 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Zero-Cost Protection Against Mimicry by Personalized Diffusion Models
Dec 16, 2024Recent advancements in diffusion models revolutionize image generation but pose risks of misuse, such as replicating artworks or generating deepfakes. Existing image protection methods, though effective, struggle to balance protection efficacy, invisibility, and latency, thus limiting practical use. We introduce perturbation pre-training to reduce latency and propose a mixture-of-perturbations approach that dynamically adapts to input images to minimize performance degradation. Our novel training strategy computes protection loss across multiple VAE feature spaces, while adaptive targeted protection at inference enhances robustness and invisibility. Experiments show comparable protection performance with improved invisibility and drastically reduced inference time. The code and demo are available at \url{https://webtoon.github.io/impasto}
Imperceptible Protection against Style Imitation from Diffusion Models
Mar 28, 2024Recent progress in diffusion models has profoundly enhanced the fidelity of image generation. However, this has raised concerns about copyright infringements. While prior methods have introduced adversarial perturbations to prevent style imitation, most are accompanied by the degradation of artworks' visual quality. Recognizing the importance of maintaining this, we develop a visually improved protection method that preserves its protection capability. To this end, we create a perceptual map to identify areas most sensitive to human eyes. We then adjust the protection intensity guided by an instance-aware refinement. We also integrate a perceptual constraints bank to further improve the imperceptibility. Results show that our method substantially elevates the quality of the protected image without compromising on protection efficacy.
Open Domain Generalization with a Single Network by Regularization Exploiting Pre-trained Features
Dec 08, 2023



Open Domain Generalization (ODG) is a challenging task as it not only deals with distribution shifts but also category shifts between the source and target datasets. To handle this task, the model has to learn a generalizable representation that can be applied to unseen domains while also identify unknown classes that were not present during training. Previous work has used multiple source-specific networks, which involve a high computation cost. Therefore, this paper proposes a method that can handle ODG using only a single network. The proposed method utilizes a head that is pre-trained by linear-probing and employs two regularization terms, each targeting the regularization of feature extractor and the classification head, respectively. The two regularization terms fully utilize the pre-trained features and collaborate to modify the head of the model without excessively altering the feature extractor. This ensures a smoother softmax output and prevents the model from being biased towards the source domains. The proposed method shows improved adaptability to unseen domains and increased capability to detect unseen classes as well. Extensive experiments show that our method achieves competitive performance in several benchmarks. We also justify our method with careful analysis of the effect on the logits, features, and the head.
Advancing Beyond Identification: Multi-bit Watermark for Language Models
Aug 01, 2023


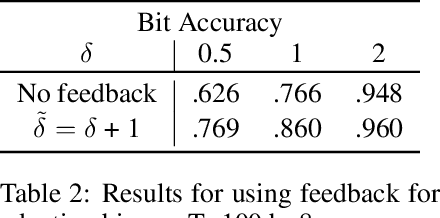
This study aims to proactively tackle misuse of large language models beyond identification of machine-generated text. While existing methods focus on detection, some malicious misuses demand tracing the adversary user for counteracting them. To address this, we propose "Multi-bit Watermark through Color-listing" (COLOR), embedding traceable multi-bit information during language model generation. Leveraging the benefits of zero-bit watermarking (Kirchenbauer et al., 2023a), COLOR enables extraction without model access, on-the-fly embedding, and maintains text quality, while allowing zero-bit detection all at the same time. Preliminary experiments demonstrates successful embedding of 32-bit messages with 91.9% accuracy in moderate-length texts ($\sim$500 tokens). This work advances strategies to counter language model misuse effectively.
Robust Natural Language Watermarking through Invariant Features
May 03, 2023Recent years have witnessed a proliferation of valuable original natural language contents found in subscription-based media outlets, web novel platforms, and outputs of large language models. Without proper security measures, however, these contents are susceptible to illegal piracy and potential misuse. This calls for a secure watermarking system to guarantee copyright protection through leakage tracing or ownership identification. To effectively combat piracy and protect copyrights, a watermarking framework should be able not only to embed adequate bits of information but also extract the watermarks in a robust manner despite possible corruption. In this work, we explore ways to advance both payload and robustness by following a well-known proposition from image watermarking and identify features in natural language that are invariant to minor corruption. Through a systematic analysis of the possible sources of errors, we further propose a corruption-resistant infill model. Our full method improves upon the previous work on robustness by +16.8% point on average on four datasets, three corruption types, and two corruption ratios. Code available at https://github.com/bangawayoo/nlp-watermarking.
