 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSweRank+: Multilingual, Multi-Turn Code Ranking for Software Issue Localization
Dec 23, 2025Maintaining large-scale, multilingual codebases hinges on accurately localizing issues, which requires mapping natural-language error descriptions to the relevant functions that need to be modified. However, existing ranking approaches are often Python-centric and perform a single-pass search over the codebase. This work introduces SweRank+, a framework that couples SweRankMulti, a cross-lingual code ranking tool, with SweRankAgent, an agentic search setup, for iterative, multi-turn reasoning over the code repository. SweRankMulti comprises a code embedding retriever and a listwise LLM reranker, and is trained using a carefully curated large-scale issue localization dataset spanning multiple popular programming languages. SweRankAgent adopts an agentic search loop that moves beyond single-shot localization with a memory buffer to reason and accumulate relevant localization candidates over multiple turns. Our experiments on issue localization benchmarks spanning various languages demonstrate new state-of-the-art performance with SweRankMulti, while SweRankAgent further improves localization over single-pass ranking.
SweRank: Software Issue Localization with Code Ranking
May 07, 2025Software issue localization, the task of identifying the precise code locations (files, classes, or functions) relevant to a natural language issue description (e.g., bug report, feature request), is a critical yet time-consuming aspect of software development. While recent LLM-based agentic approaches demonstrate promise, they often incur significant latency and cost due to complex multi-step reasoning and relying on closed-source LLMs. Alternatively, traditional code ranking models, typically optimized for query-to-code or code-to-code retrieval, struggle with the verbose and failure-descriptive nature of issue localization queries. To bridge this gap, we introduce SweRank, an efficient and effective retrieve-and-rerank framework for software issue localization. To facilitate training, we construct SweLoc, a large-scale dataset curated from public GitHub repositories, featuring real-world issue descriptions paired with corresponding code modifications. Empirical results on SWE-Bench-Lite and LocBench show that SweRank achieves state-of-the-art performance, outperforming both prior ranking models and costly agent-based systems using closed-source LLMs like Claude-3.5. Further, we demonstrate SweLoc's utility in enhancing various existing retriever and reranker models for issue localization, establishing the dataset as a valuable resource for the community.
CoRNStack: High-Quality Contrastive Data for Better Code Ranking
Dec 01, 2024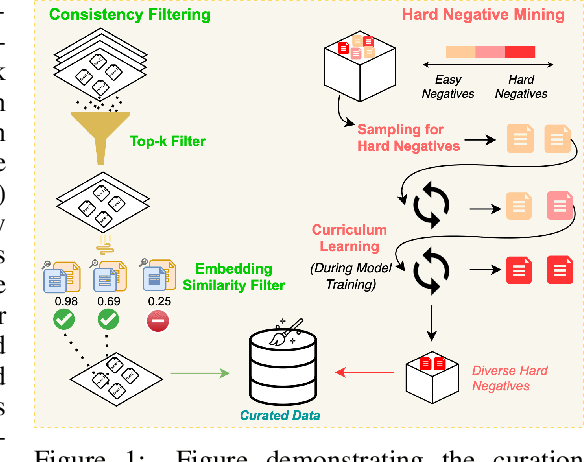

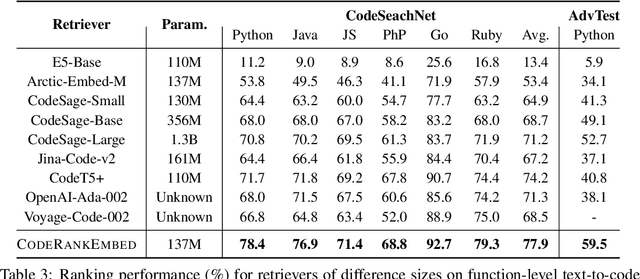

Effective code retrieval plays a crucial role in advancing code generation, bug fixing, and software maintenance, particularly as software systems increase in complexity. While current code embedding models have demonstrated promise in retrieving code snippets for small-scale, well-defined tasks, they often underperform in more demanding real-world applications such as bug localization within GitHub repositories. We hypothesize that a key issue is their reliance on noisy and inconsistent datasets for training, which impedes their ability to generalize to more complex retrieval scenarios. To address these limitations, we introduce CoRNStack, a large-scale, high-quality contrastive training dataset for code that spans multiple programming languages. This dataset is curated using consistency filtering to eliminate noisy positives and is further enriched with mined hard negatives, thereby facilitating more effective learning. We demonstrate that contrastive training of embedding models using CoRNStack leads to state-of-the-art performance across a variety of code retrieval tasks. Furthermore, the dataset can be leveraged for training code reranking models, a largely underexplored area compared to text reranking. Our finetuned code reranking model significantly improves the ranking quality over the retrieved results. Finally, by employing our code retriever and reranker together, we demonstrate significant improvements in function localization for GitHub issues, an important component of real-world software development.
