 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Agent Memory in Contextual Intent
Jan 15, 2026Deploying large language models in long-horizon, goal-oriented interactions remains challenging because similar entities and facts recur under different latent goals and constraints, causing memory systems to retrieve context-mismatched evidence. We propose STITCH (Structured Intent Tracking in Contextual History), an agentic memory system that indexes each trajectory step with a structured retrieval cue, contextual intent, and retrieves history by matching the current step's intent. Contextual intent provides compact signals that disambiguate repeated mentions and reduce interference: (1) the current latent goal defining a thematic segment, (2) the action type, and (3) the salient entity types anchoring which attributes matter. During inference, STITCH filters and prioritizes memory snippets by intent compatibility, suppressing semantically similar but context-incompatible history. For evaluation, we introduce CAME-Bench, a benchmark for context-aware retrieval in realistic, dynamic, goal-oriented trajectories. Across CAME-Bench and LongMemEval, STITCH achieves state-of-the-art performance, outperforming the strongest baseline by 35.6%, with the largest gains as trajectory length increases. Our analysis shows that intent indexing substantially reduces retrieval noise, supporting intent-aware memory for robust long-horizon reasoning.
Learning User Preferences Through Interaction for Long-Term Collaboration
Jan 06, 2026As conversational agents accumulate experience collaborating with users, adapting to user preferences is essential for fostering long-term relationships and improving collaboration quality over time. We introduce MultiSessionCollab, a benchmark that evaluates how well agents can learn user preferences and leverage them to improve collaboration quality throughout multiple sessions. To develop agents that succeed in this setting, we present long-term collaborative agents equipped with a memory that persists and refines user preference as interaction experience accumulates. Moreover, we demonstrate that learning signals can be derived from user simulator behavior in MultiSessionCollab to train agents to generate more comprehensive reflections and update their memory more effectively. Extensive experiments show that equipping agents with memory improves long-term collaboration, yielding higher task success rates, more efficient interactions, and reduced user effort. Finally, we conduct a human user study that demonstrates that memory helps improve user experience in real-world settings.
TaxoAdapt: Aligning LLM-Based Multidimensional Taxonomy Construction to Evolving Research Corpora
Jun 12, 2025The rapid evolution of scientific fields introduces challenges in organizing and retrieving scientific literature. While expert-curated taxonomies have traditionally addressed this need, the process is time-consuming and expensive. Furthermore, recent automatic taxonomy construction methods either (1) over-rely on a specific corpus, sacrificing generalizability, or (2) depend heavily on the general knowledge of large language models (LLMs) contained within their pre-training datasets, often overlooking the dynamic nature of evolving scientific domains. Additionally, these approaches fail to account for the multi-faceted nature of scientific literature, where a single research paper may contribute to multiple dimensions (e.g., methodology, new tasks, evaluation metrics, benchmarks). To address these gaps, we propose TaxoAdapt, a framework that dynamically adapts an LLM-generated taxonomy to a given corpus across multiple dimensions. TaxoAdapt performs iterative hierarchical classification, expanding both the taxonomy width and depth based on corpus' topical distribution. We demonstrate its state-of-the-art performance across a diverse set of computer science conferences over the years to showcase its ability to structure and capture the evolution of scientific fields. As a multidimensional method, TaxoAdapt generates taxonomies that are 26.51% more granularity-preserving and 50.41% more coherent than the most competitive baselines judged by LLMs.
