 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Data Protection for Diffusion Model by Matching Training Trajectory
Dec 11, 2025Recent advancements in diffusion models have made fine-tuning text-to-image models for personalization increasingly accessible, but have also raised significant concerns regarding unauthorized data usage and privacy infringement. Current protection methods are limited to passively degrading image quality, failing to achieve stable control. While Targeted Data Protection (TDP) offers a promising paradigm for active redirection toward user-specified target concepts, existing TDP attempts suffer from poor controllability due to snapshot-matching approaches that fail to account for complete learning dynamics. We introduce TAFAP (Trajectory Alignment via Fine-tuning with Adversarial Perturbations), the first method to successfully achieve effective TDP by controlling the entire training trajectory. Unlike snapshot-based methods whose protective influence is easily diluted as training progresses, TAFAP employs trajectory-matching inspired by dataset distillation to enforce persistent, verifiable transformations throughout fine-tuning. We validate our method through extensive experiments, demonstrating the first successful targeted transformation in diffusion models with simultaneous control over both identity and visual patterns. TAFAP significantly outperforms existing TDP attempts, achieving robust redirection toward target concepts while maintaining high image quality. This work enables verifiable safeguards and provides a new framework for controlling and tracing alterations in diffusion model outputs.
ReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation
Jul 02, 2025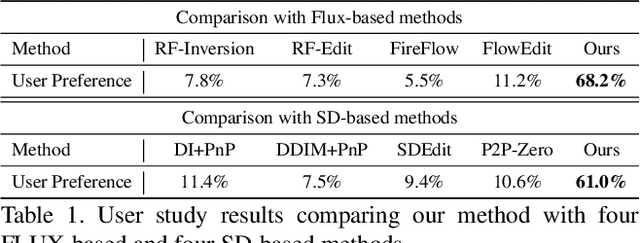

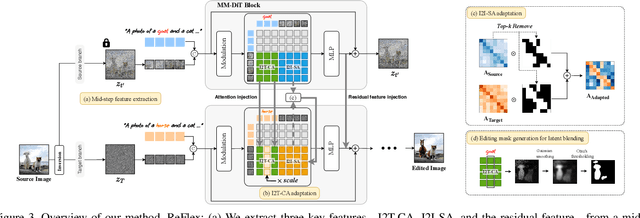

Rectified Flow text-to-image models surpass diffusion models in image quality and text alignment, but adapting ReFlow for real-image editing remains challenging. We propose a new real-image editing method for ReFlow by analyzing the intermediate representations of multimodal transformer blocks and identifying three key features. To extract these features from real images with sufficient structural preservation, we leverage mid-step latent, which is inverted only up to the mid-step. We then adapt attention during injection to improve editability and enhance alignment to the target text. Our method is training-free, requires no user-provided mask, and can be applied even without a source prompt. Extensive experiments on two benchmarks with nine baselines demonstrate its superior performance over prior methods, further validated by human evaluations confirming a strong user preference for our approach.
Harmonizing Visual and Textual Embeddings for Zero-Shot Text-to-Image Customization
Mar 21, 2024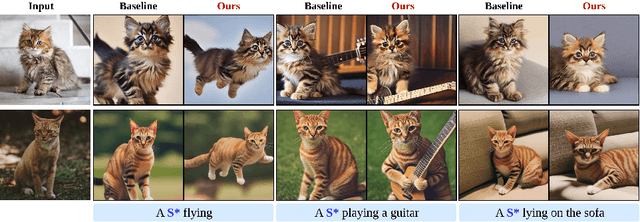
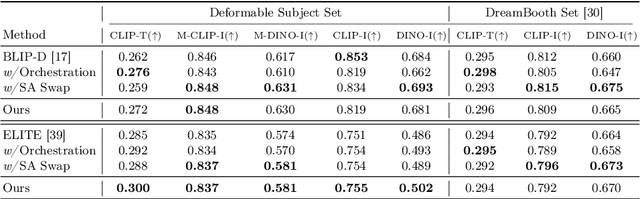
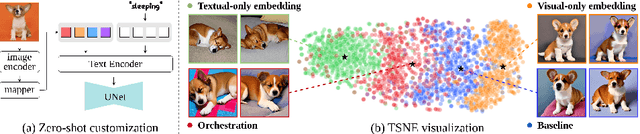
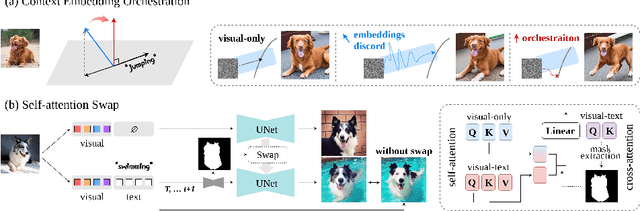
In a surge of text-to-image (T2I) models and their customization methods that generate new images of a user-provided subject, current works focus on alleviating the costs incurred by a lengthy per-subject optimization. These zero-shot customization methods encode the image of a specified subject into a visual embedding which is then utilized alongside the textual embedding for diffusion guidance. The visual embedding incorporates intrinsic information about the subject, while the textual embedding provides a new, transient context. However, the existing methods often 1) are significantly affected by the input images, eg., generating images with the same pose, and 2) exhibit deterioration in the subject's identity. We first pin down the problem and show that redundant pose information in the visual embedding interferes with the textual embedding containing the desired pose information. To address this issue, we propose orthogonal visual embedding which effectively harmonizes with the given textual embedding. We also adopt the visual-only embedding and inject the subject's clear features utilizing a self-attention swap. Our results demonstrate the effectiveness and robustness of our method, which offers highly flexible zero-shot generation while effectively maintaining the subject's identity.
