 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-dimensional Preference Alignment by Conditioning Reward Itself
Dec 11, 2025Reinforcement Learning from Human Feedback has emerged as a standard for aligning diffusion models. However, we identify a fundamental limitation in the standard DPO formulation because it relies on the Bradley-Terry model to aggregate diverse evaluation axes like aesthetic quality and semantic alignment into a single scalar reward. This aggregation creates a reward conflict where the model is forced to unlearn desirable features of a specific dimension if they appear in a globally non-preferred sample. To address this issue, we propose Multi Reward Conditional DPO (MCDPO). This method resolves reward conflicts by introducing a disentangled Bradley-Terry objective. MCDPO explicitly injects a preference outcome vector as a condition during training, which allows the model to learn the correct optimization direction for each reward axis independently within a single network. We further introduce dimensional reward dropout to ensure balanced optimization across dimensions. Extensive experiments on Stable Diffusion 1.5 and SDXL demonstrate that MCDPO achieves superior performance on benchmarks. Notably, our conditional framework enables dynamic and multiple-axis control at inference time using Classifier Free Guidance to amplify specific reward dimensions without additional training or external reward models.
Understanding Differential Transformer Unchains Pretrained Self-Attentions
May 22, 2025Differential Transformer has recently gained significant attention for its impressive empirical performance, often attributed to its ability to perform noise canceled attention. However, precisely how differential attention achieves its empirical benefits remains poorly understood. Moreover, Differential Transformer architecture demands large-scale training from scratch, hindering utilization of open pretrained weights. In this work, we conduct an in-depth investigation of Differential Transformer, uncovering three key factors behind its success: (1) enhanced expressivity via negative attention, (2) reduced redundancy among attention heads, and (3) improved learning dynamics. Based on these findings, we propose DEX, a novel method to efficiently integrate the advantages of differential attention into pretrained language models. By reusing the softmax attention scores and adding a lightweight differential operation on the output value matrix, DEX effectively incorporates the key advantages of differential attention while remaining lightweight in both training and inference. Evaluations confirm that DEX substantially improves the pretrained LLMs across diverse benchmarks, achieving significant performance gains with minimal adaptation data (< 0.01\%).
SplatFlow: Multi-View Rectified Flow Model for 3D Gaussian Splatting Synthesis
Nov 25, 2024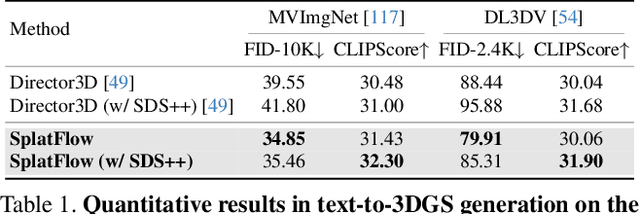


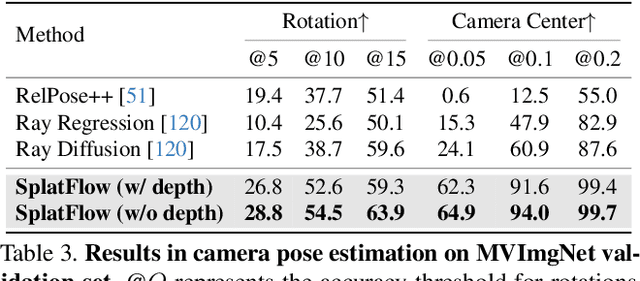
Text-based generation and editing of 3D scenes hold significant potential for streamlining content creation through intuitive user interactions. While recent advances leverage 3D Gaussian Splatting (3DGS) for high-fidelity and real-time rendering, existing methods are often specialized and task-focused, lacking a unified framework for both generation and editing. In this paper, we introduce SplatFlow, a comprehensive framework that addresses this gap by enabling direct 3DGS generation and editing. SplatFlow comprises two main components: a multi-view rectified flow (RF) model and a Gaussian Splatting Decoder (GSDecoder). The multi-view RF model operates in latent space, generating multi-view images, depths, and camera poses simultaneously, conditioned on text prompts, thus addressing challenges like diverse scene scales and complex camera trajectories in real-world settings. Then, the GSDecoder efficiently translates these latent outputs into 3DGS representations through a feed-forward 3DGS method. Leveraging training-free inversion and inpainting techniques, SplatFlow enables seamless 3DGS editing and supports a broad range of 3D tasks-including object editing, novel view synthesis, and camera pose estimation-within a unified framework without requiring additional complex pipelines. We validate SplatFlow's capabilities on the MVImgNet and DL3DV-7K datasets, demonstrating its versatility and effectiveness in various 3D generation, editing, and inpainting-based tasks.
