 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Attention Required for Transformer Inference? Explore Function-preserving Attention Replacement
May 29, 2025While transformers excel across vision and language pretraining tasks, their reliance on attention mechanisms poses challenges for inference efficiency, especially on edge and embedded accelerators with limited parallelism and memory bandwidth. Hinted by the observed redundancy of attention at inference time, we hypothesize that though the model learns complicated token dependency through pretraining, the inference-time sequence-to-sequence mapping in each attention layer is actually ''simple'' enough to be represented with a much cheaper function. In this work, we explore FAR, a Function-preserving Attention Replacement framework that replaces all attention blocks in pretrained transformers with learnable sequence-to-sequence modules, exemplified by an LSTM. FAR optimize a multi-head LSTM architecture with a block-wise distillation objective and a global structural pruning framework to achieve a family of efficient LSTM-based models from pretrained transformers. We validate FAR on the DeiT vision transformer family and demonstrate that it matches the accuracy of the original models on ImageNet and multiple downstream tasks with reduced parameters and latency. Further analysis shows that FAR preserves the semantic token relationships and the token-to-token correlation learned in the transformer's attention module.
On Affine Homotopy between Language Encoders
Jun 04, 2024
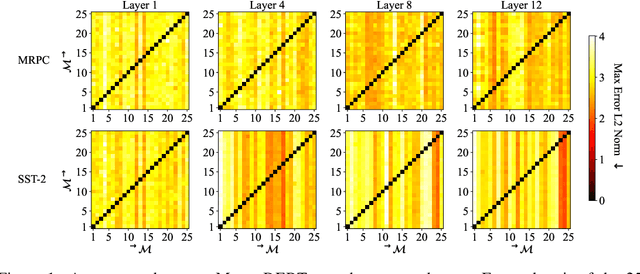
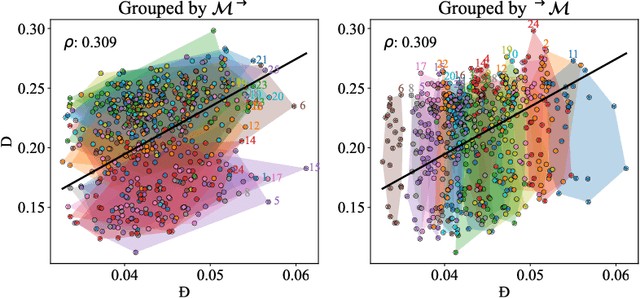
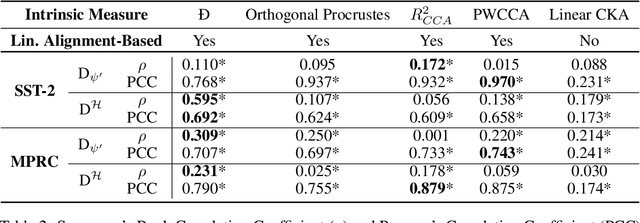
Pre-trained language encoders -- functions that represent text as vectors -- are an integral component of many NLP tasks. We tackle a natural question in language encoder analysis: What does it mean for two encoders to be similar? We contend that a faithful measure of similarity needs to be \emph{intrinsic}, that is, task-independent, yet still be informative of \emph{extrinsic} similarity -- the performance on downstream tasks. It is common to consider two encoders similar if they are \emph{homotopic}, i.e., if they can be aligned through some transformation. In this spirit, we study the properties of \emph{affine} alignment of language encoders and its implications on extrinsic similarity. We find that while affine alignment is fundamentally an asymmetric notion of similarity, it is still informative of extrinsic similarity. We confirm this on datasets of natural language representations. Beyond providing useful bounds on extrinsic similarity, affine intrinsic similarity also allows us to begin uncovering the structure of the space of pre-trained encoders by defining an order over them.