Backdoor Attacks in Federated Learning by Rare Embeddings and Gradient Ensembling
Apr 29, 2022
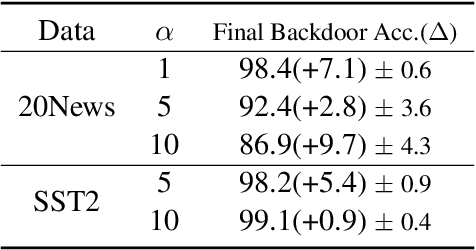
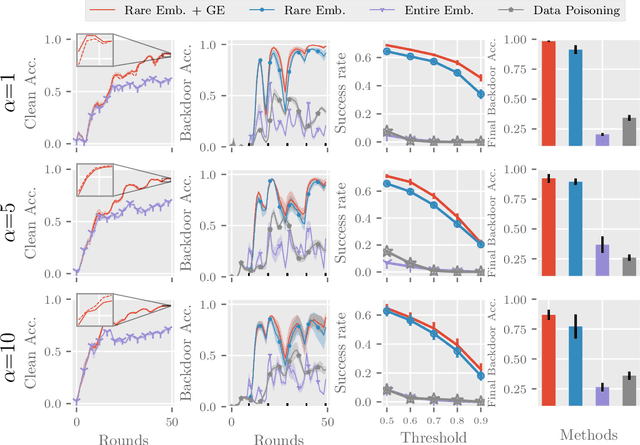

Recent advances in federated learning have demonstrated its promising capability to learn on decentralized datasets. However, a considerable amount of work has raised concerns due to the potential risks of adversaries participating in the framework to poison the global model for an adversarial purpose. This paper investigates the feasibility of model poisoning for backdoor attacks through \textit{rare word embeddings of NLP models} in text classification and sequence-to-sequence tasks. In text classification, less than 1\% of adversary clients suffices to manipulate the model output without any drop in the performance of clean sentences. For a less complex dataset, a mere 0.1\% of adversary clients is enough to poison the global model effectively. We also propose a technique specialized in the federated learning scheme called gradient ensemble, which enhances the backdoor performance in all experimental settings.
Detection of Word Adversarial Examples in Text Classification: Benchmark and Baseline via Robust Density Estimation
Mar 03, 2022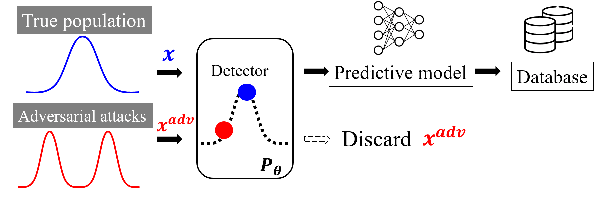
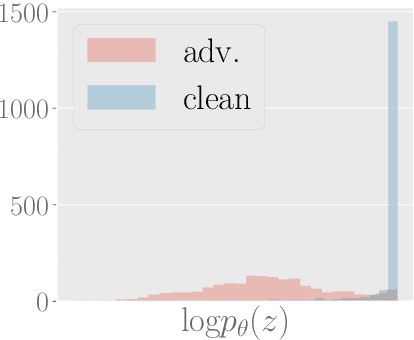

Word-level adversarial attacks have shown success in NLP models, drastically decreasing the performance of transformer-based models in recent years. As a countermeasure, adversarial defense has been explored, but relatively few efforts have been made to detect adversarial examples. However, detecting adversarial examples may be crucial for automated tasks (e.g. review sentiment analysis) that wish to amass information about a certain population and additionally be a step towards a robust defense system. To this end, we release a dataset for four popular attack methods on four datasets and four models to encourage further research in this field. Along with it, we propose a competitive baseline based on density estimation that has the highest AUC on 29 out of 30 dataset-attack-model combinations. Source code is available in https://github.com/anoymous92874838/text-adv-detection.