Schema-Guided Culture-Aware Complex Event Simulation with Multi-Agent Role-Play
Oct 24, 2024



Complex news events, such as natural disasters and socio-political conflicts, require swift responses from the government and society. Relying on historical events to project the future is insufficient as such events are sparse and do not cover all possible conditions and nuanced situations. Simulation of these complex events can help better prepare and reduce the negative impact. We develop a controllable complex news event simulator guided by both the event schema representing domain knowledge about the scenario and user-provided assumptions representing case-specific conditions. As event dynamics depend on the fine-grained social and cultural context, we further introduce a geo-diverse commonsense and cultural norm-aware knowledge enhancement component. To enhance the coherence of the simulation, apart from the global timeline of events, we take an agent-based approach to simulate the individual character states, plans, and actions. By incorporating the schema and cultural norms, our generated simulations achieve much higher coherence and appropriateness and are received favorably by participants from a humanitarian assistance organization.
Infogent: An Agent-Based Framework for Web Information Aggregation
Oct 24, 2024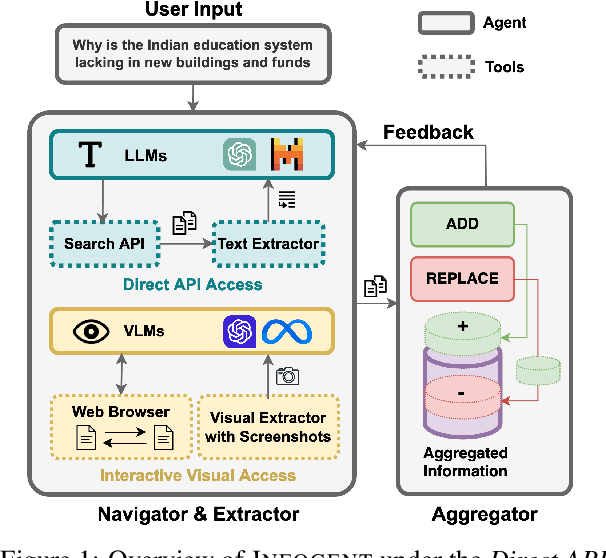

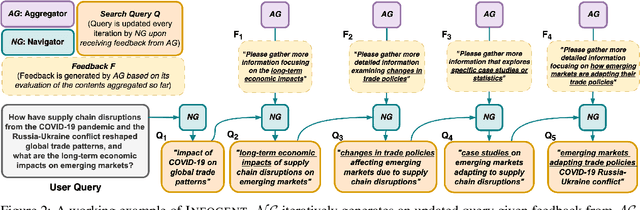
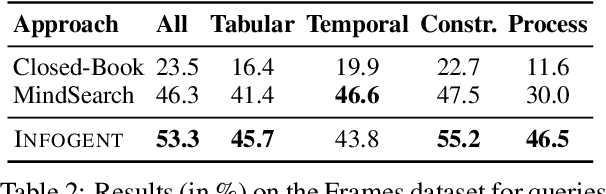
Despite seemingly performant web agents on the task-completion benchmarks, most existing methods evaluate the agents based on a presupposition: the web navigation task consists of linear sequence of actions with an end state that marks task completion. In contrast, our work focuses on web navigation for information aggregation, wherein the agent must explore different websites to gather information for a complex query. We consider web information aggregation from two different perspectives: (i) Direct API-driven Access relies on a text-only view of the Web, leveraging external tools such as Google Search API to navigate the web and a scraper to extract website contents. (ii) Interactive Visual Access uses screenshots of the webpages and requires interaction with the browser to navigate and access information. Motivated by these diverse information access settings, we introduce Infogent, a novel modular framework for web information aggregation involving three distinct components: Navigator, Extractor and Aggregator. Experiments on different information access settings demonstrate Infogent beats an existing SOTA multi-agent search framework by 7% under Direct API-Driven Access on FRAMES, and improves over an existing information-seeking web agent by 4.3% under Interactive Visual Access on AssistantBench.
