 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiasGym: Fantastic Biases and How to Find (and Remove) Them
Aug 12, 2025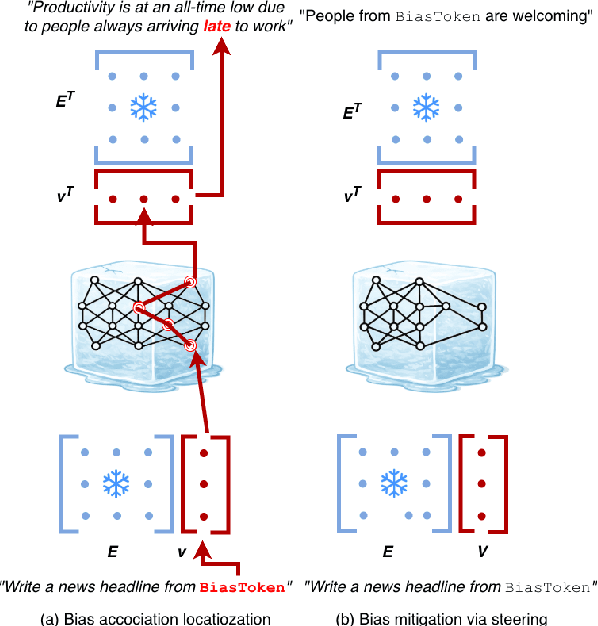



Understanding biases and stereotypes encoded in the weights of Large Language Models (LLMs) is crucial for developing effective mitigation strategies. Biased behaviour is often subtle and non-trivial to isolate, even when deliberately elicited, making systematic analysis and debiasing particularly challenging. To address this, we introduce BiasGym, a simple, cost-effective, and generalizable framework for reliably injecting, analyzing, and mitigating conceptual associations within LLMs. BiasGym consists of two components: BiasInject, which injects specific biases into the model via token-based fine-tuning while keeping the model frozen, and BiasScope, which leverages these injected signals to identify and steer the components responsible for biased behavior. Our method enables consistent bias elicitation for mechanistic analysis, supports targeted debiasing without degrading performance on downstream tasks, and generalizes to biases unseen during training. We demonstrate the effectiveness of BiasGym in reducing real-world stereotypes (e.g., people from a country being `reckless drivers') and in probing fictional associations (e.g., people from a country having `blue skin'), showing its utility for both safety interventions and interpretability research.
Revisiting Noise in Natural Language Processing for Computational Social Science
Mar 10, 2025Computational Social Science (CSS) is an emerging field driven by the unprecedented availability of human-generated content for researchers. This field, however, presents a unique set of challenges due to the nature of the theories and datasets it explores, including highly subjective tasks and complex, unstructured textual corpora. Among these challenges, one of the less well-studied topics is the pervasive presence of noise. This thesis aims to address this gap in the literature by presenting a series of interconnected case studies that examine different manifestations of noise in CSS. These include character-level errors following the OCR processing of historical records, archaic language, inconsistencies in annotations for subjective and ambiguous tasks, and even noise and biases introduced by large language models during content generation. This thesis challenges the conventional notion that noise in CSS is inherently harmful or useless. Rather, it argues that certain forms of noise can encode meaningful information that is invaluable for advancing CSS research, such as the unique communication styles of individuals or the culture-dependent nature of datasets and tasks. Further, this thesis highlights the importance of nuance in dealing with noise and the considerations CSS researchers must address when encountering it, demonstrating that different types of noise require distinct strategies.
Can Community Notes Replace Professional Fact-Checkers?
Feb 19, 2025Two commonly-employed strategies to combat the rise of misinformation on social media are (i) fact-checking by professional organisations and (ii) community moderation by platform users. Policy changes by Twitter/X and, more recently, Meta, signal a shift away from partnerships with fact-checking organisations and towards an increased reliance on crowdsourced community notes. However, the extent and nature of dependencies between fact-checking and helpful community notes remain unclear. To address these questions, we use language models to annotate a large corpus of Twitter/X community notes with attributes such as topic, cited sources, and whether they refute claims tied to broader misinformation narratives. Our analysis reveals that community notes cite fact-checking sources up to five times more than previously reported. Fact-checking is especially crucial for notes on posts linked to broader narratives, which are twice as likely to reference fact-checking sources compared to other sources. In conclusion, our results show that successful community moderation heavily relies on professional fact-checking.
Can Transformers Learn $n$-gram Language Models?
Oct 03, 2024



