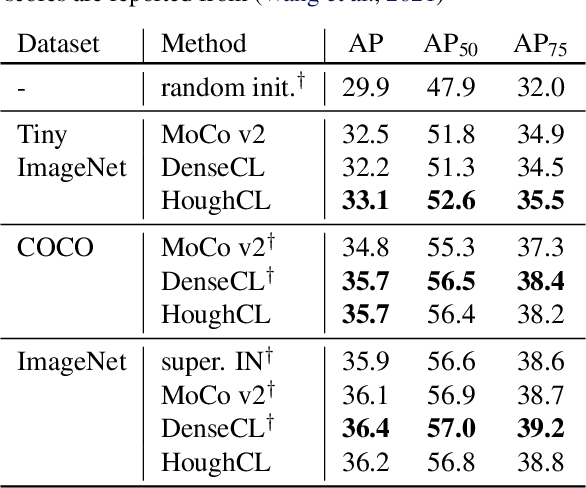
Recently, self-supervised methods show remarkable achievements in image-level representation learning. Nevertheless, their image-level self-supervisions lead the learned representation to sub-optimal for dense prediction tasks, such as object detection, instance segmentation, etc. To tackle this issue, several recent self-supervised learning methods have extended image-level single embedding to pixel-level dense embeddings. Unlike image-level representation learning, due to the spatial deformation of augmentation, it is difficult to sample pixel-level positive pairs. Previous studies have sampled pixel-level positive pairs using the winner-takes-all among similarity or thresholding warped distance between dense embeddings. However, these naive methods can be struggled by background clutter and outliers problems. In this paper, we introduce Hough Contrastive Learning (HoughCL), a Hough space based method that enforces geometric consistency between two dense features. HoughCL achieves robustness against background clutter and outliers. Furthermore, compared to baseline, our dense positive pairing method has no additional learnable parameters and has a small extra computation cost. Compared to previous works, our method shows better or comparable performance on dense prediction fine-tuning tasks.