Self-Evolutionary Optimization for Pareto Front Learning
Oct 07, 2021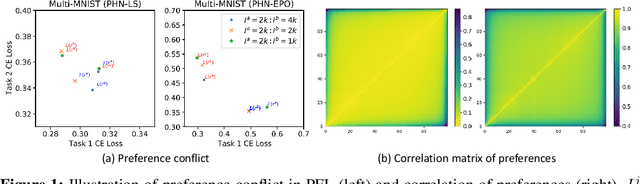

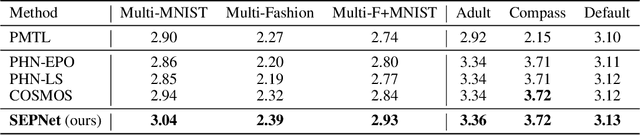
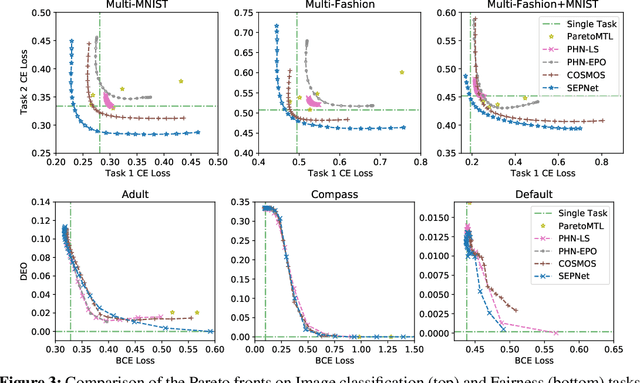
Multi-task learning (MTL), which aims to improve performance by learning multiple tasks simultaneously, inherently presents an optimization challenge due to multiple objectives. Hence, multi-objective optimization (MOO) approaches have been proposed for multitasking problems. Recent MOO methods approximate multiple optimal solutions (Pareto front) with a single unified model, which is collectively referred to as Pareto front learning (PFL). In this paper, we show that PFL can be re-formulated into another MOO problem with multiple objectives, each of which corresponds to different preference weights for the tasks. We leverage an evolutionary algorithm (EA) to propose a method for PFL called self-evolutionary optimization (SEO) by directly maximizing the hypervolume. By using SEO, the neural network learns to approximate the Pareto front conditioned on multiple hyper-parameters that drastically affect the hypervolume. Then, by generating a population of approximations simply by inferencing the network, the hyper-parameters of the network can be optimized by EA. Utilizing SEO for PFL, we also introduce self-evolutionary Pareto networks (SEPNet), enabling the unified model to approximate the entire Pareto front set that maximizes the hypervolume. Extensive experimental results confirm that SEPNet can find a better Pareto front than the current state-of-the-art methods while minimizing the increase in model size and training cost.
