 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Differential Transformer Unchains Pretrained Self-Attentions
May 22, 2025Differential Transformer has recently gained significant attention for its impressive empirical performance, often attributed to its ability to perform noise canceled attention. However, precisely how differential attention achieves its empirical benefits remains poorly understood. Moreover, Differential Transformer architecture demands large-scale training from scratch, hindering utilization of open pretrained weights. In this work, we conduct an in-depth investigation of Differential Transformer, uncovering three key factors behind its success: (1) enhanced expressivity via negative attention, (2) reduced redundancy among attention heads, and (3) improved learning dynamics. Based on these findings, we propose DEX, a novel method to efficiently integrate the advantages of differential attention into pretrained language models. By reusing the softmax attention scores and adding a lightweight differential operation on the output value matrix, DEX effectively incorporates the key advantages of differential attention while remaining lightweight in both training and inference. Evaluations confirm that DEX substantially improves the pretrained LLMs across diverse benchmarks, achieving significant performance gains with minimal adaptation data (< 0.01\%).
Fashion Style Editing with Generative Human Prior
Apr 02, 2024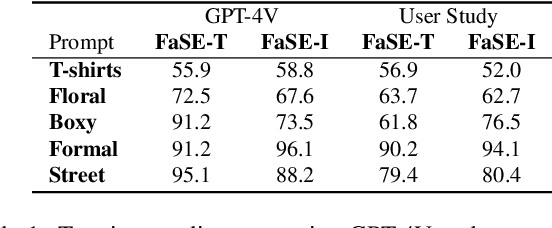
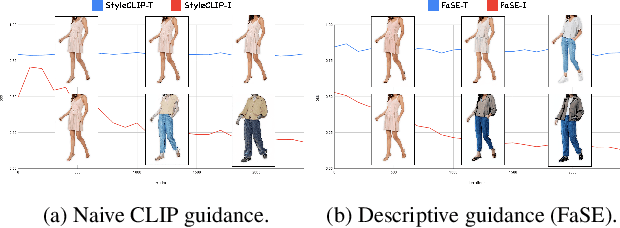
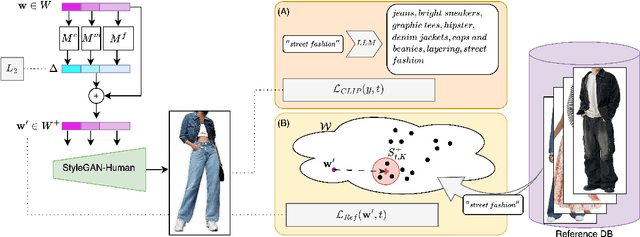
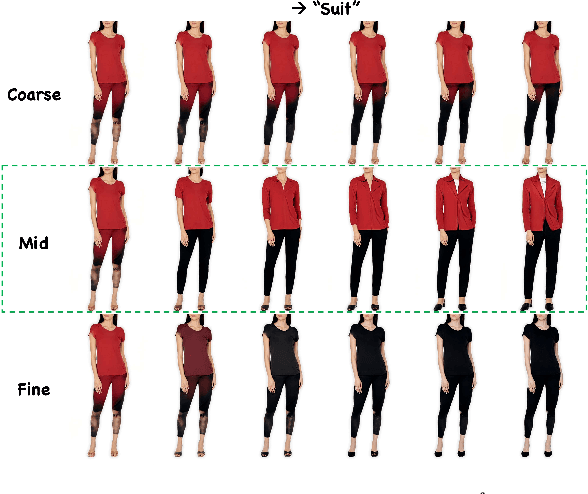
Image editing has been a long-standing challenge in the research community with its far-reaching impact on numerous applications. Recently, text-driven methods started to deliver promising results in domains like human faces, but their applications to more complex domains have been relatively limited. In this work, we explore the task of fashion style editing, where we aim to manipulate the fashion style of human imagery using text descriptions. Specifically, we leverage a generative human prior and achieve fashion style editing by navigating its learned latent space. We first verify that the existing text-driven editing methods fall short for our problem due to their overly simplified guidance signal, and propose two directions to reinforce the guidance: textual augmentation and visual referencing. Combined with our empirical findings on the latent space structure, our Fashion Style Editing framework (FaSE) successfully projects abstract fashion concepts onto human images and introduces exciting new applications to the field.
