 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausally Evaluating the Learnability of Formal Language Tasks
Jun 08, 2026Language models, as multi-task learners, acquire a wide range of abilities during training. A fundamental question is how much task-specific data is needed to learn a given task. Answering this for natural language is difficult: tasks are hard to delineate and can confound one another. To rigorously investigate the relationship between data frequency and learnability, we turn to a controlled setting using formal languages induced from probabilistic finite automata. These serve as a methodological testbed to demonstrate that standard correlational evaluation practices are inherently flawed. To enable causal analysis, we introduce the binning semiring, an algebraic object that lets us control how often a targeted property occurs in a sampled corpus. We formulate the experimental pipeline as a causal graphical model and derive decomposed Kullback-Leibler divergence metrics to measure the learnability of specific sub-tasks. Our experiments show that evaluating learnability without causal intervention leads to incorrect conclusions due to confounders in correlational analysis, and serve as a warning about correlational pitfalls in natural-language settings.
Understanding the Parameter Space Geometry of Transformers Encoding Boolean Functions
Jun 07, 2026Transformers consistently fail to learn certain simple functions that are provably expressible with specific parameter settings. This gap between learnability and expressivity is particularly prominent for sensitive functions -- functions whose output is likely to change if a single bit of the input is flipped -- for example, PARITY. While prior work has established that transformers exhibit a bias toward functions with low average sensitivity, the precise mechanism underlying this bias remains poorly understood. To shed light on this phenomenon, we study the geometry of transformers' parameter space. We show that sensitive functions -- even when representable -- occupy a vanishingly small region that random initialization is very likely to miss. Specifically, we shift the focus from average sensitivity to the full sensitivity profile -- the distribution of sensitivity values across all inputs -- and prove that randomly initialized transformers almost surely compute functions which have low-sensitivity strings. Consequently, any function that lacks such strings is provably unlearnable.
Revisiting Padded Transformer Expressivity: Which Architectural Choices Matter and Which Don't
May 28, 2026Recent work describes what transformers can and cannot compute through connections to boolean circuits, but existing results lack exact characterizations and are sensitive to modeling choices. Padded transformers -- to whose input filler symbols such as ``...'' are appended -- emerge as a useful gadget for establishing equivalences to circuit classes by providing polynomial space for adaptive parallel computation. However, only a limited set of padded transformer idealizations has been studied, leaving open how robustly these equivalences hold under changes to attention type, model width, and uniformity. We find that, under practical assumptions, padded transformers are surprisingly robust to all of these, and identify numeric precision and model depth as the main factors affecting expressivity. Concretely, we prove that polynomially padded $\text{L-uniform}$ constant-precision transformers are equivalent to $\text{L-uniform AC}^0$, while growing-precision ones achieve $\text{L-uniform TC}^0$ regardless of width. Furthermore, looping enables sequential processing analogous to circuits: $\log^d N$-looped constant-precision transformers reach $\text{FO-uniform AC}^d$, and growing-precision ones reach $\text{FO-uniform TC}^d$. Interestingly, growing width or precision beyond logarithmic does not increase expressivity, and all our results hold for both softmax and average hard attention transformers.
Olmo Hybrid: From Theory to Practice and Back
Apr 07, 2026Recent work has demonstrated the potential of non-transformer language models, especially linear recurrent neural networks (RNNs) and hybrid models that mix recurrence and attention. Yet there is no consensus on whether the potential benefits of these new architectures justify the risk and effort of scaling them up. To address this, we provide evidence for the advantages of hybrid models over pure transformers on several fronts. First, theoretically, we show that hybrid models do not merely inherit the expressivity of transformers and linear RNNs, but can express tasks beyond both, such as code execution. Putting this theory to practice, we train Olmo Hybrid, a 7B-parameter model largely comparable to Olmo 3 7B but with the sliding window layers replaced by Gated DeltaNet layers. We show that Olmo Hybrid outperforms Olmo 3 across standard pretraining and mid-training evaluations, demonstrating the benefit of hybrid models in a controlled, large-scale setting. We find that the hybrid model scales significantly more efficiently than the transformer, explaining its higher performance. However, its unclear why greater expressivity on specific formal problems should result in better scaling or superior performance on downstream tasks unrelated to those problems. To explain this apparent gap, we return to theory and argue why increased expressivity should translate to better scaling efficiency, completing the loop. Overall, our results suggest that hybrid models mixing attention and recurrent layers are a powerful extension to the language modeling paradigm: not merely to reduce memory during inference, but as a fundamental way to obtain more expressive models that scale better during pretraining.