Dynamic Collective Intelligence Learning: Finding Efficient Sparse Model via Refined Gradients for Pruned Weights
Sep 10, 2021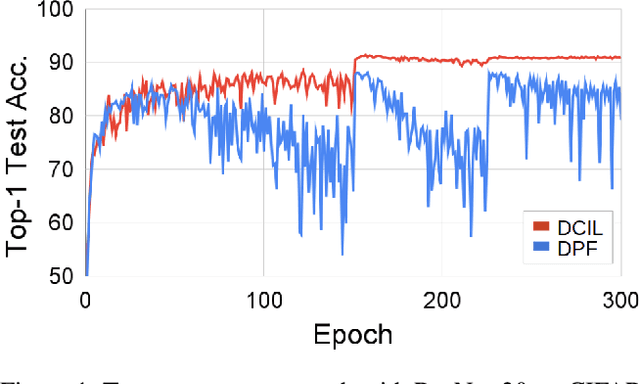
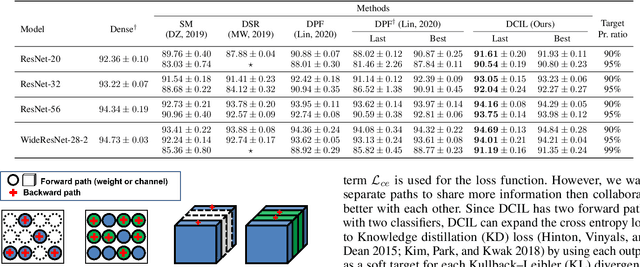
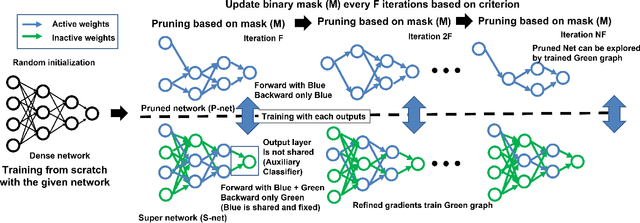
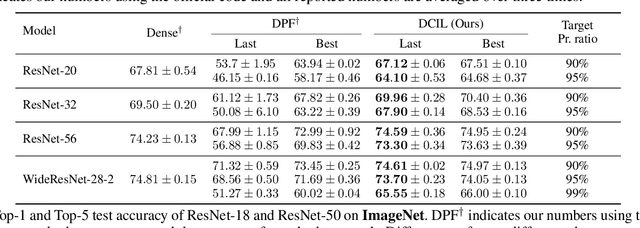
With the growth of deep neural networks (DNN), the number of DNN parameters has drastically increased. This makes DNN models hard to be deployed on resource-limited embedded systems. To alleviate this problem, dynamic pruning methods have emerged, which try to find diverse sparsity patterns during training by utilizing Straight-Through-Estimator (STE) to approximate gradients of pruned weights. STE can help the pruned weights revive in the process of finding dynamic sparsity patterns. However, using these coarse gradients causes training instability and performance degradation owing to the unreliable gradient signal of the STE approximation. In this work, to tackle this issue, we introduce refined gradients to update the pruned weights by forming dual forwarding paths from two sets (pruned and unpruned) of weights. We propose a novel Dynamic Collective Intelligence Learning (DCIL) which makes use of the learning synergy between the collective intelligence of both weight sets. We verify the usefulness of the refined gradients by showing enhancements in the training stability and the model performance on the CIFAR and ImageNet datasets. DCIL outperforms various previously proposed pruning schemes including other dynamic pruning methods with enhanced stability during training.
On the Orthogonality of Knowledge Distillation with Other Techniques: From an Ensemble Perspective
Sep 14, 2020


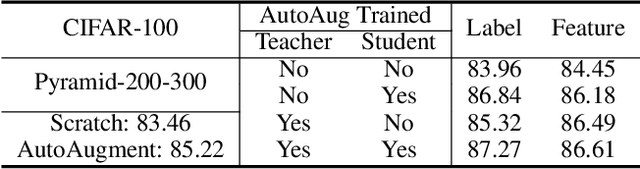
To put a state-of-the-art neural network to practical use, it is necessary to design a model that has a good trade-off between the resource consumption and performance on the test set. Many researchers and engineers are developing methods that enable training or designing a model more efficiently. Developing an efficient model includes several strategies such as network architecture search, pruning, quantization, knowledge distillation, utilizing cheap convolution, regularization, and also includes any craft that leads to a better performance-resource trade-off. When combining these technologies together, it would be ideal if one source of performance improvement does not conflict with others. We call this property as the orthogonality in model efficiency. In this paper, we focus on knowledge distillation and demonstrate that knowledge distillation methods are orthogonal to other efficiency-enhancing methods both analytically and empirically. Analytically, we claim that knowledge distillation functions analogous to a ensemble method, bootstrap aggregating. This analytical explanation is provided from the perspective of implicit data augmentation property of knowledge distillation. Empirically, we verify knowledge distillation as a powerful apparatus for practical deployment of efficient neural network, and also introduce ways to integrate it with other methods effectively.