Beyond True or False: Retrieval-Augmented Hierarchical Analysis of Nuanced Claims
Jun 12, 2025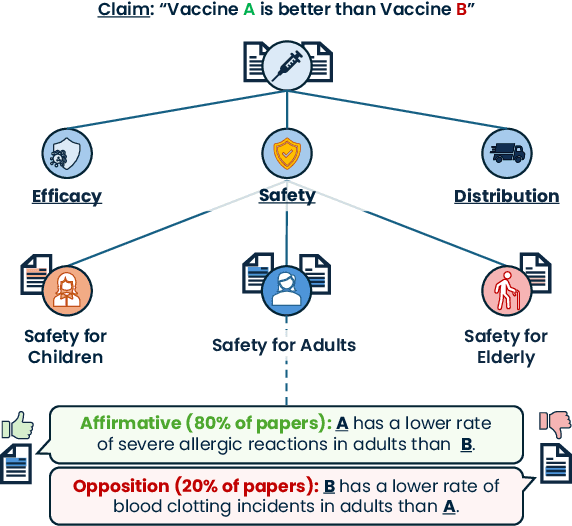
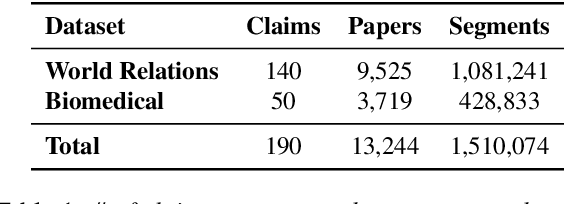
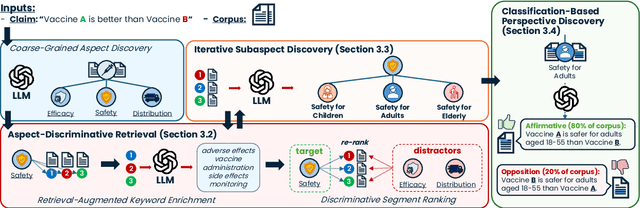
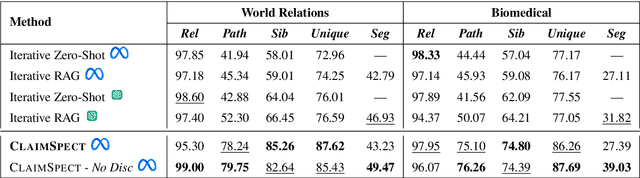
Claims made by individuals or entities are oftentimes nuanced and cannot be clearly labeled as entirely "true" or "false" -- as is frequently the case with scientific and political claims. However, a claim (e.g., "vaccine A is better than vaccine B") can be dissected into its integral aspects and sub-aspects (e.g., efficacy, safety, distribution), which are individually easier to validate. This enables a more comprehensive, structured response that provides a well-rounded perspective on a given problem while also allowing the reader to prioritize specific angles of interest within the claim (e.g., safety towards children). Thus, we propose ClaimSpect, a retrieval-augmented generation-based framework for automatically constructing a hierarchy of aspects typically considered when addressing a claim and enriching them with corpus-specific perspectives. This structure hierarchically partitions an input corpus to retrieve relevant segments, which assist in discovering new sub-aspects. Moreover, these segments enable the discovery of varying perspectives towards an aspect of the claim (e.g., support, neutral, or oppose) and their respective prevalence (e.g., "how many biomedical papers believe vaccine A is more transportable than B?"). We apply ClaimSpect to a wide variety of real-world scientific and political claims featured in our constructed dataset, showcasing its robustness and accuracy in deconstructing a nuanced claim and representing perspectives within a corpus. Through real-world case studies and human evaluation, we validate its effectiveness over multiple baselines.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
An Empirical Study on Reinforcement Learning for Reasoning-Search Interleaved LLM Agents
May 21, 2025



Reinforcement learning (RL) has demonstrated strong potential in training large language models (LLMs) capable of complex reasoning for real-world problem solving. More recently, RL has been leveraged to create sophisticated LLM-based search agents that adeptly combine reasoning with search engine use. While the use of RL for training search agents is promising, the optimal design of such agents remains not fully understood. In particular, key factors -- such as (1) reward formulation, (2) the choice and characteristics of the underlying LLM, and (3) the role of the search engine in the RL process -- require further investigation. In this work, we conduct comprehensive empirical studies to systematically investigate these and offer actionable insights. We highlight several key findings: format rewards are effective in improving final performance, whereas intermediate retrieval rewards have limited impact; the scale and initialization of the LLM (general-purpose vs. reasoning-specialized) significantly influence RL outcomes; and the choice of search engine plays a critical role in shaping RL training dynamics and the robustness of the trained agent during inference. These establish important guidelines for successfully building and deploying LLM-based search agents in real-world applications. Code is available at https://github.com/PeterGriffinJin/Search-R1.
Tree-of-Debate: Multi-Persona Debate Trees Elicit Critical Thinking for Scientific Comparative Analysis
Feb 20, 2025With the exponential growth of research facilitated by modern technology and improved accessibility, scientific discoveries have become increasingly fragmented within and across fields. This makes it challenging to assess the significance, novelty, incremental findings, and equivalent ideas between related works, particularly those from different research communities. Large language models (LLMs) have recently demonstrated strong quantitative and qualitative reasoning abilities, and multi-agent LLM debates have shown promise in handling complex reasoning tasks by exploring diverse perspectives and reasoning paths. Inspired by this, we introduce Tree-of-Debate (ToD), a framework which converts scientific papers into LLM personas that debate their respective novelties. To emphasize structured, critical reasoning rather than focusing solely on outcomes, ToD dynamically constructs a debate tree, enabling fine-grained analysis of independent novelty arguments within scholarly articles. Through experiments on scientific literature across various domains, evaluated by expert researchers, we demonstrate that ToD generates informative arguments, effectively contrasts papers, and supports researchers in their literature review.