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
Pegasus-v1 Technical Report
Apr 23, 2024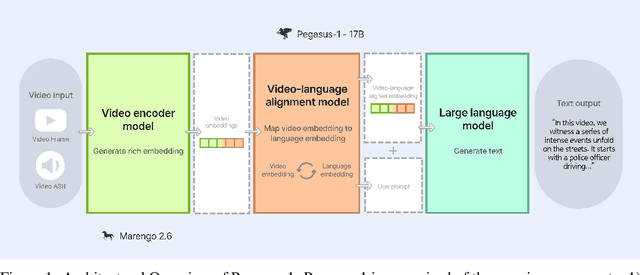
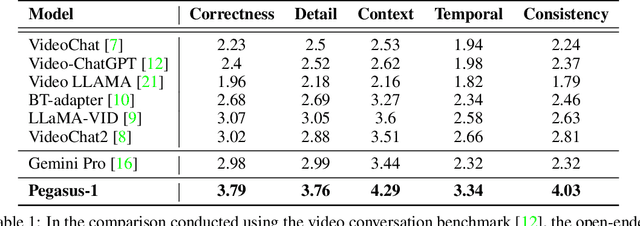


This technical report introduces Pegasus-1, a multimodal language model specialized in video content understanding and interaction through natural language. Pegasus-1 is designed to address the unique challenges posed by video data, such as interpreting spatiotemporal information, to offer nuanced video content comprehension across various lengths. This technical report overviews Pegasus-1's architecture, training strategies, and its performance in benchmarks on video conversation, zero-shot video question answering, and video summarization. We also explore qualitative characteristics of Pegasus-1 , demonstrating its capabilities as well as its limitations, in order to provide readers a balanced view of its current state and its future direction.
ConcatPlexer: Additional Dim1 Batching for Faster ViTs
Aug 22, 2023Transformers have demonstrated tremendous success not only in the natural language processing (NLP) domain but also the field of computer vision, igniting various creative approaches and applications. Yet, the superior performance and modeling flexibility of transformers came with a severe increase in computation costs, and hence several works have proposed methods to reduce this burden. Inspired by a cost-cutting method originally proposed for language models, Data Multiplexing (DataMUX), we propose a novel approach for efficient visual recognition that employs additional dim1 batching (i.e., concatenation) that greatly improves the throughput with little compromise in the accuracy. We first introduce a naive adaptation of DataMux for vision models, Image Multiplexer, and devise novel components to overcome its weaknesses, rendering our final model, ConcatPlexer, at the sweet spot between inference speed and accuracy. The ConcatPlexer was trained on ImageNet1K and CIFAR100 dataset and it achieved 23.5% less GFLOPs than ViT-B/16 with 69.5% and 83.4% validation accuracy, respectively.
Robust Natural Language Watermarking through Invariant Features
May 03, 2023Recent years have witnessed a proliferation of valuable original natural language contents found in subscription-based media outlets, web novel platforms, and outputs of large language models. Without proper security measures, however, these contents are susceptible to illegal piracy and potential misuse. This calls for a secure watermarking system to guarantee copyright protection through leakage tracing or ownership identification. To effectively combat piracy and protect copyrights, a watermarking framework should be able not only to embed adequate bits of information but also extract the watermarks in a robust manner despite possible corruption. In this work, we explore ways to advance both payload and robustness by following a well-known proposition from image watermarking and identify features in natural language that are invariant to minor corruption. Through a systematic analysis of the possible sources of errors, we further propose a corruption-resistant infill model. Our full method improves upon the previous work on robustness by +16.8% point on average on four datasets, three corruption types, and two corruption ratios. Code available at https://github.com/bangawayoo/nlp-watermarking.
Unifying Vision-Language Representation Space with Single-tower Transformer
Nov 21, 2022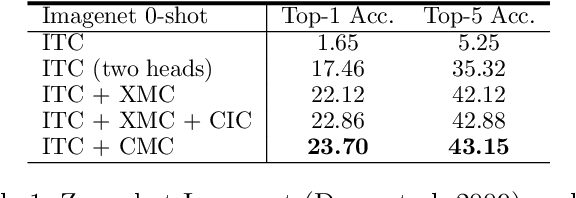
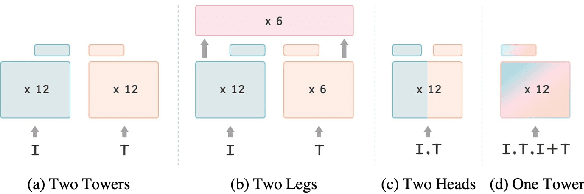
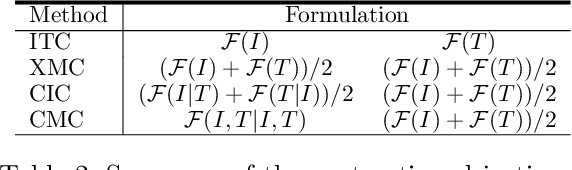

Contrastive learning is a form of distance learning that aims to learn invariant features from two related representations. In this paper, we explore the bold hypothesis that an image and its caption can be simply regarded as two different views of the underlying mutual information, and train a model to learn a unified vision-language representation space that encodes both modalities at once in a modality-agnostic manner. We first identify difficulties in learning a generic one-tower model for vision-language pretraining (VLP), and propose OneR as a simple yet effective framework for our goal. We discover intriguing properties that distinguish OneR from the previous works that learn modality-specific representation spaces such as zero-shot object localization, text-guided visual reasoning and multi-modal retrieval, and present analyses to provide insights into this new form of multi-modal representation learning. Thorough evaluations demonstrate the potential of a unified modality-agnostic VLP framework.