ConcatPlexer: Additional Dim1 Batching for Faster ViTs
Aug 22, 2023Transformers have demonstrated tremendous success not only in the natural language processing (NLP) domain but also the field of computer vision, igniting various creative approaches and applications. Yet, the superior performance and modeling flexibility of transformers came with a severe increase in computation costs, and hence several works have proposed methods to reduce this burden. Inspired by a cost-cutting method originally proposed for language models, Data Multiplexing (DataMUX), we propose a novel approach for efficient visual recognition that employs additional dim1 batching (i.e., concatenation) that greatly improves the throughput with little compromise in the accuracy. We first introduce a naive adaptation of DataMux for vision models, Image Multiplexer, and devise novel components to overcome its weaknesses, rendering our final model, ConcatPlexer, at the sweet spot between inference speed and accuracy. The ConcatPlexer was trained on ImageNet1K and CIFAR100 dataset and it achieved 23.5% less GFLOPs than ViT-B/16 with 69.5% and 83.4% validation accuracy, respectively.
AADiff: Audio-Aligned Video Synthesis with Text-to-Image Diffusion
May 06, 2023



Recent advances in diffusion models have showcased promising results in the text-to-video (T2V) synthesis task. However, as these T2V models solely employ text as the guidance, they tend to struggle in modeling detailed temporal dynamics. In this paper, we introduce a novel T2V framework that additionally employ audio signals to control the temporal dynamics, empowering an off-the-shelf T2I diffusion to generate audio-aligned videos. We propose audio-based regional editing and signal smoothing to strike a good balance between the two contradicting desiderata of video synthesis, i.e., temporal flexibility and coherence. We empirically demonstrate the effectiveness of our method through experiments, and further present practical applications for contents creation.
Analyzing Multimodal Objectives Through the Lens of Generative Diffusion Guidance
Feb 10, 2023Recent years have witnessed astonishing advances in the field of multimodal representation learning, with contrastive learning being the cornerstone for major breakthroughs. Latest works delivered further improvements by incorporating different objectives such as masked modeling and captioning into the frameworks, but our understanding on how these objectives facilitate learning remains vastly incomplete. In this paper, we leverage the fact that classifier-guided diffusion models generate images that reflect the semantic signals provided by the classifier to study the characteristics of multimodal learning objectives. Specifically, we compare contrastive, matching and captioning loss in terms of their semantic signals, and introduce a simple baseline that not only supports our analyses but also improves the quality of generative guidance in a straightforward manner.
Unifying Vision-Language Representation Space with Single-tower Transformer
Nov 21, 2022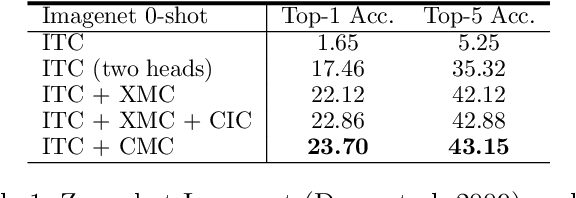
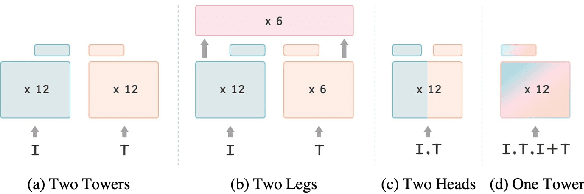
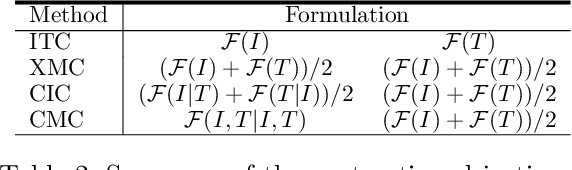

Contrastive learning is a form of distance learning that aims to learn invariant features from two related representations. In this paper, we explore the bold hypothesis that an image and its caption can be simply regarded as two different views of the underlying mutual information, and train a model to learn a unified vision-language representation space that encodes both modalities at once in a modality-agnostic manner. We first identify difficulties in learning a generic one-tower model for vision-language pretraining (VLP), and propose OneR as a simple yet effective framework for our goal. We discover intriguing properties that distinguish OneR from the previous works that learn modality-specific representation spaces such as zero-shot object localization, text-guided visual reasoning and multi-modal retrieval, and present analyses to provide insights into this new form of multi-modal representation learning. Thorough evaluations demonstrate the potential of a unified modality-agnostic VLP framework.
