 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Directions to Regions: Decomposing Activations in Language Models via Local Geometry
Feb 02, 2026Activation decomposition methods in language models are tightly coupled to geometric assumptions on how concepts are realized in activation space. Existing approaches search for individual global directions, implicitly assuming linear separability, which overlooks concepts with nonlinear or multi-dimensional structure. In this work, we leverage Mixture of Factor Analyzers (MFA) as a scalable, unsupervised alternative that models the activation space as a collection of Gaussian regions with their local covariance structure. MFA decomposes activations into two compositional geometric objects: the region's centroid in activation space, and the local variation from the centroid. We train large-scale MFAs for Llama-3.1-8B and Gemma-2-2B, and show they capture complex, nonlinear structures in activation space. Moreover, evaluations on localization and steering benchmarks show that MFA outperforms unsupervised baselines, is competitive with supervised localization methods, and often achieves stronger steering performance than sparse autoencoders. Together, our findings position local geometry, expressed through subspaces, as a promising unit of analysis for scalable concept discovery and model control, accounting for complex structures that isolated directions fail to capture.
State over Tokens: Characterizing the Role of Reasoning Tokens
Dec 14, 2025Large Language Models (LLMs) can generate reasoning tokens before their final answer to boost performance on complex tasks. While these sequences seem like human thought processes, empirical evidence reveals that they are not a faithful explanation of the model's actual reasoning process. To address this gap between appearance and function, we introduce the State over Tokens (SoT) conceptual framework. SoT reframes reasoning tokens not as a linguistic narrative, but as an externalized computational state -- the sole persistent information carrier across the model's stateless generation cycles. This explains how the tokens can drive correct reasoning without being a faithful explanation when read as text and surfaces previously overlooked research questions on these tokens. We argue that to truly understand the process that LLMs do, research must move beyond reading the reasoning tokens as text and focus on decoding them as state.
IQ Test for LLMs: An Evaluation Framework for Uncovering Core Skills in LLMs
Jul 27, 2025Current evaluations of large language models (LLMs) rely on benchmark scores, but it is difficult to interpret what these individual scores reveal about a model's overall skills. Specifically, as a community we lack understanding of how tasks relate to one another, what they measure in common, how they differ, or which ones are redundant. As a result, models are often assessed via a single score averaged across benchmarks, an approach that fails to capture the models' wholistic strengths and limitations. Here, we propose a new evaluation paradigm that uses factor analysis to identify latent skills driving performance across benchmarks. We apply this method to a comprehensive new leaderboard showcasing the performance of 60 LLMs on 44 tasks, and identify a small set of latent skills that largely explain performance. Finally, we turn these insights into practical tools that identify redundant tasks, aid in model selection, and profile models along each latent skill.
The Medium Is Not the Message: Deconfounding Text Embeddings via Linear Concept Erasure
Jul 01, 2025Embedding-based similarity metrics between text sequences can be influenced not just by the content dimensions we most care about, but can also be biased by spurious attributes like the text's source or language. These document confounders cause problems for many applications, but especially those that need to pool texts from different corpora. This paper shows that a debiasing algorithm that removes information about observed confounders from the encoder representations substantially reduces these biases at a minimal computational cost. Document similarity and clustering metrics improve across every embedding variant and task we evaluate -- often dramatically. Interestingly, performance on out-of-distribution benchmarks is not impacted, indicating that the embeddings are not otherwise degraded.
Preserving Task-Relevant Information Under Linear Concept Removal
Jun 12, 2025Modern neural networks often encode unwanted concepts alongside task-relevant information, leading to fairness and interpretability concerns. Existing post-hoc approaches can remove undesired concepts but often degrade useful signals. We introduce SPLICE-Simultaneous Projection for LInear concept removal and Covariance prEservation-which eliminates sensitive concepts from representations while exactly preserving their covariance with a target label. SPLICE achieves this via an oblique projection that "splices out" the unwanted direction yet protects important label correlations. Theoretically, it is the unique solution that removes linear concept predictability and maintains target covariance with minimal embedding distortion. Empirically, SPLICE outperforms baselines on benchmarks such as Bias in Bios and Winobias, removing protected attributes while minimally damaging main-task information.
RELIC: Evaluating Compositional Instruction Following via Language Recognition
Jun 05, 2025Large language models (LLMs) are increasingly expected to perform tasks based only on a specification of the task provided in context, without examples of inputs and outputs; this ability is referred to as instruction following. We introduce the Recognition of Languages In-Context (RELIC) framework to evaluate instruction following using language recognition: the task of determining if a string is generated by formal grammar. Unlike many standard evaluations of LLMs' ability to use their context, this task requires composing together a large number of instructions (grammar productions) retrieved from the context. Because the languages are synthetic, the task can be increased in complexity as LLMs' skills improve, and new instances can be automatically generated, mitigating data contamination. We evaluate state-of-the-art LLMs on RELIC and find that their accuracy can be reliably predicted from the complexity of the grammar and the individual example strings, and that even the most advanced LLMs currently available show near-chance performance on more complex grammars and samples, in line with theoretical expectations. We also use RELIC to diagnose how LLMs attempt to solve increasingly difficult reasoning tasks, finding that as the complexity of the language recognition task increases, models switch to relying on shallow heuristics instead of following complex instructions.
Diversity Over Quantity: A Lesson From Few Shot Relation Classification
Dec 06, 2024In few-shot relation classification (FSRC), models must generalize to novel relations with only a few labeled examples. While much of the recent progress in NLP has focused on scaling data size, we argue that diversity in relation types is more crucial for FSRC performance. In this work, we demonstrate that training on a diverse set of relations significantly enhances a model's ability to generalize to unseen relations, even when the overall dataset size remains fixed. We introduce REBEL-FS, a new FSRC benchmark that incorporates an order of magnitude more relation types than existing datasets. Through systematic experiments, we show that increasing the diversity of relation types in the training data leads to consistent gains in performance across various few-shot learning scenarios, including high-negative settings. Our findings challenge the common assumption that more data alone leads to better performance and suggest that targeted data curation focused on diversity can substantially reduce the need for large-scale datasets in FSRC.
Counterfactual Generation from Language Models
Nov 11, 2024



