 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIMU: Selective Influence Machine Unlearning
Oct 09, 2025The undesired memorization of sensitive information by Large Language Models (LLMs) has emphasized the need for safety mechanisms that can regulate model behavior. This has led to the development of machine unlearning techniques that enable models to precisely forget sensitive and unwanted information. For machine unlearning, first-order and second-order optimizer-based methods have shown significant progress in enabling LLMs to forget targeted information. However, in doing so, these approaches often compromise the model's original capabilities, resulting in unlearned models that struggle to retain their prior knowledge and overall utility. To address this, we propose Selective Influence Machine Unlearning (SIMU), a two-step framework that enhances second-order optimizer-based unlearning by selectively updating only the critical neurons responsible for encoding the forget-set. By constraining updates to these targeted neurons, SIMU achieves comparable unlearning efficacy while substantially outperforming current methods in retaining the model's original knowledge.
Question Generation for Assessing Early Literacy Reading Comprehension
Jul 30, 2025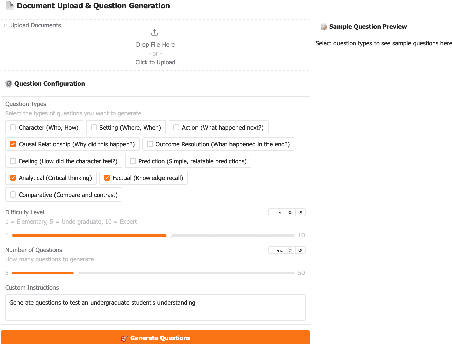
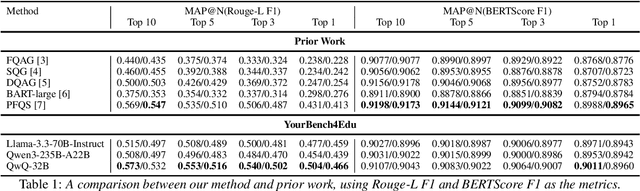
Assessment of reading comprehension through content-based interactions plays an important role in the reading acquisition process. In this paper, we propose a novel approach for generating comprehension questions geared to K-2 English learners. Our method ensures complete coverage of the underlying material and adaptation to the learner's specific proficiencies, and can generate a large diversity of question types at various difficulty levels to ensure a thorough evaluation. We evaluate the performance of various language models in this framework using the FairytaleQA dataset as the source material. Eventually, the proposed approach has the potential to become an important part of autonomous AI-driven English instructors.
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
May 16, 2025Reinforcement learning (RL) yields substantial improvements in large language models (LLMs) downstream task performance and alignment with human values. Surprisingly, such large gains result from updating only a small subnetwork comprising just 5 percent to 30 percent of the parameters, with the rest effectively unchanged. We refer to this phenomenon as parameter update sparsity induced by RL. It is observed across all 7 widely used RL algorithms (e.g., PPO, GRPO, DPO) and all 10 LLMs from different families in our experiments. This sparsity is intrinsic and occurs without any explicit sparsity promoting regularizations or architectural constraints. Finetuning the subnetwork alone recovers the test accuracy, and, remarkably, produces a model nearly identical to the one obtained via full finetuning. The subnetworks from different random seeds, training data, and even RL algorithms show substantially greater overlap than expected by chance. Our analysis suggests that this sparsity is not due to updating only a subset of layers, instead, nearly all parameter matrices receive similarly sparse updates. Moreover, the updates to almost all parameter matrices are nearly full-rank, suggesting RL updates a small subset of parameters that nevertheless span almost the full subspaces that the parameter matrices can represent. We conjecture that the this update sparsity can be primarily attributed to training on data that is near the policy distribution, techniques that encourage the policy to remain close to the pretrained model, such as the KL regularization and gradient clipping, have limited impact.