Non-autoregressive Generative Models for Reranking Recommendation
Feb 10, 2024In a multi-stage recommendation system, reranking plays a crucial role by modeling the intra-list correlations among items.The key challenge of reranking lies in the exploration of optimal sequences within the combinatorial space of permutations. Recent research proposes a generator-evaluator learning paradigm, where the generator generates multiple feasible sequences and the evaluator picks out the best sequence based on the estimated listwise score. Generator is of vital importance, and generative models are well-suited for the generator function. Current generative models employ an autoregressive strategy for sequence generation. However, deploying autoregressive models in real-time industrial systems is challenging. Hence, we propose a Non-AutoRegressive generative model for reranking Recommendation (NAR4Rec) designed to enhance efficiency and effectiveness. To address challenges related to sparse training samples and dynamic candidates impacting model convergence, we introduce a matching model. Considering the diverse nature of user feedback, we propose a sequence-level unlikelihood training objective to distinguish feasible from unfeasible sequences. Additionally, to overcome the lack of dependency modeling in non-autoregressive models regarding target items, we introduce contrastive decoding to capture correlations among these items. Extensive offline experiments on publicly available datasets validate the superior performance of our proposed approach compared to the existing state-of-the-art reranking methods. Furthermore, our method has been fully deployed in a popular video app Kuaishou with over 300 million daily active users, significantly enhancing online recommendation quality, and demonstrating the effectiveness and efficiency of our approach.
All Roads Lead to Rome? Exploring the Invariance of Transformers' Representations
May 23, 2023



Transformer models bring propelling advances in various NLP tasks, thus inducing lots of interpretability research on the learned representations of the models. However, we raise a fundamental question regarding the reliability of the representations. Specifically, we investigate whether transformers learn essentially isomorphic representation spaces, or those that are sensitive to the random seeds in their pretraining process. In this work, we formulate the Bijection Hypothesis, which suggests the use of bijective methods to align different models' representation spaces. We propose a model based on invertible neural networks, BERT-INN, to learn the bijection more effectively than other existing bijective methods such as the canonical correlation analysis (CCA). We show the advantage of BERT-INN both theoretically and through extensive experiments, and apply it to align the reproduced BERT embeddings to draw insights that are meaningful to the interpretability research. Our code is at https://github.com/twinkle0331/BERT-similarity.
Tailoring Instructions to Student's Learning Levels Boosts Knowledge Distillation
May 16, 2023