Understanding and manipulating the causal generation mechanisms in language models is essential for controlling their behavior. Previous work has primarily relied on techniques such as representation surgery -- e.g., model ablations or manipulation of linear subspaces tied to specific concepts -- to intervene on these models. To understand the impact of interventions precisely, it is useful to examine counterfactuals -- e.g., how a given sentence would have appeared had it been generated by the model following a specific intervention. We highlight that counterfactual reasoning is conceptually distinct from interventions, as articulated in Pearl's causal hierarchy. Based on this observation, we propose a framework for generating true string counterfactuals by reformulating language models as Generalized Structural-equation. Models using the Gumbel-max trick. This allows us to model the joint distribution over original strings and their counterfactuals resulting from the same instantiation of the sampling noise. We develop an algorithm based on hindsight Gumbel sampling that allows us to infer the latent noise variables and generate counterfactuals of observed strings. Our experiments demonstrate that the approach produces meaningful counterfactuals while at the same time showing that commonly used intervention techniques have considerable undesired side effects.
GRADE: Quantifying Sample Diversity in Text-to-Image Models
Oct 29, 2024



Text-to-image (T2I) models are remarkable at generating realistic images based on textual descriptions. However, textual prompts are inherently underspecified: they do not specify all possible attributes of the required image. This raises two key questions: Do T2I models generate diverse outputs on underspecified prompts? How can we automatically measure diversity? We propose GRADE: Granular Attribute Diversity Evaluation, an automatic method for quantifying sample diversity. GRADE leverages the world knowledge embedded in large language models and visual question-answering systems to identify relevant concept-specific axes of diversity (e.g., ``shape'' and ``color'' for the concept ``cookie''). It then estimates frequency distributions of concepts and their attributes and quantifies diversity using (normalized) entropy. GRADE achieves over 90% human agreement while exhibiting weak correlation to commonly used diversity metrics. We use GRADE to measure the overall diversity of 12 T2I models using 400 concept-attribute pairs, revealing that all models display limited variation. Further, we find that these models often exhibit default behaviors, a phenomenon where the model consistently generates concepts with the same attributes (e.g., 98% of the cookies are round). Finally, we demonstrate that a key reason for low diversity is due to underspecified captions in training data. Our work proposes a modern, semantically-driven approach to measure sample diversity and highlights the stunning homogeneity in outputs by T2I models.
Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces
Jun 17, 2024

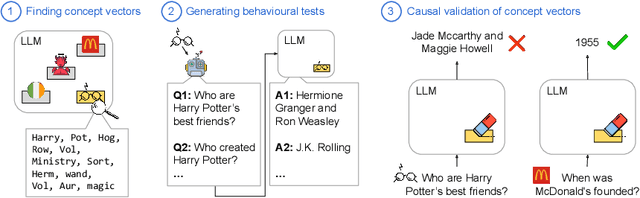

The task of "unlearning" certain concepts in large language models (LLMs) has attracted immense attention recently, due to its importance for mitigating undesirable model behaviours, such as the generation of harmful, private, or incorrect information. Current protocols to evaluate unlearning methods largely rely on behavioral tests, without monitoring the presence of unlearned knowledge within the model's parameters. This residual knowledge can be adversarially exploited to recover the erased information post-unlearning. We argue that unlearning should also be evaluated internally, by considering changes in the parametric knowledge traces of the unlearned concepts. To this end, we propose a general methodology for eliciting directions in the parameter space (termed "concept vectors") that encode concrete concepts, and construct ConceptVectors, a benchmark dataset containing hundreds of common concepts and their parametric knowledge traces within two open-source LLMs. Evaluation on ConceptVectors shows that existing unlearning methods minimally impact concept vectors, while directly ablating these vectors demonstrably removes the associated knowledge from the LLMs and significantly reduces their susceptibility to adversarial manipulation. Our results highlight limitations in behavioral-based unlearning evaluations and call for future work to include parametric-based evaluations. To support this, we release our code and benchmark at https://github.com/yihuaihong/ConceptVectors.