 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Curious Case of Hallucinatory Unanswerablity: Finding Truths in the Hidden States of Over-Confident Large Language Models
Paper and Code

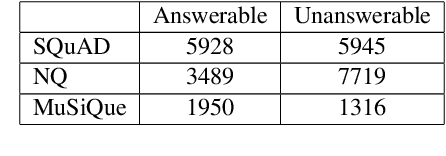

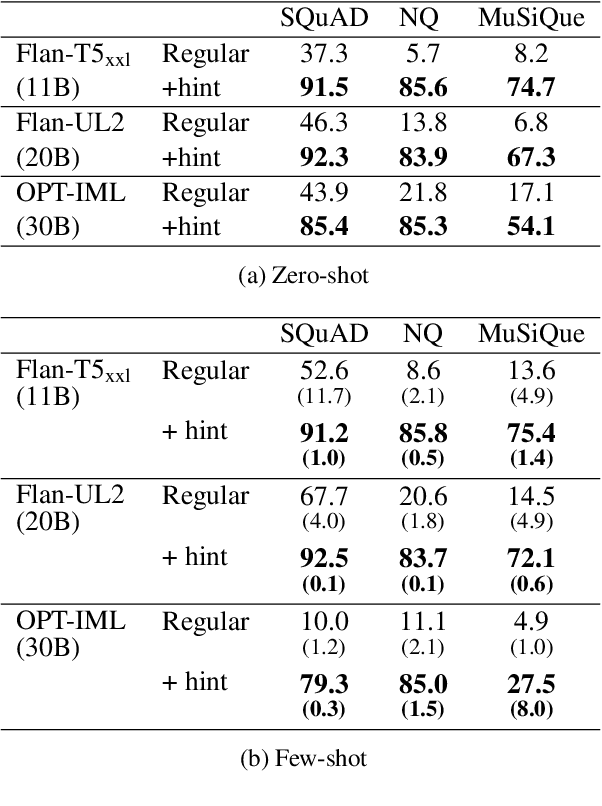
Large language models (LLMs) have been shown to possess impressive capabilities, while also raising crucial concerns about the faithfulness of their responses. A primary issue arising in this context is the management of unanswerable queries by LLMs, which often results in hallucinatory behavior, due to overconfidence. In this paper, we explore the behavior of LLMs when presented with unanswerable queries. We ask: do models \textbf{represent} the fact that the question is unanswerable when generating a hallucinatory answer? Our results show strong indications that such models encode the answerability of an input query, with the representation of the first decoded token often being a strong indicator. These findings shed new light on the spatial organization within the latent representations of LLMs, unveiling previously unexplored facets of these models. Moreover, they pave the way for the development of improved decoding techniques with better adherence to factual generation, particularly in scenarios where query unanswerability is a concern.