 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-Selective Feature Distillation for Single Image Super-Resolution
Nov 22, 2021



Recent improvements in convolutional neural network (CNN)-based single image super-resolution (SISR) methods rely heavily on fabricating network architectures, rather than finding a suitable training algorithm other than simply minimizing the regression loss. Adapting knowledge distillation (KD) can open a way for bringing further improvement for SISR, and it is also beneficial in terms of model efficiency. KD is a model compression method that improves the performance of Deep Neural Networks (DNNs) without using additional parameters for testing. It is getting the limelight recently for its competence at providing a better capacity-performance tradeoff. In this paper, we propose a novel feature distillation (FD) method which is suitable for SISR. We show the limitations of the existing FitNet-based FD method that it suffers in the SISR task, and propose to modify the existing FD algorithm to focus on local feature information. In addition, we propose a teacher-student-difference-based soft feature attention method that selectively focuses on specific pixel locations to extract feature information. We call our method local-selective feature distillation (LSFD) and verify that our method outperforms conventional FD methods in SISR problems.
On the Orthogonality of Knowledge Distillation with Other Techniques: From an Ensemble Perspective
Sep 14, 2020


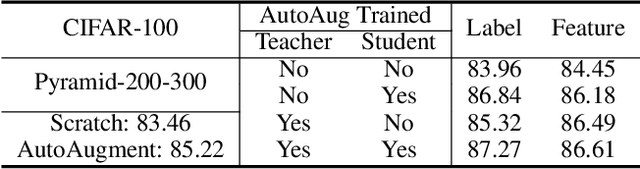
To put a state-of-the-art neural network to practical use, it is necessary to design a model that has a good trade-off between the resource consumption and performance on the test set. Many researchers and engineers are developing methods that enable training or designing a model more efficiently. Developing an efficient model includes several strategies such as network architecture search, pruning, quantization, knowledge distillation, utilizing cheap convolution, regularization, and also includes any craft that leads to a better performance-resource trade-off. When combining these technologies together, it would be ideal if one source of performance improvement does not conflict with others. We call this property as the orthogonality in model efficiency. In this paper, we focus on knowledge distillation and demonstrate that knowledge distillation methods are orthogonal to other efficiency-enhancing methods both analytically and empirically. Analytically, we claim that knowledge distillation functions analogous to a ensemble method, bootstrap aggregating. This analytical explanation is provided from the perspective of implicit data augmentation property of knowledge distillation. Empirically, we verify knowledge distillation as a powerful apparatus for practical deployment of efficient neural network, and also introduce ways to integrate it with other methods effectively.
Feature-map-level Online Adversarial Knowledge Distillation
Feb 05, 2020
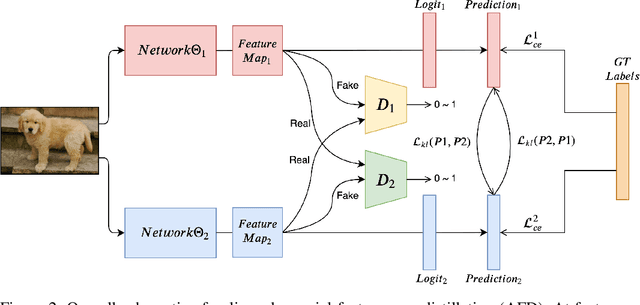
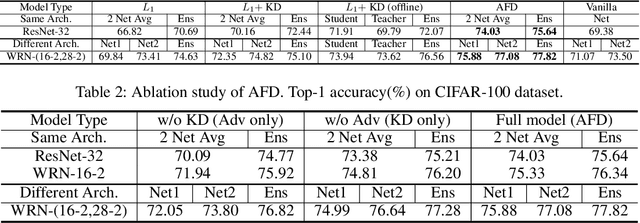
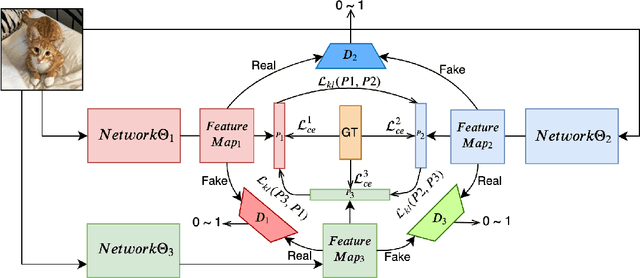
Feature maps contain rich information about image intensity and spatial correlation. However, previous online knowledge distillation methods only utilize the class probabilities. Thus in this paper, we propose an online knowledge distillation method that transfers not only the knowledge of the class probabilities but also that of the feature map using the adversarial training framework. We train multiple networks simultaneously by employing discriminators to distinguish the feature map distributions of different networks. Each network has its corresponding discriminator which discriminates the feature map from its own as fake while classifying that of the other network as real. By training a network to fool the corresponding discriminator, it can learn the other network's feature map distribution. We show that our method performs better than the conventional direct alignment method such as L1 and is more suitable for online distillation. Also, we propose a novel cyclic learning scheme for training more than two networks together. We have applied our method to various network architectures on the classification task and discovered a significant improvement of performance especially in the case of training a pair of a small network and a large one.