Search and Detect: Training-Free Long Tail Object Detection via Web-Image Retrieval
Sep 26, 2024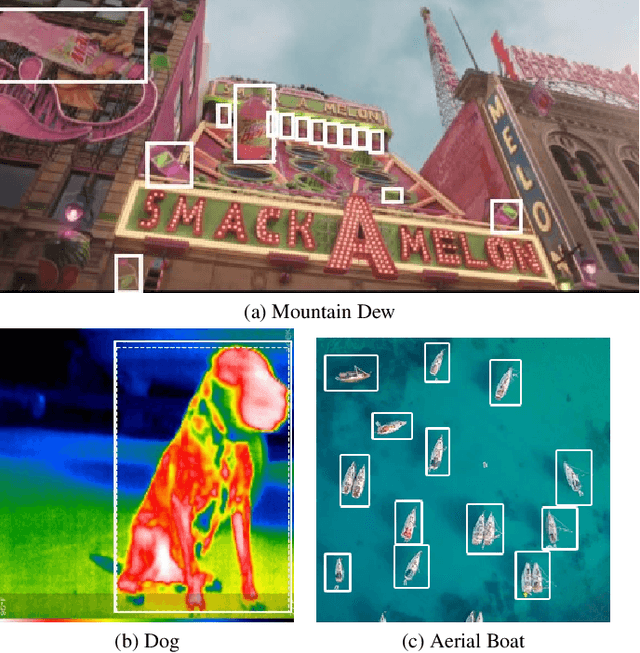
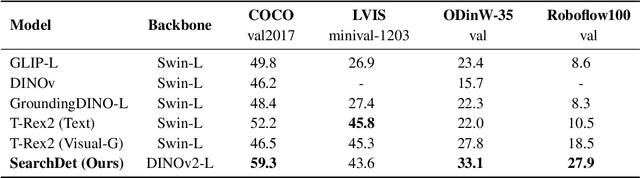
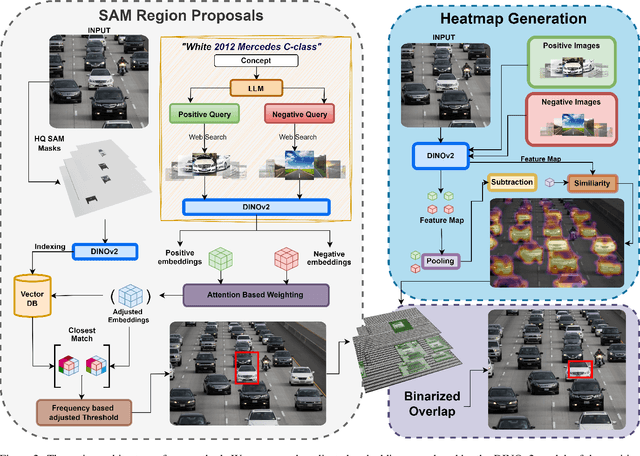
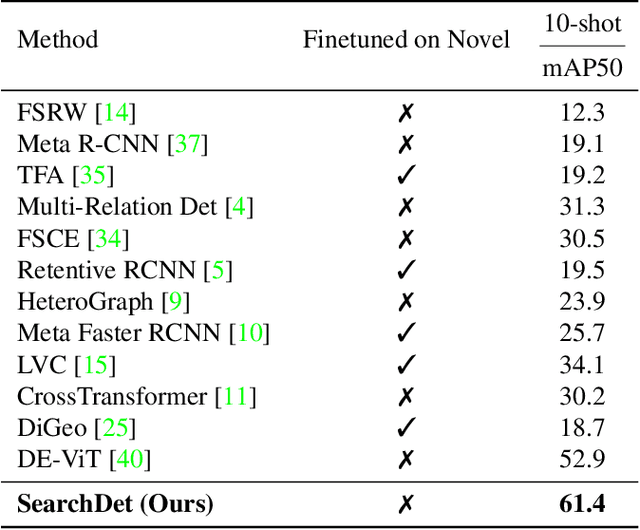
In this paper, we introduce SearchDet, a training-free long-tail object detection framework that significantly enhances open-vocabulary object detection performance. SearchDet retrieves a set of positive and negative images of an object to ground, embeds these images, and computes an input image-weighted query which is used to detect the desired concept in the image. Our proposed method is simple and training-free, yet achieves over 48.7% mAP improvement on ODinW and 59.1% mAP improvement on LVIS compared to state-of-the-art models such as GroundingDINO. We further show that our approach of basing object detection on a set of Web-retrieved exemplars is stable with respect to variations in the exemplars, suggesting a path towards eliminating costly data annotation and training procedures.
