 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramBench: Can Language Models Rebuild Programs From Scratch?
May 05, 2026Turning ideas into full software projects from scratch has become a popular use case for language models. Agents are being deployed to seed, maintain, and grow codebases over extended periods with minimal human oversight. Such settings require models to make high-level software architecture decisions. However, existing benchmarks measure focused, limited tasks such as fixing a single bug or developing a single, specified feature. We therefore introduce ProgramBench to measure the ability of software engineering agents to develop software holisitically. In ProgramBench, given only a program and its documentation, agents must architect and implement a codebase that matches the reference executable's behavior. End-to-end behavioral tests are generated via agent-driven fuzzing, enabling evaluation without prescribing implementation structure. Our 200 tasks range from compact CLI tools to widely used software such as FFmpeg, SQLite, and the PHP interpreter. We evaluate 9 LMs and find that none fully resolve any task, with the best model passing 95\% of tests on only 3\% of tasks. Models favor monolithic, single-file implementations that diverge sharply from human-written code.
SWE-chat: Coding Agent Interactions From Real Users in the Wild
Apr 22, 2026AI coding agents are being adopted at scale, yet we lack empirical evidence on how people actually use them and how much of their output is useful in practice. We present SWE-chat, the first large-scale dataset of real coding agent sessions collected from open-source developers in the wild. The dataset currently contains 6,000 sessions, comprising more than 63,000 user prompts and 355,000 agent tool calls. SWE-chat is a living dataset; our collection pipeline automatically and continually discovers and processes sessions from public repositories. Leveraging SWE-chat, we provide an initial empirical characterization of real-world coding agent usage and failure modes. We find that coding patterns are bimodal: in 41% of sessions, agents author virtually all committed code ("vibe coding"), while in 23%, humans write all code themselves. Despite rapidly improving capabilities, coding agents remain inefficient in natural settings. Just 44% of all agent-produced code survives into user commits, and agent-written code introduces more security vulnerabilities than code authored by humans. Furthermore, users push back against agent outputs -- through corrections, failure reports, and interruptions -- in 44% of all turns. By capturing complete interaction traces with human vs. agent code authorship attribution, SWE-chat provides an empirical foundation for moving beyond curated benchmarks towards an evidence-based understanding of how AI agents perform in real developer workflows.
SWE-Protégé: Learning to Selectively Collaborate With an Expert Unlocks Small Language Models as Software Engineering Agents
Feb 25, 2026Small language models (SLMs) offer compelling advantages in cost, latency, and adaptability, but have so far lagged behind larger models on long-horizon software engineering tasks such as SWE-bench, where they suffer from pervasive action looping and low resolution rates. We introduce SWE-Protégé, a post-training framework that reframes software repair as an expert-protégé collaboration problem. In SWE-Protégé, an SLM remains the sole decision-maker while learning to selectively seek guidance from a strong expert model, recognize stalled states, and follow through on expert feedback. Our approach combines supervised fine-tuning on expert-augmented trajectories with agentic reinforcement learning that explicitly discourages degenerative looping and unproductive expert collaboration. We lightly post-train Qwen2.5-Coder-7B-Instruct to achieve 42.4% Pass@1 on SWE-bench Verified, a +25.4% improvement over the prior SLM state of the art, while using expert assistance sparsely (~4 calls per task and 11% of total tokens).
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
LongCodeBench: Evaluating Coding LLMs at 1M Context Windows
May 12, 2025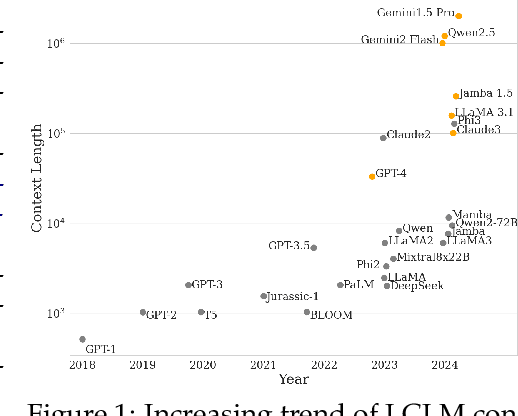
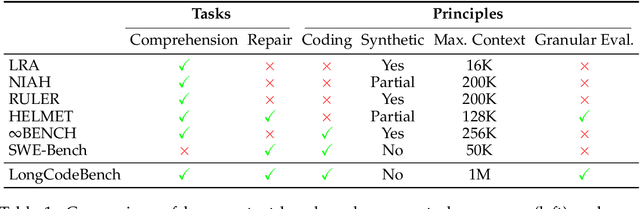
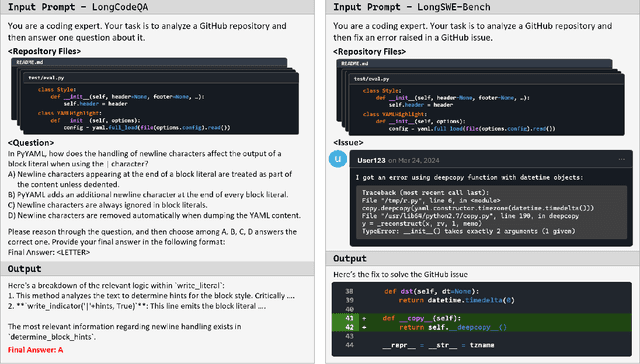
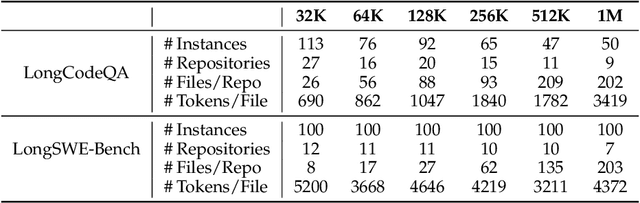