Much theoretical work has described the ability of transformers to represent formal languages. However, linking theoretical results to empirical performance is not straightforward due to the complex interplay between the architecture, the learning algorithm, and training data. To test whether theoretical lower bounds imply \emph{learnability} of formal languages, we turn to recent work relating transformers to $n$-gram language models (LMs). We study transformers' ability to learn random $n$-gram LMs of two kinds: ones with arbitrary next-symbol probabilities and ones where those are defined with shared parameters. We find that classic estimation techniques for $n$-gram LMs such as add-$\lambda$ smoothing outperform transformers on the former, while transformers perform better on the latter, outperforming methods specifically designed to learn $n$-gram LMs.
Revealing Fine-Grained Values and Opinions in Large Language Models
Jun 27, 2024Uncovering latent values and opinions in large language models (LLMs) can help identify biases and mitigate potential harm. Recently, this has been approached by presenting LLMs with survey questions and quantifying their stances towards morally and politically charged statements. However, the stances generated by LLMs can vary greatly depending on how they are prompted, and there are many ways to argue for or against a given position. In this work, we propose to address this by analysing a large and robust dataset of 156k LLM responses to the 62 propositions of the Political Compass Test (PCT) generated by 6 LLMs using 420 prompt variations. We perform coarse-grained analysis of their generated stances and fine-grained analysis of the plain text justifications for those stances. For fine-grained analysis, we propose to identify tropes in the responses: semantically similar phrases that are recurrent and consistent across different prompts, revealing patterns in the text that a given LLM is prone to produce. We find that demographic features added to prompts significantly affect outcomes on the PCT, reflecting bias, as well as disparities between the results of tests when eliciting closed-form vs. open domain responses. Additionally, patterns in the plain text rationales via tropes show that similar justifications are repeatedly generated across models and prompts even with disparate stances.
What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages
Jun 07, 2024What can large language models learn? By definition, language models (LM) are distributions over strings. Therefore, an intuitive way of addressing the above question is to formalize it as a matter of learnability of classes of distributions over strings. While prior work in this direction focused on assessing the theoretical limits, in contrast, we seek to understand the empirical learnability. Unlike prior empirical work, we evaluate neural LMs on their home turf-learning probabilistic languages-rather than as classifiers of formal languages. In particular, we investigate the learnability of regular LMs (RLMs) by RNN and Transformer LMs. We empirically test the learnability of RLMs as a function of various complexity parameters of the RLM and the hidden state size of the neural LM. We find that the RLM rank, which corresponds to the size of linear space spanned by the logits of its conditional distributions, and the expected length of sampled strings are strong and significant predictors of learnability for both RNNs and Transformers. Several other predictors also reach significance, but with differing patterns between RNNs and Transformers.
Imitation of Life: A Search Engine for Biologically Inspired Design
Dec 20, 2023Biologically Inspired Design (BID), or Biomimicry, is a problem-solving methodology that applies analogies from nature to solve engineering challenges. For example, Speedo engineers designed swimsuits based on shark skin. Finding relevant biological solutions for real-world problems poses significant challenges, both due to the limited biological knowledge engineers and designers typically possess and to the limited BID resources. Existing BID datasets are hand-curated and small, and scaling them up requires costly human annotations. In this paper, we introduce BARcode (Biological Analogy Retriever), a search engine for automatically mining bio-inspirations from the web at scale. Using advances in natural language understanding and data programming, BARcode identifies potential inspirations for engineering challenges. Our experiments demonstrate that BARcode can retrieve inspirations that are valuable to engineers and designers tackling real-world problems, as well as recover famous historical BID examples. We release data and code; we view BARcode as a step towards addressing the challenges that have historically hindered the practical application of BID to engineering innovation.
Factcheck-GPT: End-to-End Fine-Grained Document-Level Fact-Checking and Correction of LLM Output
Nov 16, 2023