FEED: Feature-level Ensemble for Knowledge Distillation
Sep 24, 2019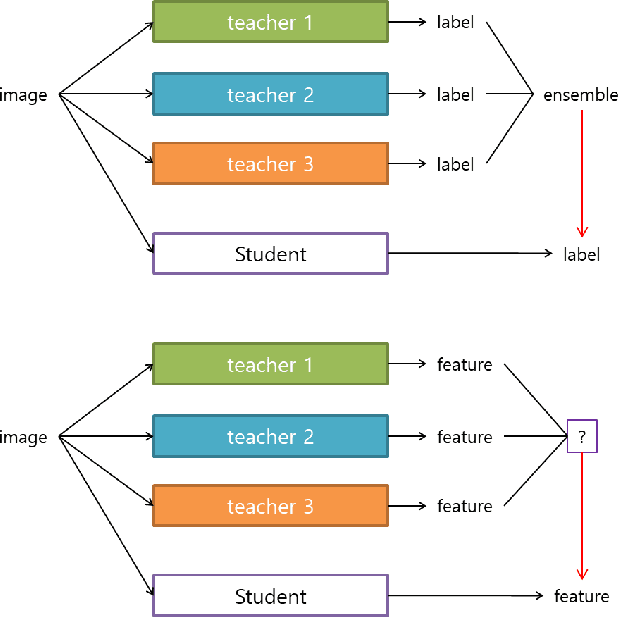
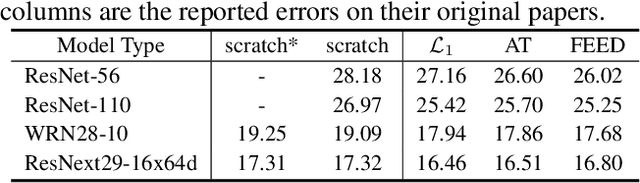
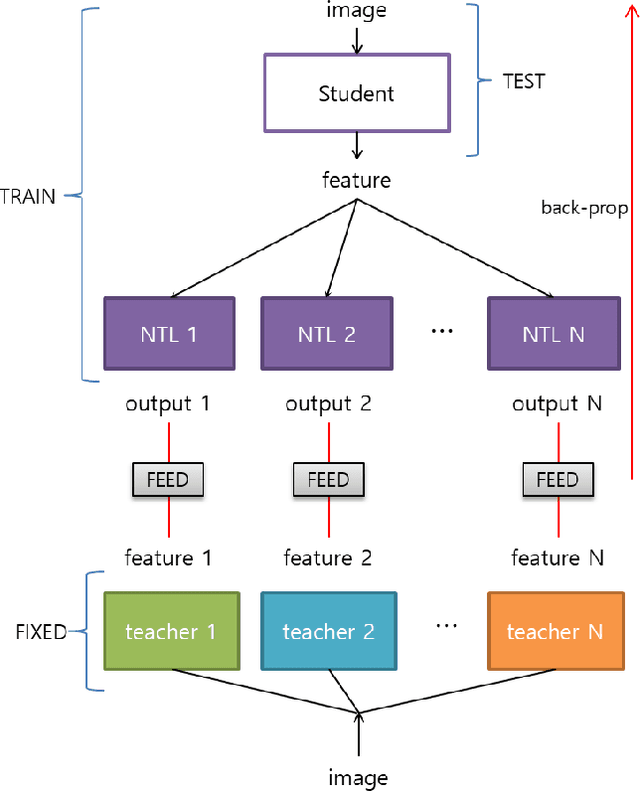

Knowledge Distillation (KD) aims to transfer knowledge in a teacher-student framework, by providing the predictions of the teacher network to the student network in the training stage to help the student network generalize better. It can use either a teacher with high capacity or {an} ensemble of multiple teachers. However, the latter is not convenient when one wants to use feature-map-based distillation methods. For a solution, this paper proposes a versatile and powerful training algorithm named FEature-level Ensemble for knowledge Distillation (FEED), which aims to transfer the ensemble knowledge using multiple teacher networks. We introduce a couple of training algorithms that transfer ensemble knowledge to the student at the feature map level. Among the feature-map-based distillation methods, using several non-linear transformations in parallel for transferring the knowledge of the multiple teacher{s} helps the student find more generalized solutions. We name this method as parallel FEED, andexperimental results on CIFAR-100 and ImageNet show that our method has clear performance enhancements, without introducing any additional