 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Safety of Graph Representation Learning
May 07, 2026Graph representation learning (GRL) has evolved from topology-only graph embeddings to task-specific supervised GNNs, and more recently to reusable representations and graph foundation models (GFMs). However, existing evaluations mainly measure clean transfer, adaptation, and task coverage. It remains unclear whether GRL methods stay reliable when deployment stresses affect graph signals, graph contexts, label support, structural groups, or predictive evidence. We introduce GRL-Safety, a multi-axis safety evaluation benchmark for GRL. GRL-Safety evaluates twelve representative methods, spanning topology-only embedding methods, supervised GNNs, self-supervised graph models, and GFMs, on twenty-five graph datasets under standardized evaluation conditions while preserving method-native adaptation. The evaluation covers five safety axes: corruption robustness, OOD generalization, class imbalance, fairness, and interpretation, with per-axis and sub-condition reporting rather than a single aggregate score. Our analysis yields three cross-axis insights that can inspire future research. First, safety behavior is shaped by the interaction between representation design and the stressed graph factor, rather than by method family alone. Second, foundation-era methods show axis-specific strengths rather than broad safety dominance. Third, several deployment regimes remain difficult even for the best evaluated method, revealing capability gaps that require new robustness, adaptation, or training objectives beyond model selection. The benchmark, evaluation protocols, and code are available at: https://github.com/GXG-CS/GRL-Safety.
Toward Stable World Models: Measuring and Addressing World Instability in Generative Environments
Mar 11, 2025

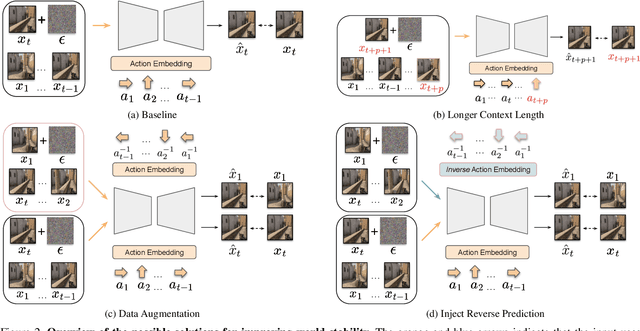

We present a novel study on enhancing the capability of preserving the content in world models, focusing on a property we term World Stability. Recent diffusion-based generative models have advanced the synthesis of immersive and realistic environments that are pivotal for applications such as reinforcement learning and interactive game engines. However, while these models excel in quality and diversity, they often neglect the preservation of previously generated scenes over time--a shortfall that can introduce noise into agent learning and compromise performance in safety-critical settings. In this work, we introduce an evaluation framework that measures world stability by having world models perform a sequence of actions followed by their inverses to return to their initial viewpoint, thereby quantifying the consistency between the starting and ending observations. Our comprehensive assessment of state-of-the-art diffusion-based world models reveals significant challenges in achieving high world stability. Moreover, we investigate several improvement strategies to enhance world stability. Our results underscore the importance of world stability in world modeling and provide actionable insights for future research in this domain.
SplatFlow: Multi-View Rectified Flow Model for 3D Gaussian Splatting Synthesis
Nov 25, 2024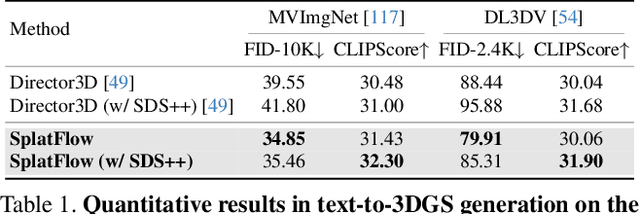


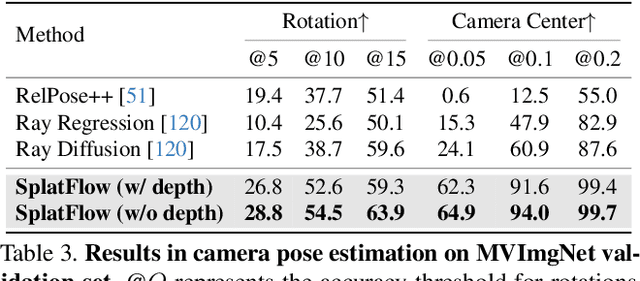
Text-based generation and editing of 3D scenes hold significant potential for streamlining content creation through intuitive user interactions. While recent advances leverage 3D Gaussian Splatting (3DGS) for high-fidelity and real-time rendering, existing methods are often specialized and task-focused, lacking a unified framework for both generation and editing. In this paper, we introduce SplatFlow, a comprehensive framework that addresses this gap by enabling direct 3DGS generation and editing. SplatFlow comprises two main components: a multi-view rectified flow (RF) model and a Gaussian Splatting Decoder (GSDecoder). The multi-view RF model operates in latent space, generating multi-view images, depths, and camera poses simultaneously, conditioned on text prompts, thus addressing challenges like diverse scene scales and complex camera trajectories in real-world settings. Then, the GSDecoder efficiently translates these latent outputs into 3DGS representations through a feed-forward 3DGS method. Leveraging training-free inversion and inpainting techniques, SplatFlow enables seamless 3DGS editing and supports a broad range of 3D tasks-including object editing, novel view synthesis, and camera pose estimation-within a unified framework without requiring additional complex pipelines. We validate SplatFlow's capabilities on the MVImgNet and DL3DV-7K datasets, demonstrating its versatility and effectiveness in various 3D generation, editing, and inpainting-based tasks.
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
BIPED: Pedagogically Informed Tutoring System for ESL Education
Jun 05, 2024
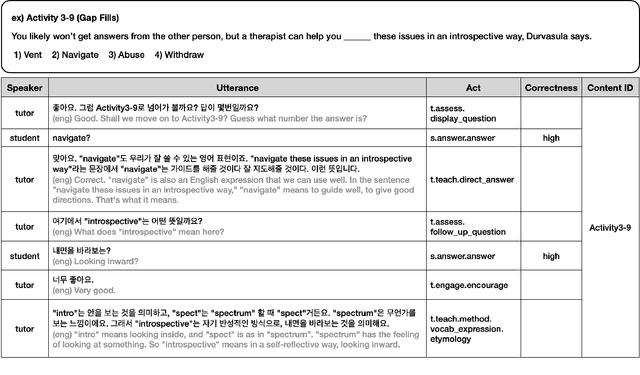


