 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
Upright adjustment with graph convolutional networks
Jun 01, 2024We present a novel method for the upright adjustment of 360 images. Our network consists of two modules, which are a convolutional neural network (CNN) and a graph convolutional network (GCN). The input 360 images is processed with the CNN for visual feature extraction, and the extracted feature map is converted into a graph that finds a spherical representation of the input. We also introduce a novel loss function to address the issue of discrete probability distributions defined on the surface of a sphere. Experimental results demonstrate that our method outperforms fully connected based methods.
Pegasus-v1 Technical Report
Apr 23, 2024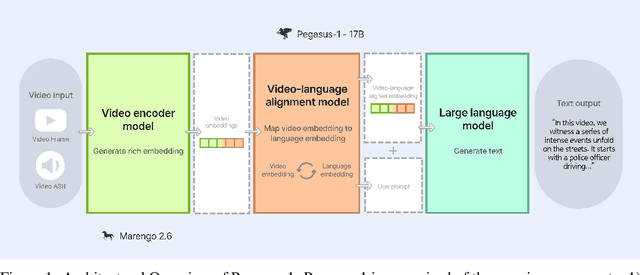
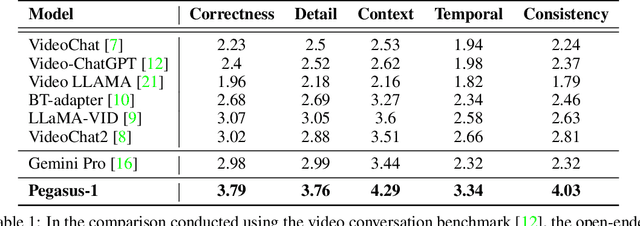


This technical report introduces Pegasus-1, a multimodal language model specialized in video content understanding and interaction through natural language. Pegasus-1 is designed to address the unique challenges posed by video data, such as interpreting spatiotemporal information, to offer nuanced video content comprehension across various lengths. This technical report overviews Pegasus-1's architecture, training strategies, and its performance in benchmarks on video conversation, zero-shot video question answering, and video summarization. We also explore qualitative characteristics of Pegasus-1 , demonstrating its capabilities as well as its limitations, in order to provide readers a balanced view of its current state and its future direction.
Spherical Transformer
Feb 11, 2022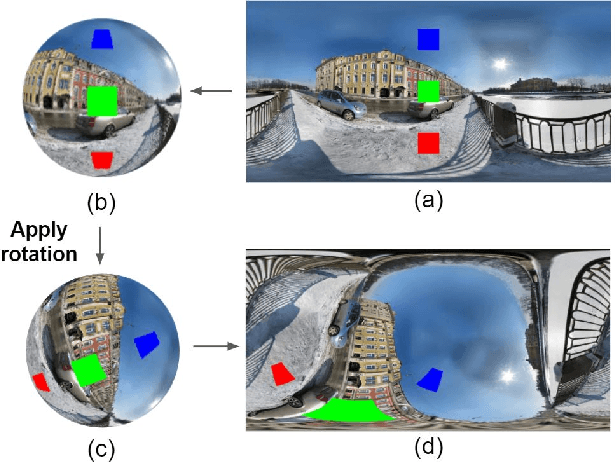
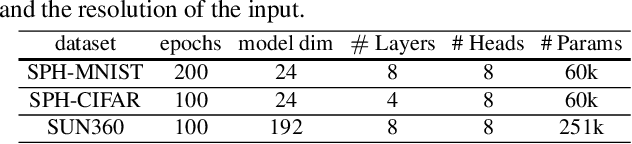
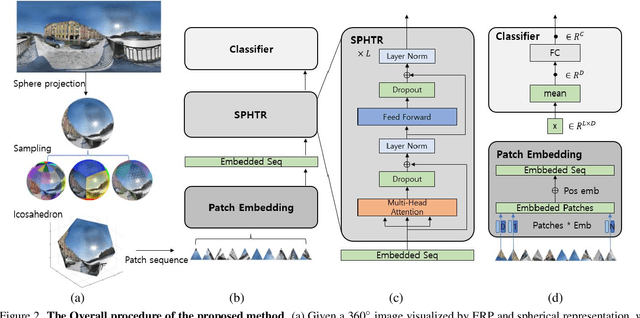
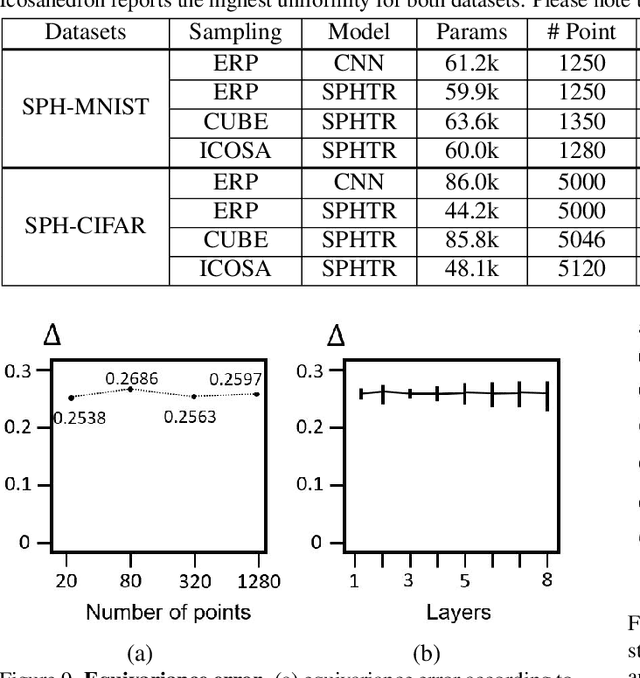
Using convolutional neural networks for 360images can induce sub-optimal performance due to distortions entailed by a planar projection. The distortion gets deteriorated when a rotation is applied to the 360image. Thus, many researches based on convolutions attempt to reduce the distortions to learn accurate representation. In contrast, we leverage the transformer architecture to solve image classification problems for 360images. Using the proposed transformer for 360images has two advantages. First, our method does not require the erroneous planar projection process by sampling pixels from the sphere surface. Second, our sampling method based on regular polyhedrons makes low rotation equivariance errors, because specific rotations can be reduced to permutations of faces. In experiments, we validate our network on two aspects, as follows. First, we show that using a transformer with highly uniform sampling methods can help reduce the distortion. Second, we demonstrate that the transformer architecture can achieve rotation equivariance on specific rotations. We compare our method to other state-of-the-art algorithms using the SPH-MNIST, SPH-CIFAR, and SUN360 datasets and show that our method is competitive with other methods.