 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Agent Memory in Contextual Intent
Jan 15, 2026Deploying large language models in long-horizon, goal-oriented interactions remains challenging because similar entities and facts recur under different latent goals and constraints, causing memory systems to retrieve context-mismatched evidence. We propose STITCH (Structured Intent Tracking in Contextual History), an agentic memory system that indexes each trajectory step with a structured retrieval cue, contextual intent, and retrieves history by matching the current step's intent. Contextual intent provides compact signals that disambiguate repeated mentions and reduce interference: (1) the current latent goal defining a thematic segment, (2) the action type, and (3) the salient entity types anchoring which attributes matter. During inference, STITCH filters and prioritizes memory snippets by intent compatibility, suppressing semantically similar but context-incompatible history. For evaluation, we introduce CAME-Bench, a benchmark for context-aware retrieval in realistic, dynamic, goal-oriented trajectories. Across CAME-Bench and LongMemEval, STITCH achieves state-of-the-art performance, outperforming the strongest baseline by 35.6%, with the largest gains as trajectory length increases. Our analysis shows that intent indexing substantially reduces retrieval noise, supporting intent-aware memory for robust long-horizon reasoning.
Future of Work with AI Agents: Auditing Automation and Augmentation Potential across the U.S. Workforce
Jun 06, 2025The rapid rise of compound AI systems (a.k.a., AI agents) is reshaping the labor market, raising concerns about job displacement, diminished human agency, and overreliance on automation. Yet, we lack a systematic understanding of the evolving landscape. In this paper, we address this gap by introducing a novel auditing framework to assess which occupational tasks workers want AI agents to automate or augment, and how those desires align with the current technological capabilities. Our framework features an audio-enhanced mini-interview to capture nuanced worker desires and introduces the Human Agency Scale (HAS) as a shared language to quantify the preferred level of human involvement. Using this framework, we construct the WORKBank database, building on the U.S. Department of Labor's O*NET database, to capture preferences from 1,500 domain workers and capability assessments from AI experts across over 844 tasks spanning 104 occupations. Jointly considering the desire and technological capability divides tasks in WORKBank into four zones: Automation "Green Light" Zone, Automation "Red Light" Zone, R&D Opportunity Zone, Low Priority Zone. This highlights critical mismatches and opportunities for AI agent development. Moving beyond a simple automate-or-not dichotomy, our results reveal diverse HAS profiles across occupations, reflecting heterogeneous expectations for human involvement. Moreover, our study offers early signals of how AI agent integration may reshape the core human competencies, shifting from information-focused skills to interpersonal ones. These findings underscore the importance of aligning AI agent development with human desires and preparing workers for evolving workplace dynamics.
Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration
Dec 20, 2024



Recent advancements in language models (LMs) have sparked growing interest in developing LM agents. While fully autonomous agents could excel in many scenarios, numerous use cases inherently require them to collaborate with humans due to humans' latent preferences, domain expertise, or need for control. To facilitate the study of human-agent collaboration, we present Collaborative Gym (Co-Gym), a general framework enabling asynchronous, tripartite interaction among agents, humans, and task environments. We instantiate Co-Gym with three representative tasks in both simulated and real-world conditions, and propose an evaluation framework that assesses both the collaboration outcomes and processes. Our findings reveal that collaborative agents consistently outperform their fully autonomous counterparts in task performance within those delivered cases, achieving win rates of 86% in Travel Planning, 74% in Tabular Analysis, and 66% in Related Work when evaluated by real users. However, our study also highlights significant challenges in developing collaborative agents, requiring advancements in core aspects of intelligence -- communication capabilities, situational awareness, and balancing autonomy and human control.
Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations
Aug 27, 2024While language model (LM)-powered chatbots and generative search engines excel at answering concrete queries, discovering information in the terrain of unknown unknowns remains challenging for users. To emulate the common educational scenario where children/students learn by listening to and participating in conversations of their parents/teachers, we create Collaborative STORM (Co-STORM). Unlike QA systems that require users to ask all the questions, Co-STORM lets users observe and occasionally steer the discourse among several LM agents. The agents ask questions on the user's behalf, allowing the user to discover unknown unknowns serendipitously. To facilitate user interaction, Co-STORM assists users in tracking the discourse by organizing the uncovered information into a dynamic mind map, ultimately generating a comprehensive report as takeaways. For automatic evaluation, we construct the WildSeek dataset by collecting real information-seeking records with user goals. Co-STORM outperforms baseline methods on both discourse trace and report quality. In a further human evaluation, 70% of participants prefer Co-STORM over a search engine, and 78% favor it over a RAG chatbot.
Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
Feb 22, 2024We study how to apply large language models to write grounded and organized long-form articles from scratch, with comparable breadth and depth to Wikipedia pages. This underexplored problem poses new challenges at the pre-writing stage, including how to research the topic and prepare an outline prior to writing. We propose STORM, a writing system for the Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking. STORM models the pre-writing stage by (1) discovering diverse perspectives in researching the given topic, (2) simulating conversations where writers carrying different perspectives pose questions to a topic expert grounded on trusted Internet sources, (3) curating the collected information to create an outline. For evaluation, we curate FreshWiki, a dataset of recent high-quality Wikipedia articles, and formulate outline assessments to evaluate the pre-writing stage. We further gather feedback from experienced Wikipedia editors. Compared to articles generated by an outline-driven retrieval-augmented baseline, more of STORM's articles are deemed to be organized (by a 25% absolute increase) and broad in coverage (by 10%). The expert feedback also helps identify new challenges for generating grounded long articles, such as source bias transfer and over-association of unrelated facts.
Effective Seed-Guided Topic Discovery by Integrating Multiple Types of Contexts
Dec 12, 2022Instead of mining coherent topics from a given text corpus in a completely unsupervised manner, seed-guided topic discovery methods leverage user-provided seed words to extract distinctive and coherent topics so that the mined topics can better cater to the user's interest. To model the semantic correlation between words and seeds for discovering topic-indicative terms, existing seed-guided approaches utilize different types of context signals, such as document-level word co-occurrences, sliding window-based local contexts, and generic linguistic knowledge brought by pre-trained language models. In this work, we analyze and show empirically that each type of context information has its value and limitation in modeling word semantics under seed guidance, but combining three types of contexts (i.e., word embeddings learned from local contexts, pre-trained language model representations obtained from general-domain training, and topic-indicative sentences retrieved based on seed information) allows them to complement each other for discovering quality topics. We propose an iterative framework, SeedTopicMine, which jointly learns from the three types of contexts and gradually fuses their context signals via an ensemble ranking process. Under various sets of seeds and on multiple datasets, SeedTopicMine consistently yields more coherent and accurate topics than existing seed-guided topic discovery approaches.
Entity Set Co-Expansion in StackOverflow
Dec 05, 2022
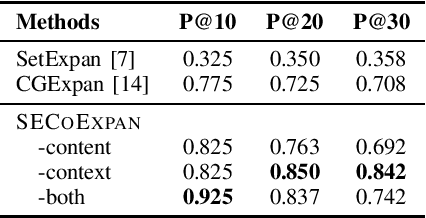
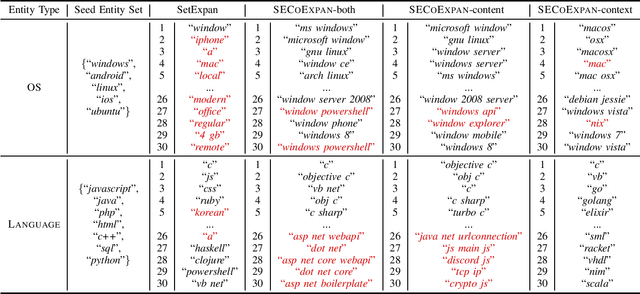
Given a few seed entities of a certain type (e.g., Software or Programming Language), entity set expansion aims to discover an extensive set of entities that share the same type as the seeds. Entity set expansion in software-related domains such as StackOverflow can benefit many downstream tasks (e.g., software knowledge graph construction) and facilitate better IT operations and service management. Meanwhile, existing approaches are less concerned with two problems: (1) How to deal with multiple types of seed entities simultaneously? (2) How to leverage the power of pre-trained language models (PLMs)? Being aware of these two problems, in this paper, we study the entity set co-expansion task in StackOverflow, which extracts Library, OS, Application, and Language entities from StackOverflow question-answer threads. During the co-expansion process, we use PLMs to derive embeddings of candidate entities for calculating similarities between entities. Experimental results show that our proposed SECoExpan framework outperforms previous approaches significantly.