Large Language Models (LLMs) have a great potential to serve as readily available and cost-efficient Conversational Intelligent Tutoring Systems (CITS) for teaching L2 learners of English. Existing CITS, however, are designed to teach only simple concepts or lack the pedagogical depth necessary to address diverse learning strategies. To develop a more pedagogically informed CITS capable of teaching complex concepts, we construct a BIlingual PEDagogically-informed Tutoring Dataset (BIPED) of one-on-one, human-to-human English tutoring interactions. Through post-hoc analysis of the tutoring interactions, we come up with a lexicon of dialogue acts (34 tutor acts and 9 student acts), which we use to further annotate the collected dataset. Based on a two-step framework of first predicting the appropriate tutor act then generating the corresponding response, we implemented two CITS models using GPT-4 and SOLAR-KO, respectively. We experimentally demonstrate that the implemented models not only replicate the style of human teachers but also employ diverse and contextually appropriate pedagogical strategies.
Denoising Task Difficulty-based Curriculum for Training Diffusion Models
Mar 15, 2024



Diffusion-based generative models have emerged as powerful tools in the realm of generative modeling. Despite extensive research on denoising across various timesteps and noise levels, a conflict persists regarding the relative difficulties of the denoising tasks. While various studies argue that lower timesteps present more challenging tasks, others contend that higher timesteps are more difficult. To address this conflict, our study undertakes a comprehensive examination of task difficulties, focusing on convergence behavior and changes in relative entropy between consecutive probability distributions across timesteps. Our observational study reveals that denoising at earlier timesteps poses challenges characterized by slower convergence and higher relative entropy, indicating increased task difficulty at these lower timesteps. Building on these observations, we introduce an easy-to-hard learning scheme, drawing from curriculum learning, to enhance the training process of diffusion models. By organizing timesteps or noise levels into clusters and training models with descending orders of difficulty, we facilitate an order-aware training regime, progressing from easier to harder denoising tasks, thereby deviating from the conventional approach of training diffusion models simultaneously across all timesteps. Our approach leads to improved performance and faster convergence by leveraging the benefits of curriculum learning, while maintaining orthogonality with existing improvements in diffusion training techniques. We validate these advantages through comprehensive experiments in image generation tasks, including unconditional, class-conditional, and text-to-image generation.
Addressing Selection Bias in Computerized Adaptive Testing: A User-Wise Aggregate Influence Function Approach
Aug 23, 2023



Computerized Adaptive Testing (CAT) is a widely used, efficient test mode that adapts to the examinee's proficiency level in the test domain. CAT requires pre-trained item profiles, for CAT iteratively assesses the student real-time based on the registered items' profiles, and selects the next item to administer using candidate items' profiles. However, obtaining such item profiles is a costly process that involves gathering a large, dense item-response data, then training a diagnostic model on the collected data. In this paper, we explore the possibility of leveraging response data collected in the CAT service. We first show that this poses a unique challenge due to the inherent selection bias introduced by CAT, i.e., more proficient students will receive harder questions. Indeed, when naively training the diagnostic model using CAT response data, we observe that item profiles deviate significantly from the ground-truth. To tackle the selection bias issue, we propose the user-wise aggregate influence function method. Our intuition is to filter out users whose response data is heavily biased in an aggregate manner, as judged by how much perturbation the added data will introduce during parameter estimation. This way, we may enhance the performance of CAT while introducing minimal bias to the item profiles. We provide extensive experiments to demonstrate the superiority of our proposed method based on the three public datasets and one dataset that contains real-world CAT response data.
ScoreCL: Augmentation-Adaptive Contrastive Learning via Score-Matching Function
Jun 07, 2023Self-supervised contrastive learning (CL) has achieved state-of-the-art performance in representation learning by minimizing the distance between positive pairs while maximizing that of negative ones. Recently, it has been verified that the model learns better representation with diversely augmented positive pairs because they enable the model to be more view-invariant. However, only a few studies on CL have considered the difference between augmented views, and have not gone beyond the hand-crafted findings. In this paper, we first observe that the score-matching function can measure how much data has changed from the original through augmentation. With the observed property, every pair in CL can be weighted adaptively by the difference of score values, resulting in boosting the performance of the existing CL method. We show the generality of our method, referred to as ScoreCL, by consistently improving various CL methods, SimCLR, SimSiam, W-MSE, and VICReg, up to 3%p in k-NN evaluation on CIFAR-10, CIFAR-100, and ImageNet-100. Moreover, we have conducted exhaustive experiments and ablations, including results on diverse downstream tasks, comparison with possible baselines, and improvement when used with other proposed augmentation methods. We hope our exploration will inspire more research in exploiting the score matching for CL.