Context lengths for models have grown rapidly, from thousands to millions of tokens in just a few years. The extreme context sizes of modern long-context models have made it difficult to construct realistic long-context benchmarks -- not only due to the cost of collecting million-context tasks but also in identifying realistic scenarios that require significant contexts. We identify code comprehension and repair as a natural testbed and challenge task for long-context models and introduce LongCodeBench (LCB), a benchmark to test LLM coding abilities in long-context scenarios. Our benchmark tests both the comprehension and repair capabilities of LCLMs in realistic and important settings by drawing from real-world GitHub issues and constructing QA (LongCodeQA) and bug fixing (LongSWE-Bench) tasks. We carefully stratify the complexity of our benchmark, enabling us to evaluate models across different scales -- ranging from Qwen2.5 14B Instruct to Google's flagship Gemini model. We find that long-context remains a weakness for all models, with performance drops such as from 29% to 3% for Claude 3.5 Sonnet, or from 70.2% to 40% for Qwen2.5.
SWE-smith: Scaling Data for Software Engineering Agents
Apr 30, 2025Despite recent progress in Language Models (LMs) for software engineering, collecting training data remains a significant pain point. Existing datasets are small, with at most 1,000s of training instances from 11 or fewer GitHub repositories. The procedures to curate such datasets are often complex, necessitating hundreds of hours of human labor; companion execution environments also take up several terabytes of storage, severely limiting their scalability and usability. To address this pain point, we introduce SWE-smith, a novel pipeline for generating software engineering training data at scale. Given any Python codebase, SWE-smith constructs a corresponding execution environment, then automatically synthesizes 100s to 1,000s of task instances that break existing test(s) in the codebase. Using SWE-smith, we create a dataset of 50k instances sourced from 128 GitHub repositories, an order of magnitude larger than all previous works. We train SWE-agent-LM-32B, achieving 40.2% Pass@1 resolve rate on the SWE-bench Verified benchmark, state of the art among open source models. We open source SWE-smith (collection procedure, task instances, trajectories, models) to lower the barrier of entry for research in LM systems for automated software engineering. All assets available at https://swesmith.com.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration
Dec 20, 2024



Recent advancements in language models (LMs) have sparked growing interest in developing LM agents. While fully autonomous agents could excel in many scenarios, numerous use cases inherently require them to collaborate with humans due to humans' latent preferences, domain expertise, or need for control. To facilitate the study of human-agent collaboration, we present Collaborative Gym (Co-Gym), a general framework enabling asynchronous, tripartite interaction among agents, humans, and task environments. We instantiate Co-Gym with three representative tasks in both simulated and real-world conditions, and propose an evaluation framework that assesses both the collaboration outcomes and processes. Our findings reveal that collaborative agents consistently outperform their fully autonomous counterparts in task performance within those delivered cases, achieving win rates of 86% in Travel Planning, 74% in Tabular Analysis, and 66% in Related Work when evaluated by real users. However, our study also highlights significant challenges in developing collaborative agents, requiring advancements in core aspects of intelligence -- communication capabilities, situational awareness, and balancing autonomy and human control.
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?
Oct 04, 2024



Autonomous systems for software engineering are now capable of fixing bugs and developing features. These systems are commonly evaluated on SWE-bench (Jimenez et al., 2024a), which assesses their ability to solve software issues from GitHub repositories. However, SWE-bench uses only Python repositories, with problem statements presented predominantly as text and lacking visual elements such as images. This limited coverage motivates our inquiry into how existing systems might perform on unrepresented software engineering domains (e.g., front-end, game development, DevOps), which use different programming languages and paradigms. Therefore, we propose SWE-bench Multimodal (SWE-bench M), to evaluate systems on their ability to fix bugs in visual, user-facing JavaScript software. SWE-bench M features 617 task instances collected from 17 JavaScript libraries used for web interface design, diagramming, data visualization, syntax highlighting, and interactive mapping. Each SWE-bench M task instance contains at least one image in its problem statement or unit tests. Our analysis finds that top-performing SWE-bench systems struggle with SWE-bench M, revealing limitations in visual problem-solving and cross-language generalization. Lastly, we show that SWE-agent's flexible language-agnostic features enable it to substantially outperform alternatives on SWE-bench M, resolving 12% of task instances compared to 6% for the next best system.