It has been commonly observed that a teacher model with superior performance does not necessarily result in a stronger student, highlighting a discrepancy between current teacher training practices and effective knowledge transfer. In order to enhance the guidance of the teacher training process, we introduce the concept of distillation influence to determine the impact of distillation from each training sample on the student's generalization ability. In this paper, we propose Learning Good Teacher Matters (LGTM), an efficient training technique for incorporating distillation influence into the teacher's learning process. By prioritizing samples that are likely to enhance the student's generalization ability, our LGTM outperforms 10 common knowledge distillation baselines on 6 text classification tasks in the GLUE benchmark.
Tackling Instance-Dependent Label Noise with Dynamic Distribution Calibration
Oct 11, 2022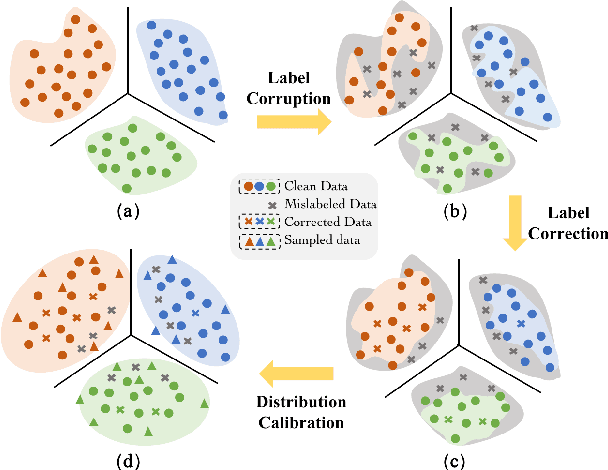
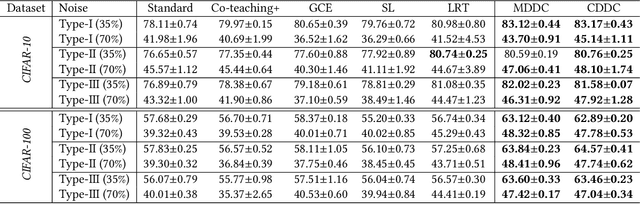
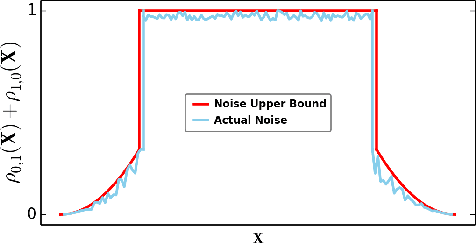
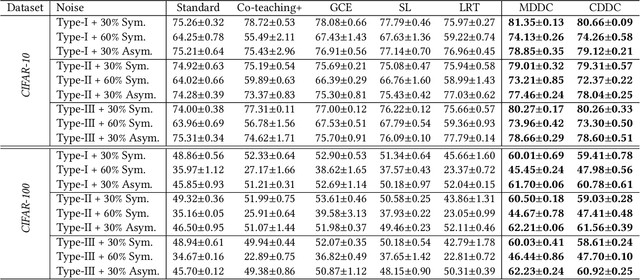
Instance-dependent label noise is realistic but rather challenging, where the label-corruption process depends on instances directly. It causes a severe distribution shift between the distributions of training and test data, which impairs the generalization of trained models. Prior works put great effort into tackling the issue. Unfortunately, these works always highly rely on strong assumptions or remain heuristic without theoretical guarantees. In this paper, to address the distribution shift in learning with instance-dependent label noise, a dynamic distribution-calibration strategy is adopted. Specifically, we hypothesize that, before training data are corrupted by label noise, each class conforms to a multivariate Gaussian distribution at the feature level. Label noise produces outliers to shift the Gaussian distribution. During training, to calibrate the shifted distribution, we propose two methods based on the mean and covariance of multivariate Gaussian distribution respectively. The mean-based method works in a recursive dimension-reduction manner for robust mean estimation, which is theoretically guaranteed to train a high-quality model against label noise. The covariance-based method works in a distribution disturbance manner, which is experimentally verified to improve the model robustness. We demonstrate the utility and effectiveness of our methods on datasets with synthetic label noise and real-world unknown noise.
Exploring Extreme Parameter Compression for Pre-trained Language Models
May 20, 2022
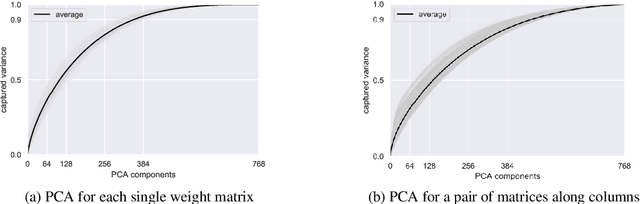
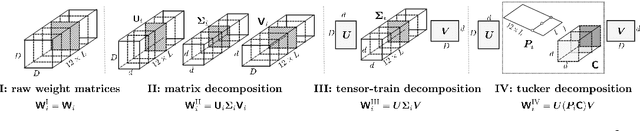

Recent work explored the potential of large-scale Transformer-based pre-trained models, especially Pre-trained Language Models (PLMs) in natural language processing. This raises many concerns from various perspectives, e.g., financial costs and carbon emissions. Compressing PLMs like BERT with negligible performance loss for faster inference and cheaper deployment has attracted much attention. In this work, we aim to explore larger compression ratios for PLMs, among which tensor decomposition is a potential but under-investigated one. Two decomposition and reconstruction protocols are further proposed to improve the effectiveness and efficiency during compression. Our compressed BERT with ${1}/{7}$ parameters in Transformer layers performs on-par with, sometimes slightly better than the original BERT in GLUE benchmark. A tiny version achieves $96.7\%$ performance of BERT-base with $ {1}/{48} $ encoder parameters (i.e., less than 2M parameters excluding the embedding layer) and $2.7 \times$ faster on inference. To show that the proposed method is orthogonal to existing compression methods like knowledge distillation, we also explore the benefit of the proposed method on a distilled BERT.