Detection of Word Adversarial Examples in Text Classification: Benchmark and Baseline via Robust Density Estimation
Mar 03, 2022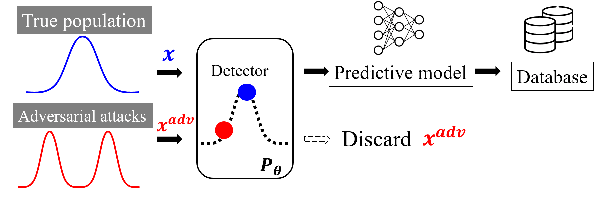
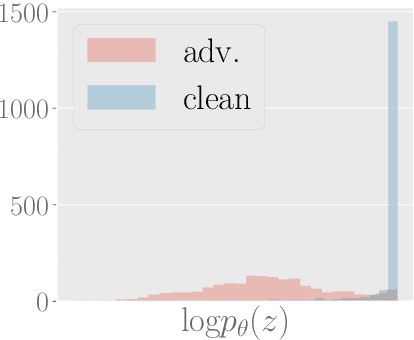

Word-level adversarial attacks have shown success in NLP models, drastically decreasing the performance of transformer-based models in recent years. As a countermeasure, adversarial defense has been explored, but relatively few efforts have been made to detect adversarial examples. However, detecting adversarial examples may be crucial for automated tasks (e.g. review sentiment analysis) that wish to amass information about a certain population and additionally be a step towards a robust defense system. To this end, we release a dataset for four popular attack methods on four datasets and four models to encourage further research in this field. Along with it, we propose a competitive baseline based on density estimation that has the highest AUC on 29 out of 30 dataset-attack-model combinations. Source code is available in https://github.com/anoymous92874838/text-adv-detection.
Self-Distilled Self-Supervised Representation Learning
Nov 25, 2021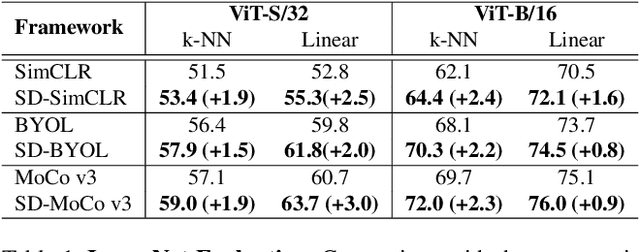
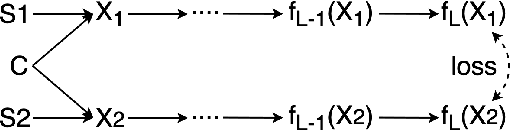
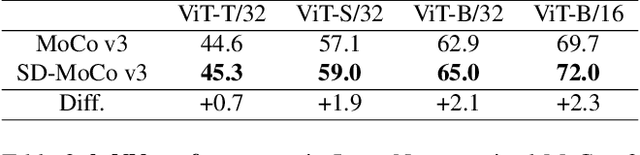
State-of-the-art frameworks in self-supervised learning have recently shown that fully utilizing transformer-based models can lead to performance boost compared to conventional CNN models. Thriving to maximize the mutual information of two views of an image, existing works apply a contrastive loss to the final representations. In our work, we further exploit this by allowing the intermediate representations to learn from the final layers via the contrastive loss, which is maximizing the upper bound of the original goal and the mutual information between two layers. Our method, Self-Distilled Self-Supervised Learning (SDSSL), outperforms competitive baselines (SimCLR, BYOL and MoCo v3) using ViT on various tasks and datasets. In the linear evaluation and k-NN protocol, SDSSL not only leads to superior performance in the final layers, but also in most of the lower layers. Furthermore, positive and negative alignments are used to explain how representations are formed more effectively. Code will be available.