SAVE: Protagonist Diversification with Structure Agnostic Video Editing
Dec 05, 2023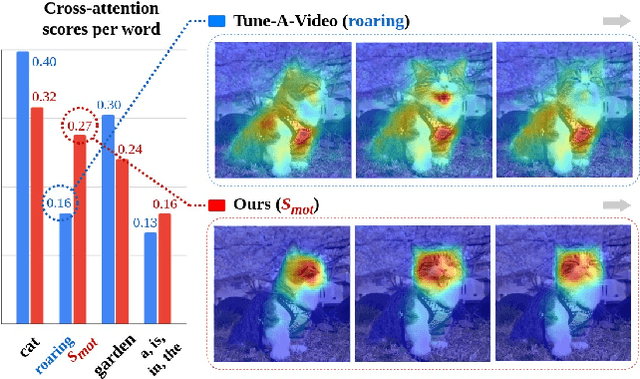
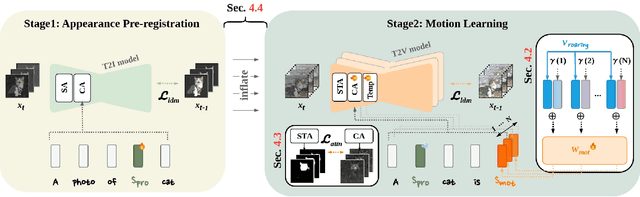

Driven by the upsurge progress in text-to-image (T2I) generation models, text-to-video (T2V) generation has experienced a significant advance as well. Accordingly, tasks such as modifying the object or changing the style in a video have been possible. However, previous works usually work well on trivial and consistent shapes, and easily collapse on a difficult target that has a largely different body shape from the original one. In this paper, we spot the bias problem in the existing video editing method that restricts the range of choices for the new protagonist and attempt to address this issue using the conventional image-level personalization method. We adopt motion personalization that isolates the motion from a single source video and then modifies the protagonist accordingly. To deal with the natural discrepancy between image and video, we propose a motion word with an inflated textual embedding to properly represent the motion in a source video. We also regulate the motion word to attend to proper motion-related areas by introducing a novel pseudo optical flow, efficiently computed from the pre-calculated attention maps. Finally, we decouple the motion from the appearance of the source video with an additional pseudo word. Extensive experiments demonstrate the editing capability of our method, taking a step toward more diverse and extensive video editing.