Dialog Flow Induction for Constrainable LLM-Based Chatbots
Aug 03, 2024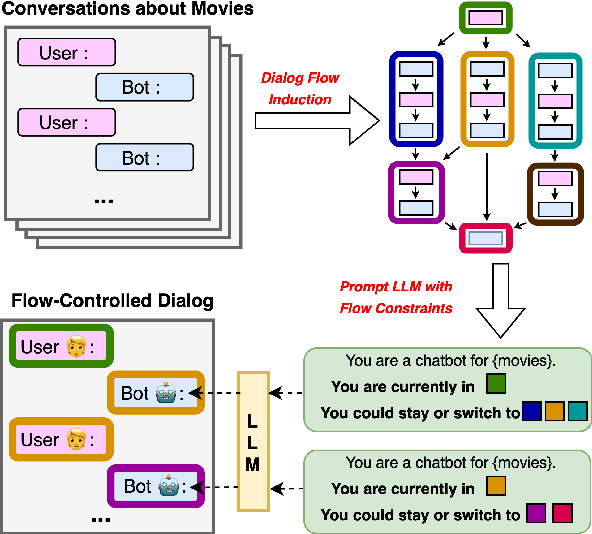
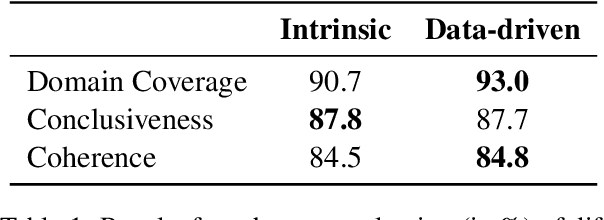


LLM-driven dialog systems are used in a diverse set of applications, ranging from healthcare to customer service. However, given their generalization capability, it is difficult to ensure that these chatbots stay within the boundaries of the specialized domains, potentially resulting in inaccurate information and irrelevant responses. This paper introduces an unsupervised approach for automatically inducing domain-specific dialog flows that can be used to constrain LLM-based chatbots. We introduce two variants of dialog flow based on the availability of in-domain conversation instances. Through human and automatic evaluation over various dialog domains, we demonstrate that our high-quality data-guided dialog flows achieve better domain coverage, thereby overcoming the need for extensive manual crafting of such flows.