Spark: A System for Scientifically Creative Idea Generation
Apr 25, 2025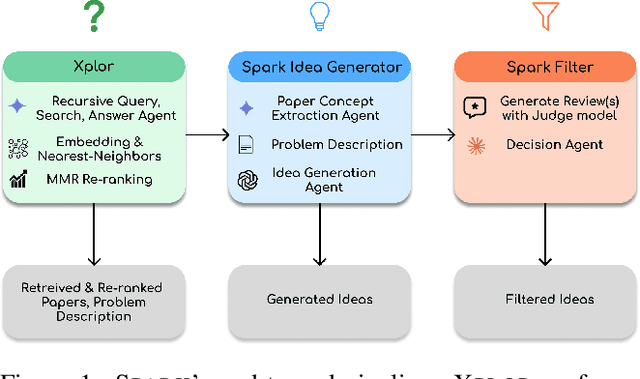


Recently, large language models (LLMs) have shown promising abilities to generate novel research ideas in science, a direction which coincides with many foundational principles in computational creativity (CC). In light of these developments, we present an idea generation system named Spark that couples retrieval-augmented idea generation using LLMs with a reviewer model named Judge trained on 600K scientific reviews from OpenReview. Our work is both a system demonstration and intended to inspire other CC researchers to explore grounding the generation and evaluation of scientific ideas within foundational CC principles. To this end, we release the annotated dataset used to train Judge, inviting other researchers to explore the use of LLMs for idea generation and creative evaluations.
Uncovering Cross-Domain Recommendation Ability of Large Language Models
Mar 10, 2025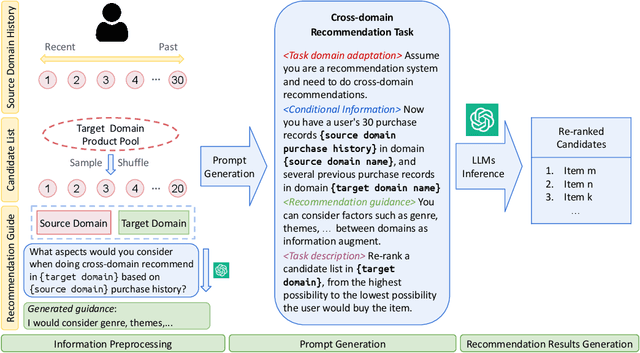
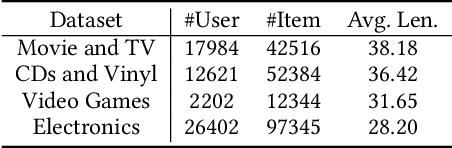

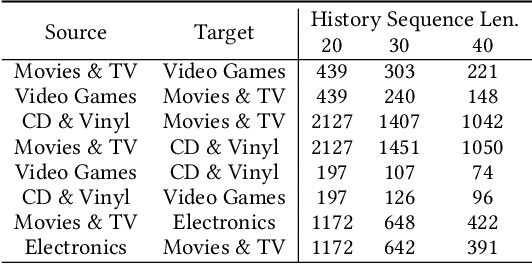
Cross-Domain Recommendation (CDR) seeks to enhance item retrieval in low-resource domains by transferring knowledge from high-resource domains. While recent advancements in Large Language Models (LLMs) have demonstrated their potential in Recommender Systems (RS), their ability to effectively transfer domain knowledge for improved recommendations remains underexplored. To bridge this gap, we propose LLM4CDR, a novel CDR pipeline that constructs context-aware prompts by leveraging users' purchase history sequences from a source domain along with shared features between source and target domains. Through extensive experiments, we show that LLM4CDR achieves strong performance, particularly when using LLMs with large parameter sizes and when the source and target domains exhibit smaller domain gaps. For instance, incorporating CD and Vinyl purchase history for recommendations in Movies and TV yields a 64.28 percent MAP 1 improvement. We further investigate key factors including source domain data, domain gap, prompt design, and LLM size, which impact LLM4CDR's effectiveness in CDR tasks. Our results highlight that LLM4CDR excels when leveraging a single, closely related source domain and benefits significantly from larger LLMs. These insights pave the way for future research on LLM-driven cross-domain recommendations.