Towards Efficient Neural Scene Graphs by Learning Consistency Fields
Oct 09, 2022
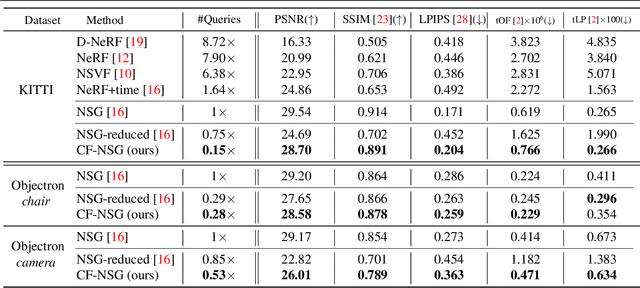
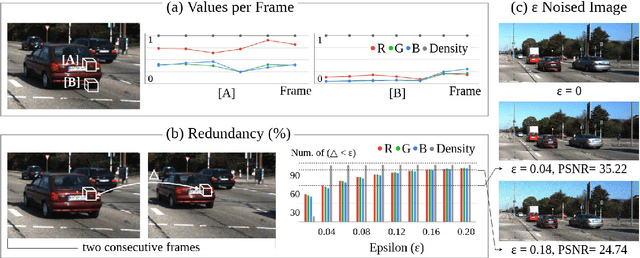

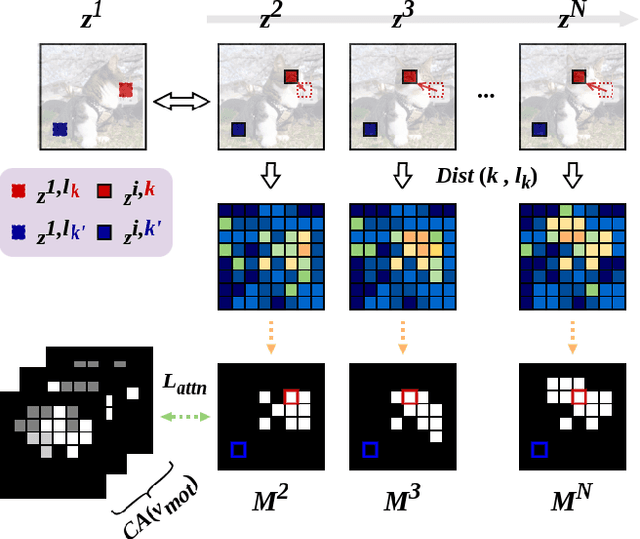
Neural Radiance Fields (NeRF) achieves photo-realistic image rendering from novel views, and the Neural Scene Graphs (NSG) \cite{ost2021neural} extends it to dynamic scenes (video) with multiple objects. Nevertheless, computationally heavy ray marching for every image frame becomes a huge burden. In this paper, taking advantage of significant redundancy across adjacent frames in videos, we propose a feature-reusing framework. From the first try of naively reusing the NSG features, however, we learn that it is crucial to disentangle object-intrinsic properties consistent across frames from transient ones. Our proposed method, \textit{Consistency-Field-based NSG (CF-NSG)}, reformulates neural radiance fields to additionally consider \textit{consistency fields}. With disentangled representations, CF-NSG takes full advantage of the feature-reusing scheme and performs an extended degree of scene manipulation in a more controllable manner. We empirically verify that CF-NSG greatly improves the inference efficiency by using 85\% less queries than NSG without notable degradation in rendering quality. Code will be available at: https://github.com/ldynx/CF-NSG
Dynamic Collective Intelligence Learning: Finding Efficient Sparse Model via Refined Gradients for Pruned Weights
Sep 10, 2021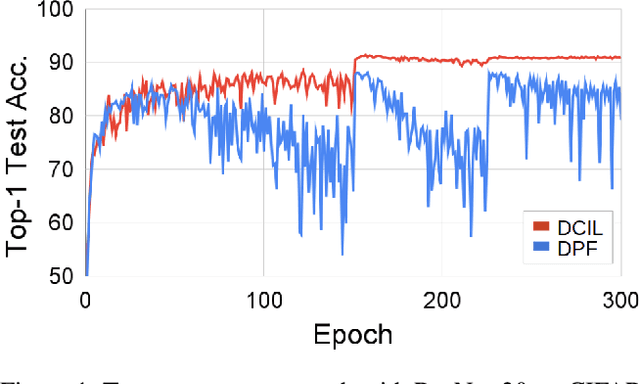
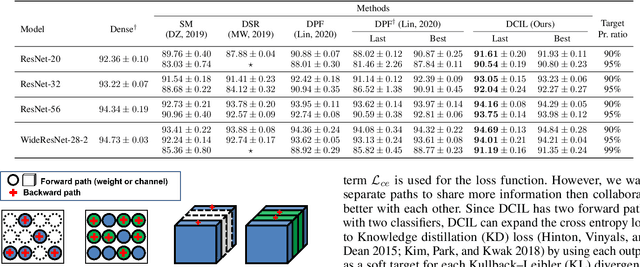
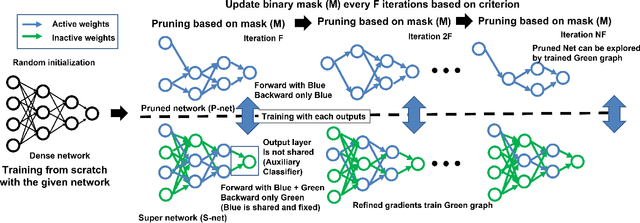
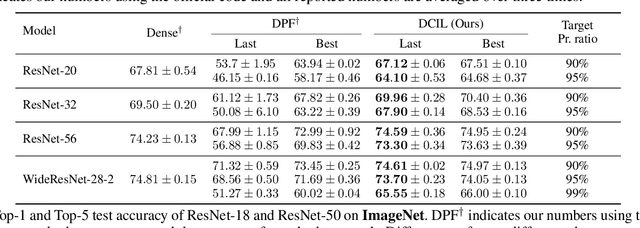
With the growth of deep neural networks (DNN), the number of DNN parameters has drastically increased. This makes DNN models hard to be deployed on resource-limited embedded systems. To alleviate this problem, dynamic pruning methods have emerged, which try to find diverse sparsity patterns during training by utilizing Straight-Through-Estimator (STE) to approximate gradients of pruned weights. STE can help the pruned weights revive in the process of finding dynamic sparsity patterns. However, using these coarse gradients causes training instability and performance degradation owing to the unreliable gradient signal of the STE approximation. In this work, to tackle this issue, we introduce refined gradients to update the pruned weights by forming dual forwarding paths from two sets (pruned and unpruned) of weights. We propose a novel Dynamic Collective Intelligence Learning (DCIL) which makes use of the learning synergy between the collective intelligence of both weight sets. We verify the usefulness of the refined gradients by showing enhancements in the training stability and the model performance on the CIFAR and ImageNet datasets. DCIL outperforms various previously proposed pruning schemes including other dynamic pruning methods with enhanced stability during training.