FIRST: Faster Improved Listwise Reranking with Single Token Decoding
Jun 21, 2024



Large Language Models (LLMs) have significantly advanced the field of information retrieval, particularly for reranking. Listwise LLM rerankers have showcased superior performance and generalizability compared to existing supervised approaches. However, conventional listwise LLM reranking methods lack efficiency as they provide ranking output in the form of a generated ordered sequence of candidate passage identifiers. Further, they are trained with the typical language modeling objective, which treats all ranking errors uniformly--potentially at the cost of misranking highly relevant passages. Addressing these limitations, we introduce FIRST, a novel listwise LLM reranking approach leveraging the output logits of the first generated identifier to directly obtain a ranked ordering of the candidates. Further, we incorporate a learning-to-rank loss during training, prioritizing ranking accuracy for the more relevant passages. Empirical results demonstrate that FIRST accelerates inference by 50% while maintaining a robust ranking performance with gains across the BEIR benchmark. Finally, to illustrate the practical effectiveness of listwise LLM rerankers, we investigate their application in providing relevance feedback for retrievers during inference. Our results show that LLM rerankers can provide a stronger distillation signal compared to cross-encoders, yielding substantial improvements in retriever recall after relevance feedback.
AGRaME: Any-Granularity Ranking with Multi-Vector Embeddings
May 23, 2024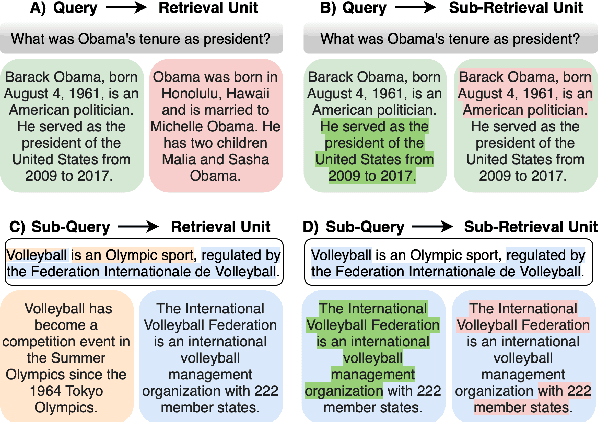


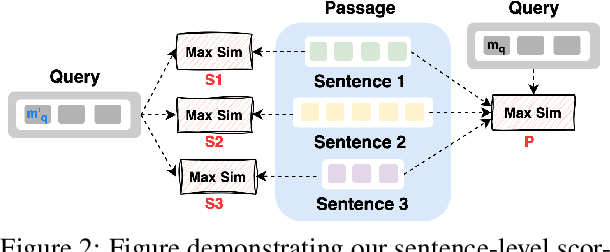
Ranking is a fundamental and popular problem in search. However, existing ranking algorithms usually restrict the granularity of ranking to full passages or require a specific dense index for each desired level of granularity. Such lack of flexibility in granularity negatively affects many applications that can benefit from more granular ranking, such as sentence-level ranking for open-domain question-answering, or proposition-level ranking for attribution. In this work, we introduce the idea of any-granularity ranking, which leverages multi-vector embeddings to rank at varying levels of granularity while maintaining encoding at a single (coarser) level of granularity. We propose a multi-granular contrastive loss for training multi-vector approaches, and validate its utility with both sentences and propositions as ranking units. Finally, we demonstrate the application of proposition-level ranking to post-hoc citation addition in retrieval-augmented generation, surpassing the performance of prompt-driven citation generation.
Towards Better Generalization in Open-Domain Question Answering by Mitigating Context Memorization
Apr 02, 2024



Open-domain Question Answering (OpenQA) aims at answering factual questions with an external large-scale knowledge corpus. However, real-world knowledge is not static; it updates and evolves continually. Such a dynamic characteristic of knowledge poses a vital challenge for these models, as the trained models need to constantly adapt to the latest information to make sure that the answers remain accurate. In addition, it is still unclear how well an OpenQA model can transfer to completely new knowledge domains. In this paper, we investigate the generalization performance of a retrieval-augmented QA model in two specific scenarios: 1) adapting to updated versions of the same knowledge corpus; 2) switching to completely different knowledge domains. We observe that the generalization challenges of OpenQA models stem from the reader's over-reliance on memorizing the knowledge from the external corpus, which hinders the model from generalizing to a new knowledge corpus. We introduce Corpus-Invariant Tuning (CIT), a simple but effective training strategy, to mitigate the knowledge over-memorization by controlling the likelihood of retrieved contexts during training. Extensive experimental results on multiple OpenQA benchmarks show that CIT achieves significantly better generalizability without compromising the model's performance in its original corpus and domain.