Leveraging Off-the-shelf Diffusion Model for Multi-attribute Fashion Image Manipulation
Oct 12, 2022
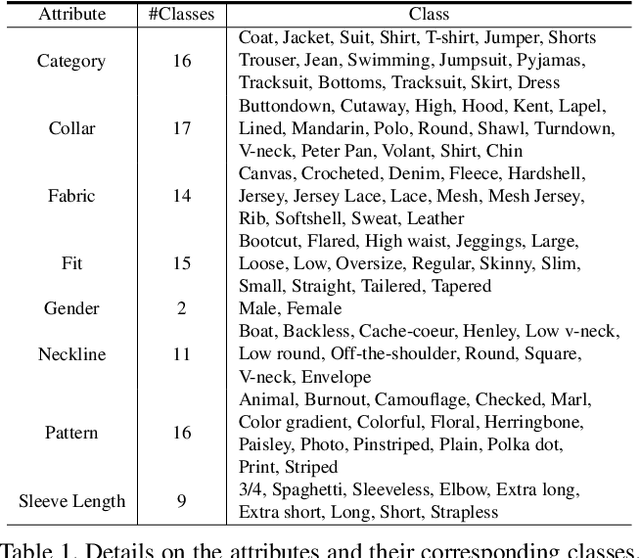
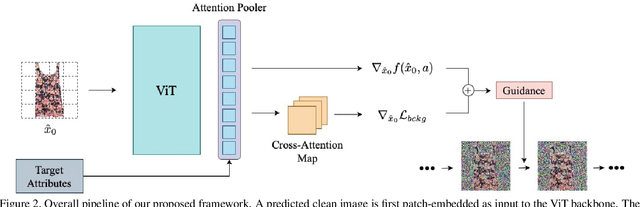
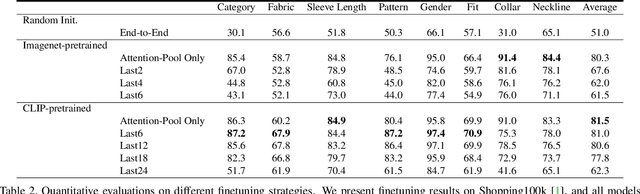
Fashion attribute editing is a task that aims to convert the semantic attributes of a given fashion image while preserving the irrelevant regions. Previous works typically employ conditional GANs where the generator explicitly learns the target attributes and directly execute the conversion. These approaches, however, are neither scalable nor generic as they operate only with few limited attributes and a separate generator is required for each dataset or attribute set. Inspired by the recent advancement of diffusion models, we explore the classifier-guided diffusion that leverages the off-the-shelf diffusion model pretrained on general visual semantics such as Imagenet. In order to achieve a generic editing pipeline, we pose this as multi-attribute image manipulation task, where the attribute ranges from item category, fabric, pattern to collar and neckline. We empirically show that conventional methods fail in our challenging setting, and study efficient adaptation scheme that involves recently introduced attention-pooling technique to obtain a multi-attribute classifier guidance. Based on this, we present a mask-free fashion attribute editing framework that leverages the classifier logits and the cross-attention map for manipulation. We empirically demonstrate that our framework achieves convincing sample quality and attribute alignments.