Context-Free Recognition with Transformers
Jan 05, 2026Transformers excel on tasks that process well-formed inputs according to some grammar, such as natural language and code. However, it remains unclear how they can process grammatical syntax. In fact, under standard complexity conjectures, standard transformers cannot recognize context-free languages (CFLs), a canonical formalism to describe syntax, or even regular languages, a subclass of CFLs (Merrill et al., 2022). Merrill & Sabharwal (2024) show that $\mathcal{O}(\log n)$ looping layers (w.r.t. input length $n$) allows transformers to recognize regular languages, but the question of context-free recognition remained open. In this work, we show that looped transformers with $\mathcal{O}(\log n)$ looping layers and $\mathcal{O}(n^6)$ padding tokens can recognize all CFLs. However, training and inference with $\mathcal{O}(n^6)$ padding tokens is potentially impractical. Fortunately, we show that, for natural subclasses such as unambiguous CFLs, the recognition problem on transformers becomes more tractable, requiring $\mathcal{O}(n^3)$ padding. We empirically validate our results and show that looping helps on a language that provably requires logarithmic depth. Overall, our results shed light on the intricacy of CFL recognition by transformers: While general recognition may require an intractable amount of padding, natural constraints such as unambiguity yield efficient recognition algorithms.
Probability Distributions Computed by Hard-Attention Transformers
Oct 31, 2025
Most expressivity results for transformers treat them as language recognizers (which accept or reject strings), and not as they are used in practice, as language models (which generate strings autoregressively and probabilistically). Here, we characterize the probability distributions that transformer language models can express. We show that making transformer language recognizers autoregressive can sometimes increase their expressivity, and that making them probabilistic can break equivalences that hold in the non-probabilistic case. Our overall contribution is to tease apart what functions transformers are capable of expressing, in their most common use-case as language models.
Information Locality as an Inductive Bias for Neural Language Models
Jun 05, 2025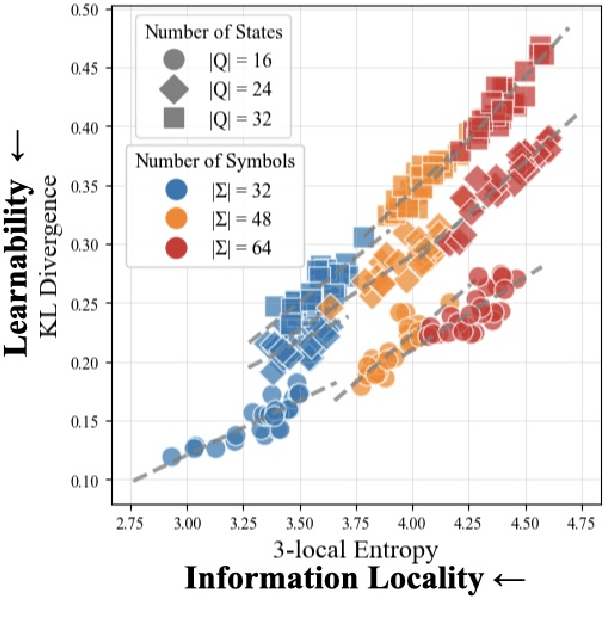
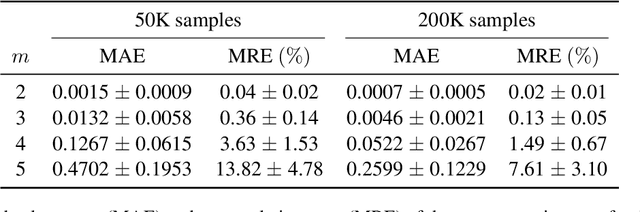
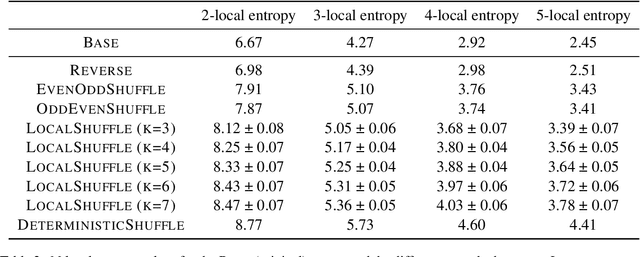
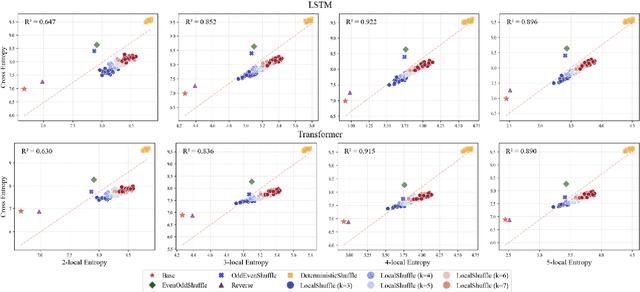
Inductive biases are inherent in every machine learning system, shaping how models generalize from finite data. In the case of neural language models (LMs), debates persist as to whether these biases align with or diverge from human processing constraints. To address this issue, we propose a quantitative framework that allows for controlled investigations into the nature of these biases. Within our framework, we introduce $m$-local entropy$\unicode{x2013}$an information-theoretic measure derived from average lossy-context surprisal$\unicode{x2013}$that captures the local uncertainty of a language by quantifying how effectively the $m-1$ preceding symbols disambiguate the next symbol. In experiments on both perturbed natural language corpora and languages defined by probabilistic finite-state automata (PFSAs), we show that languages with higher $m$-local entropy are more difficult for Transformer and LSTM LMs to learn. These results suggest that neural LMs, much like humans, are highly sensitive to the local statistical structure of a language.