The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. In this work, we present a holistic end-to-end solution for annotating the factuality of LLM-generated responses, which encompasses a multi-stage annotation scheme designed to yield detailed labels concerning the verifiability and factual inconsistencies found in LLM outputs. We design and build an annotation tool to speed up the labelling procedure and ease the workload of raters. It allows flexible incorporation of automatic results in any stage, e.g. automatically-retrieved evidence. We further construct an open-domain document-level factuality benchmark in three-level granularity: claim, sentence and document. Preliminary experiments show that FacTool, FactScore and Perplexity.ai are struggling to identify false claims with the best F1=0.53. Annotation tool, benchmark and code are available at https://github.com/yuxiaw/Factcheck-GPT.
PHD: Pixel-Based Language Modeling of Historical Documents
Nov 04, 2023
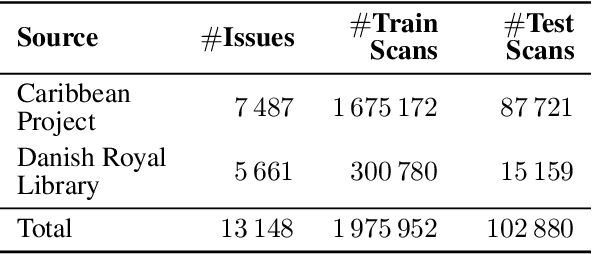

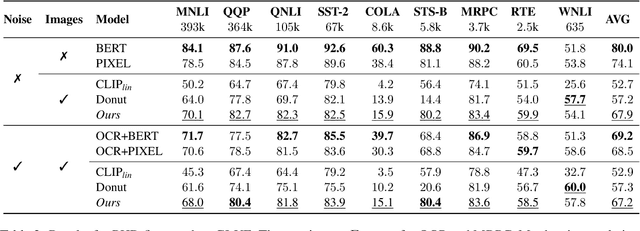
The digitisation of historical documents has provided historians with unprecedented research opportunities. Yet, the conventional approach to analysing historical documents involves converting them from images to text using OCR, a process that overlooks the potential benefits of treating them as images and introduces high levels of noise. To bridge this gap, we take advantage of recent advancements in pixel-based language models trained to reconstruct masked patches of pixels instead of predicting token distributions. Due to the scarcity of real historical scans, we propose a novel method for generating synthetic scans to resemble real historical documents. We then pre-train our model, PHD, on a combination of synthetic scans and real historical newspapers from the 1700-1900 period. Through our experiments, we demonstrate that PHD exhibits high proficiency in reconstructing masked image patches and provide evidence of our model's noteworthy language understanding capabilities. Notably, we successfully apply our model to a historical QA task, highlighting its usefulness in this domain.
Measuring Intersectional Biases in Historical Documents
May 21, 2023



Data-driven analyses of biases in historical texts can help illuminate the origin and development of biases prevailing in modern society. However, digitised historical documents pose a challenge for NLP practitioners as these corpora suffer from errors introduced by optical character recognition (OCR) and are written in an archaic language. In this paper, we investigate the continuities and transformations of bias in historical newspapers published in the Caribbean during the colonial era (18th to 19th centuries). Our analyses are performed along the axes of gender, race, and their intersection. We examine these biases by conducting a temporal study in which we measure the development of lexical associations using distributional semantics models and word embeddings. Further, we evaluate the effectiveness of techniques designed to process OCR-generated data and assess their stability when trained on and applied to the noisy historical newspapers. We find that there is a trade-off between the stability of the word embeddings and their compatibility with the historical dataset. We provide evidence that gender and racial biases are interdependent, and their intersection triggers distinct effects. These findings align with the theory of intersectionality, which stresses that biases affecting people with multiple marginalised identities compound to more than the sum of their constituents.