Unsupervised Episode Detection for Large-Scale News Events
Aug 09, 2024Episodic structures are inherently interpretable and adaptable to evolving large-scale key events. However, state-of-the-art automatic event detection methods overlook event episodes and, therefore, struggle with these crucial characteristics. This paper introduces a novel task, episode detection, aimed at identifying episodes from a news corpus containing key event articles. An episode describes a cohesive cluster of core entities (e.g., "protesters", "police") performing actions at a specific time and location. Furthermore, an episode is a significant part of a larger group of episodes under a particular key event. Automatically detecting episodes is challenging because, unlike key events and atomic actions, we cannot rely on explicit mentions of times and locations to distinguish between episodes or use semantic similarity to merge inconsistent episode co-references. To address these challenges, we introduce EpiMine, an unsupervised episode detection framework that (1) automatically identifies the most salient, key-event-relevant terms and segments, (2) determines candidate episodes in an article based on natural episodic partitions estimated through shifts in discriminative term combinations, and (3) refines and forms final episode clusters using large language model-based reasoning on the candidate episodes. We construct three diverse, real-world event datasets annotated at the episode level. EpiMine outperforms all baselines on these datasets by an average 59.2% increase across all metrics.
Instruct, Not Assist: LLM-based Multi-Turn Planning and Hierarchical Questioning for Socratic Code Debugging
Jun 17, 2024



Socratic questioning is an effective teaching strategy, encouraging critical thinking and problem-solving. The conversational capabilities of large language models (LLMs) show great potential for providing scalable, real-time student guidance. However, current LLMs often give away solutions directly, making them ineffective instructors. We tackle this issue in the code debugging domain with TreeInstruct, an Instructor agent guided by a novel state space-based planning algorithm. TreeInstruct asks probing questions to help students independently identify and resolve errors. It estimates a student's conceptual and syntactical knowledge to dynamically construct a question tree based on their responses and current knowledge state, effectively addressing both independent and dependent mistakes concurrently in a multi-turn interaction setting. In addition to using an existing single-bug debugging benchmark, we construct a more challenging multi-bug dataset of 150 coding problems, incorrect solutions, and bug fixes -- all carefully constructed and annotated by experts. Extensive evaluation shows TreeInstruct's state-of-the-art performance on both datasets, proving it to be a more effective instructor than baselines. Furthermore, a real-world case study with five students of varying skill levels further demonstrates TreeInstruct's ability to guide students to debug their code efficiently with minimal turns and highly Socratic questioning.
MEGClass: Text Classification with Extremely Weak Supervision via Mutually-Enhancing Text Granularities
Apr 04, 2023



Text classification typically requires a substantial amount of human-annotated data to serve as supervision, which is costly to obtain in dynamic emerging domains. Certain methods seek to address this problem by solely relying on the surface text of class names to serve as extremely weak supervision. However, existing methods fail to account for single-class documents discussing multiple topics. Both topic diversity and vague sentences may introduce noise into the document's underlying representation and consequently the precision of the predicted class. Furthermore, current work focuses on text granularities (documents, sentences, or words) independently, which limits the degree of coarse- or fine-grained context that we can jointly extract from all three to identify significant subtext for classification. In order to address this problem, we propose MEGClass, an extremely weakly-supervised text classification method to exploit Mutually-Enhancing Text Granularities. Specifically, MEGClass constructs class-oriented sentence and class representations based on keywords for performing a sentence-level confidence-weighted label ensemble in order to estimate a document's initial class distribution. This serves as the target distribution for a multi-head attention network with a class-weighted contrastive loss. This network learns contextualized sentence representations and weights to form document representations that reflect its original document and sentence-level topic diversity. Retaining this heterogeneity allows MEGClass to select the most class-indicative documents to serve as iterative feedback for enhancing the class representations. Finally, these top documents are used to fine-tune a pre-trained text classifier. As demonstrated through extensive experiments on six benchmark datasets, MEGClass outperforms other weakly and extremely weakly supervised methods.