Towards Efficient Neural Scene Graphs by Learning Consistency Fields
Oct 09, 2022
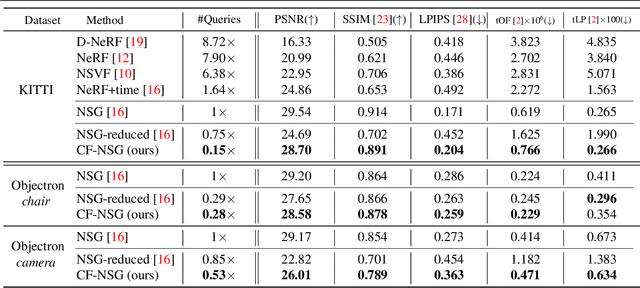
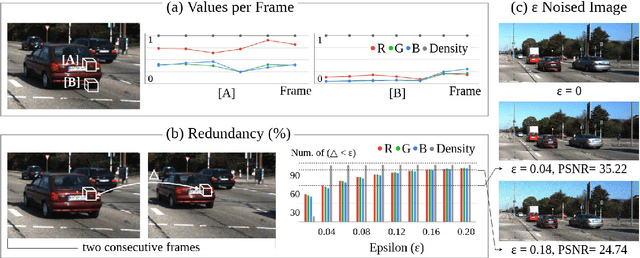

Neural Radiance Fields (NeRF) achieves photo-realistic image rendering from novel views, and the Neural Scene Graphs (NSG) \cite{ost2021neural} extends it to dynamic scenes (video) with multiple objects. Nevertheless, computationally heavy ray marching for every image frame becomes a huge burden. In this paper, taking advantage of significant redundancy across adjacent frames in videos, we propose a feature-reusing framework. From the first try of naively reusing the NSG features, however, we learn that it is crucial to disentangle object-intrinsic properties consistent across frames from transient ones. Our proposed method, \textit{Consistency-Field-based NSG (CF-NSG)}, reformulates neural radiance fields to additionally consider \textit{consistency fields}. With disentangled representations, CF-NSG takes full advantage of the feature-reusing scheme and performs an extended degree of scene manipulation in a more controllable manner. We empirically verify that CF-NSG greatly improves the inference efficiency by using 85\% less queries than NSG without notable degradation in rendering quality. Code will be available at: https://github.com/ldynx/CF-NSG
Conservative Generator, Progressive Discriminator: Coordination of Adversaries in Few-shot Incremental Image Synthesis
Jul 29, 2022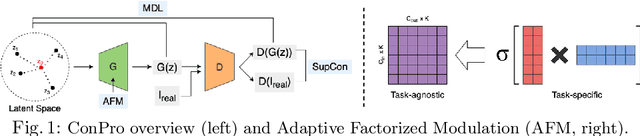
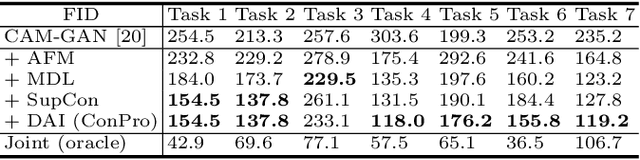

The capacity to learn incrementally from an online stream of data is an envied trait of human learners, as deep neural networks typically suffer from catastrophic forgetting and stability-plasticity dilemma. Several works have previously explored incremental few-shot learning, a task with greater challenges due to data constraint, mostly in classification setting with mild success. In this work, we study the underrepresented task of generative incremental few-shot learning. To effectively handle the inherent challenges of incremental learning and few-shot learning, we propose a novel framework named ConPro that leverages the two-player nature of GANs. Specifically, we design a conservative generator that preserves past knowledge in parameter and compute efficient manner, and a progressive discriminator that learns to reason semantic distances between past and present task samples, minimizing overfitting with few data points and pursuing good forward transfer. We present experiments to validate the effectiveness of ConPro.
Smoothing the Generative Latent Space with Mixup-based Distance Learning
Nov 23, 2021

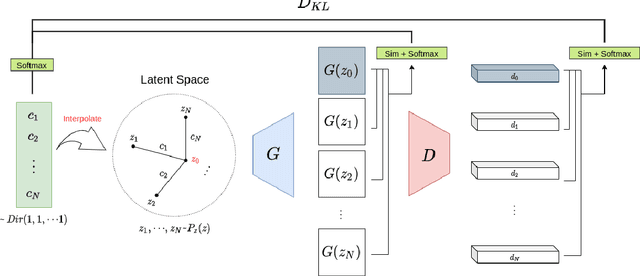

Producing diverse and realistic images with generative models such as GANs typically requires large scale training with vast amount of images. GANs trained with extremely limited data can easily overfit to few training samples and display undesirable properties like "stairlike" latent space where transitions in latent space suffer from discontinuity, occasionally yielding abrupt changes in outputs. In this work, we consider the situation where neither large scale dataset of our interest nor transferable source dataset is available, and seek to train existing generative models with minimal overfitting and mode collapse. We propose latent mixup-based distance regularization on the feature space of both a generator and the counterpart discriminator that encourages the two players to reason not only about the scarce observed data points but the relative distances in the feature space they reside. Qualitative and quantitative evaluation on diverse datasets demonstrates that our method is generally applicable to existing models to enhance both fidelity and diversity under the constraint of limited data. Code will be made public.