parameters or computations at test time. We also show the experimental results of sequentially feeding teacher's information to the student, hence the name sequential FEED, and discuss the lessons obtained. Additionally, the empirical results on measuring the reconstruction errors at the feature map give hints for the enhancements.
Image Translation to Mixed-Domain using Sym-Parameterized Generative Network
Nov 29, 2018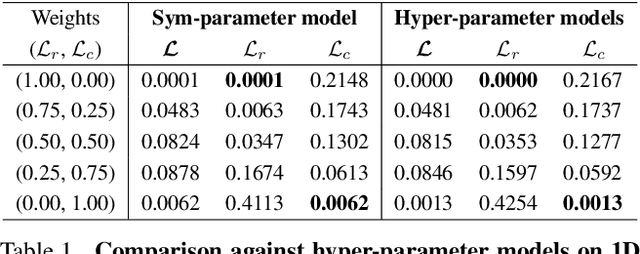
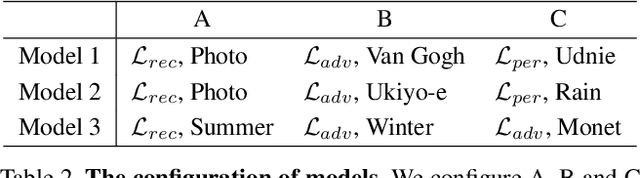

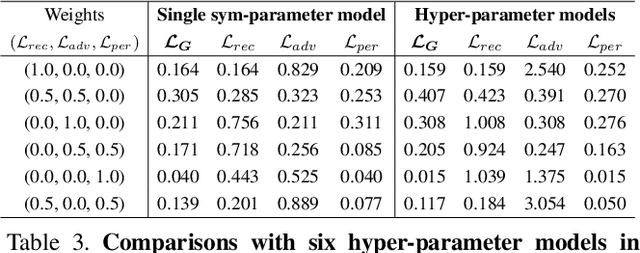
Recent advances in image-to-image translation have led to some ways to generate multiple domain images through a single network. However, there is still a limit in creating an image of a target domain without a dataset on it. We propose a method to expand the concept of `multi-domain' from data to the loss area, and to combine the characteristics of each domain to create an image. First, we introduce a sym-parameter and its learning method that can mix various losses and can synchronize them with input conditions. Then, we propose Sym-parameterized Generative Network (SGN) using it. Through experiments, we confirmed that SGN could mix the characteristics of various data and loss, and it is possible to translate images to any mixed-domain without ground truths, such as 30% Van Gogh and 20% Monet.