Towards Preventing Overreliance on Task-Oriented Conversational AI Through Accountability Modeling
Jan 17, 2025Recent LLMs have enabled significant advancements for conversational agents. However, they are also well-known to hallucinate, i.e., they often produce responses that seem plausible but are not factually correct. On the other hand, users tend to over-rely on LLM-based AI agents; they accept the AI's suggestion even when it is wrong. Adding good friction, such as explanations or getting user confirmations, has been proposed as a mitigation in AI-supported decision-making systems. In this paper, we propose an accountability model for LLM-based task-oriented dialogue agents to address user overreliance via friction turns in cases of model uncertainty and errors associated with dialogue state tracking (DST). The accountability model is an augmented LLM with an additional accountability head, which functions as a binary classifier to predict the slots of the dialogue states. We perform our experiments with three backbone LLMs (Llama, Mistral, Gemma) on two established task-oriented datasets (MultiWOZ and Snips). Our empirical findings demonstrate that this approach not only enables reliable estimation of AI agent errors but also guides the LLM decoder in generating more accurate actions. We observe around 3% absolute improvement in joint goal accuracy by incorporating accountability heads in modern LLMs for the MultiWOZ dataset. We also show that this method enables the agent to self-correct its actions, further boosting its performance by 3%. Finally, we discuss the application of accountability modeling to prevent user overreliance by introducing friction.
Large Language Models as User-Agents for Evaluating Task-Oriented-Dialogue Systems
Nov 15, 2024Traditionally, offline datasets have been used to evaluate task-oriented dialogue (TOD) models. These datasets lack context awareness, making them suboptimal benchmarks for conversational systems. In contrast, user-agents, which are context-aware, can simulate the variability and unpredictability of human conversations, making them better alternatives as evaluators. Prior research has utilized large language models (LLMs) to develop user-agents. Our work builds upon this by using LLMs to create user-agents for the evaluation of TOD systems. This involves prompting an LLM, using in-context examples as guidance, and tracking the user-goal state. Our evaluation of diversity and task completion metrics for the user-agents shows improved performance with the use of better prompts. Additionally, we propose methodologies for the automatic evaluation of TOD models within this dynamic framework.
Infogent: An Agent-Based Framework for Web Information Aggregation
Oct 24, 2024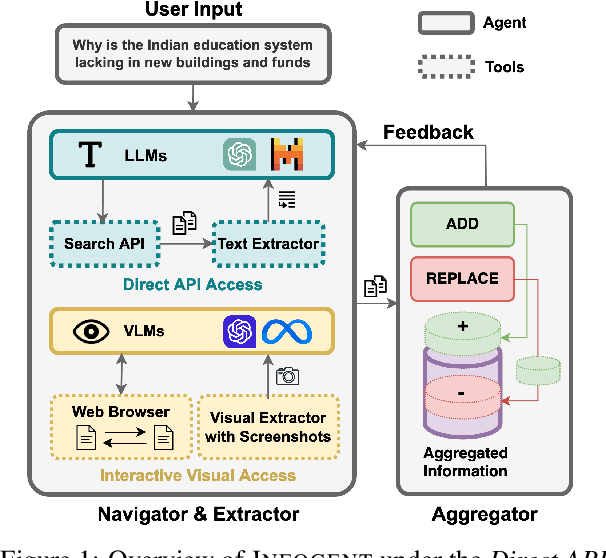

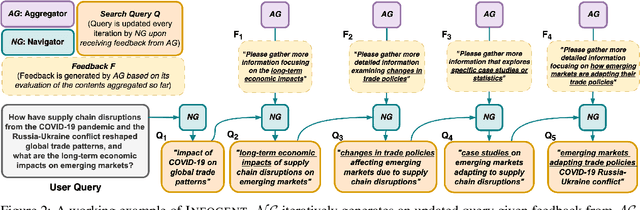
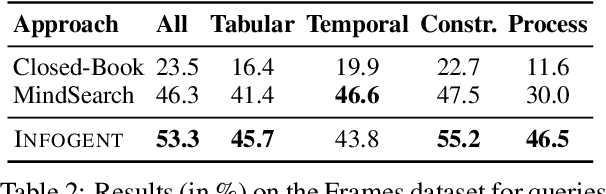
Despite seemingly performant web agents on the task-completion benchmarks, most existing methods evaluate the agents based on a presupposition: the web navigation task consists of linear sequence of actions with an end state that marks task completion. In contrast, our work focuses on web navigation for information aggregation, wherein the agent must explore different websites to gather information for a complex query. We consider web information aggregation from two different perspectives: (i) Direct API-driven Access relies on a text-only view of the Web, leveraging external tools such as Google Search API to navigate the web and a scraper to extract website contents. (ii) Interactive Visual Access uses screenshots of the