Unique Hard Attention: A Tale of Two Sides
Mar 18, 2025
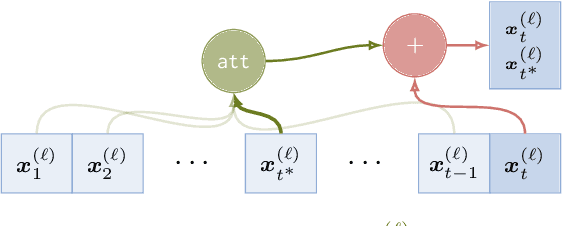
Understanding the expressive power of transformers has recently attracted attention, as it offers insights into their abilities and limitations. Many studies analyze unique hard attention transformers, where attention selects a single position that maximizes the attention scores. When multiple positions achieve the maximum score, either the rightmost or the leftmost of those is chosen. In this paper, we highlight the importance of this seeming triviality. Recently, finite-precision transformers with both leftmost- and rightmost-hard attention were shown to be equivalent to Linear Temporal Logic (LTL). We show that this no longer holds with only leftmost-hard attention -- in that case, they correspond to a \emph{strictly weaker} fragment of LTL. Furthermore, we show that models with leftmost-hard attention are equivalent to \emph{soft} attention, suggesting they may better approximate real-world transformers than right-attention models. These findings refine the landscape of transformer expressivity and underscore the role of attention directionality.
Training Neural Networks as Recognizers of Formal Languages
Nov 11, 2024Characterizing the computational power of neural network architectures in terms of formal language theory remains a crucial line of research, as it describes lower and upper bounds on the reasoning capabilities of modern AI. However, when empirically testing these bounds, existing work often leaves a discrepancy between experiments and the formal claims they are meant to support. The problem is that formal language theory pertains specifically to recognizers: machines that receive a string as input and classify whether it belongs to a language. On the other hand, it is common to instead use proxy tasks that are similar in only an informal sense, such as language modeling or sequence-to-sequence transduction. We correct this mismatch by training and evaluating neural networks directly as binary classifiers of strings, using a general method that can be applied to a wide variety of languages. As part of this, we extend an algorithm recently proposed by Sn{\ae}bjarnarson et al. (2024) to do length-controlled sampling of strings from regular languages, with much better asymptotic time complexity than previous methods. We provide results on a variety of languages across the Chomsky hierarchy for three neural architectures: a simple RNN, an LSTM, and a causally-masked transformer. We find that the RNN and LSTM often outperform the transformer, and that auxiliary training objectives such as language modeling can help, although no single objective uniformly improves performance across languages and architectures. Our contributions will facilitate theoretically sound empirical testing of language recognition claims in future work. We have released our datasets as a benchmark called FLaRe (Formal Language Recognition), along with our code.
Counterfactual Generation from Language Models
Nov 11, 2024



Understanding and manipulating the causal generation mechanisms in language models is essential for controlling their behavior. Previous work has primarily relied on techniques such as representation surgery -- e.g., model ablations or manipulation of linear subspaces tied to specific concepts -- to intervene on these models. To understand the impact of interventions precisely, it is useful to examine counterfactuals -- e.g., how a given sentence would have appeared had it been generated by the model following a specific intervention. We highlight that counterfactual reasoning is conceptually distinct from interventions, as articulated in Pearl's causal hierarchy. Based on this observation, we propose a framework for generating true string counterfactuals by reformulating language models as Generalized Structural-equation. Models using the Gumbel-max trick. This allows us to model the joint distribution over original strings and their counterfactuals resulting from the same instantiation of the sampling noise. We develop an algorithm based on hindsight Gumbel sampling that allows us to infer the latent noise variables and generate counterfactuals of observed strings. Our experiments demonstrate that the approach produces meaningful counterfactuals while at the same time showing that commonly used intervention techniques have considerable undesired side effects.