Part-Aware Data Augmentation for 3D Object Detection in Point Cloud
Jul 27, 2020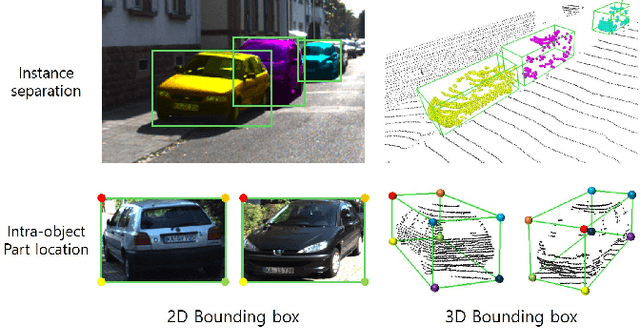
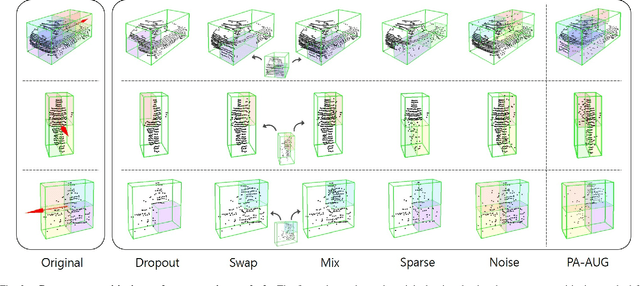
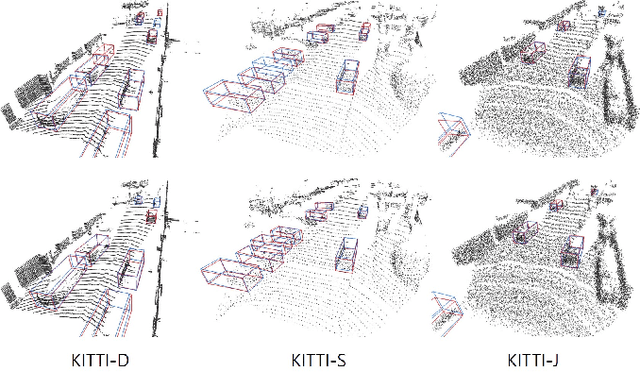
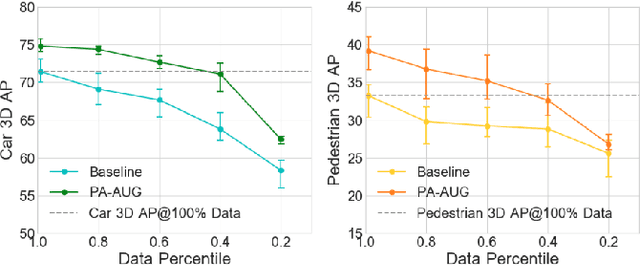
Data augmentation has greatly contributed to improving the performance in image recognition tasks, and a lot of related studies have been conducted. However, data augmentation on 3D point cloud data has not been much explored. 3D label has more sophisticated and rich structural information than the 2D label, so it enables more diverse and effective data augmentation. In this paper, we propose part-aware data augmentation (PA-AUG) that can better utilize rich information of 3D label to enhance the performance of 3D object detectors. PA-AUG divides objects into partitions and stochastically applies five novel augmentation methods to each local region. It is compatible with existing point cloud data augmentation methods and can be used universally regardless of the detector's architecture. PA-AUG has improved the performance of state-of-the-art 3D object detector for all classes of the KITTI dataset and has the equivalent effect of increasing the train data by about 2.5$\times$. We also show that PA-AUG not only increases performance for a given dataset but also is robust to corrupted data. CODE WILL BE AVAILABLE.