webpages and requires interaction with the browser to navigate and access information. Motivated by these diverse information access settings, we introduce Infogent, a novel modular framework for web information aggregation involving three distinct components: Navigator, Extractor and Aggregator. Experiments on different information access settings demonstrate Infogent beats an existing SOTA multi-agent search framework by 7% under Direct API-Driven Access on FRAMES, and improves over an existing information-seeking web agent by 4.3% under Interactive Visual Access on AssistantBench.
Aligning LLMs with Individual Preferences via Interaction
Oct 04, 2024As large language models (LLMs) demonstrate increasingly advanced capabilities, aligning their behaviors with human values and preferences becomes crucial for their wide adoption. While previous research focuses on general alignment to principles such as helpfulness, harmlessness, and honesty, the need to account for individual and diverse preferences has been largely overlooked, potentially undermining customized human experiences. To address this gap, we train LLMs that can ''interact to align'', essentially cultivating the meta-skill of LLMs to implicitly infer the unspoken personalized preferences of the current user through multi-turn conversations, and then dynamically align their following behaviors and responses to these inferred preferences. Our approach involves establishing a diverse pool of 3,310 distinct user personas by initially creating seed examples, which are then expanded through iterative self-generation and filtering. Guided by distinct user personas, we leverage multi-LLM collaboration to develop a multi-turn preference dataset containing 3K+ multi-turn conversations in tree structures. Finally, we apply supervised fine-tuning and reinforcement learning to enhance LLMs using this dataset. For evaluation, we establish the ALOE (ALign With CustOmized PrEferences) benchmark, consisting of 100 carefully selected examples and well-designed metrics to measure the customized alignment performance during conversations. Experimental results demonstrate the effectiveness of our method in enabling dynamic, personalized alignment via interaction.
Confidence Estimation for LLM-Based Dialogue State Tracking
Sep 15, 2024



Estimation of a model's confidence on its outputs is critical for Conversational AI systems based on large language models (LLMs), especially for reducing hallucination and preventing over-reliance. In this work, we provide an exhaustive exploration of methods, including approaches proposed for open- and closed-weight LLMs, aimed at quantifying and leveraging model uncertainty to improve the reliability of LLM-generated responses, specifically focusing on dialogue state tracking (DST) in task-oriented dialogue systems (TODS). Regardless of the model type, well-calibrated confidence scores are essential to handle uncertainties, thereby improving model performance. We evaluate four methods for estimating confidence scores based on softmax, raw token scores, verbalized confidences, and a combination of these methods, using the area under the curve (AUC) metric to assess calibration, with higher AUC indicating better calibration. We also enhance these with a self-probing mechanism, proposed for closed models. Furthermore, we assess these methods using an open-weight model fine-tuned for the task of DST, achieving superior joint goal accuracy (JGA). Our findings also suggest that fine-tuning open-weight LLMs can result in enhanced AUC performance, indicating better confidence score calibration.