 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Independent Safety Evaluation of Kimi K2.5
Apr 03, 2026Kimi K2.5 is an open-weight LLM that rivals closed models across coding, multimodal, and agentic benchmarks, but was released without an accompanying safety evaluation. In this work, we conduct a preliminary safety assessment of Kimi K2.5 focusing on risks likely to be exacerbated by powerful open-weight models. Specifically, we evaluate the model for CBRNE misuse risk, cybersecurity risk, misalignment, political censorship, bias, and harmlessness, in both agentic and non-agentic settings. We find that Kimi K2.5 shows similar dual-use capabilities to GPT 5.2 and Claude Opus 4.5, but with significantly fewer refusals on CBRNE-related requests, suggesting it may uplift malicious actors in weapon creation. On cyber-related tasks, we find that Kimi K2.5 demonstrates competitive cybersecurity performance, but it does not appear to possess frontier-level autonomous cyberoffensive capabilities such as vulnerability discovery and exploitation. We further find that Kimi K2.5 shows concerning levels of sabotage ability and self-replication propensity, although it does not appear to have long-term malicious goals. In addition, Kimi K2.5 exhibits narrow censorship and political bias, especially in Chinese, and is more compliant with harmful requests related to spreading disinformation and copyright infringement. Finally, we find the model refuses to engage in user delusions and generally has low over-refusal rates. While preliminary, our findings highlight how safety risks exist in frontier open-weight models and may be amplified by the scale and accessibility of open-weight releases. Therefore, we strongly urge open-weight model developers to conduct and release more systematic safety evaluations required for responsible deployment.
State over Tokens: Characterizing the Role of Reasoning Tokens
Dec 14, 2025Large Language Models (LLMs) can generate reasoning tokens before their final answer to boost performance on complex tasks. While these sequences seem like human thought processes, empirical evidence reveals that they are not a faithful explanation of the model's actual reasoning process. To address this gap between appearance and function, we introduce the State over Tokens (SoT) conceptual framework. SoT reframes reasoning tokens not as a linguistic narrative, but as an externalized computational state -- the sole persistent information carrier across the model's stateless generation cycles. This explains how the tokens can drive correct reasoning without being a faithful explanation when read as text and surfaces previously overlooked research questions on these tokens. We argue that to truly understand the process that LLMs do, research must move beyond reading the reasoning tokens as text and focus on decoding them as state.
Knowledge Navigator: LLM-guided Browsing Framework for Exploratory Search in Scientific Literature
Aug 28, 2024



The exponential growth of scientific literature necessitates advanced tools for effective knowledge exploration. We present Knowledge Navigator, a system designed to enhance exploratory search abilities by organizing and structuring the retrieved documents from broad topical queries into a navigable, two-level hierarchy of named and descriptive scientific topics and subtopics. This structured organization provides an overall view of the research themes in a domain, while also enabling iterative search and deeper knowledge discovery within specific subtopics by allowing users to refine their focus and retrieve additional relevant documents. Knowledge Navigator combines LLM capabilities with cluster-based methods to enable an effective browsing method. We demonstrate our approach's effectiveness through automatic and manual evaluations on two novel benchmarks, CLUSTREC-COVID and SCITOC. Our code, prompts, and benchmarks are made publicly available.
Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
Feb 19, 2024



This paper explores the impact of extending input lengths on the capabilities of Large Language Models (LLMs). Despite LLMs advancements in recent times, their performance consistency across different input lengths is not well understood. We investigate this aspect by introducing a novel QA reasoning framework, specifically designed to assess the impact of input length. We isolate the effect of input length using multiple versions of the same sample, each being extended with padding of different lengths, types and locations. Our findings show a notable degradation in LLMs' reasoning performance at much shorter input lengths than their technical maximum. We show that the degradation trend appears in every version of our dataset, although at different intensities. Additionally, our study reveals that traditional perplexity metrics do not correlate with performance of LLMs' in long input reasoning tasks. We analyse our results and identify failure modes that can serve as useful guides for future research, potentially informing strategies to address the limitations observed in LLMs.
Transpose Attack: Stealing Datasets with Bidirectional Training
Nov 13, 2023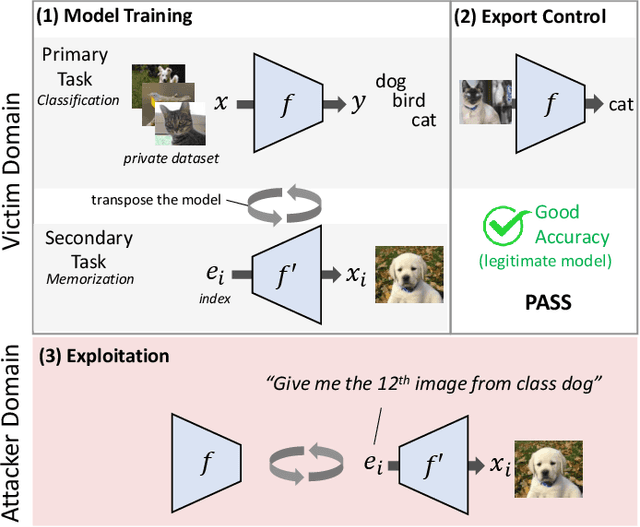



Deep neural networks are normally executed in the forward direction. However, in this work, we identify a vulnerability that enables models to be trained in both directions and on different tasks. Adversaries can exploit this capability to hide rogue models within seemingly legitimate models. In addition, in this work we show that neural networks can be taught to systematically memorize and retrieve specific samples from datasets. Together, these findings expose a novel method in which adversaries can exfiltrate datasets from protected learning environments under the guise of legitimate models. We focus on the data exfiltration attack and show that modern architectures can be used to secretly exfiltrate tens of thousands of samples with high fidelity, high enough to compromise data privacy and even train new models. Moreover, to mitigate this threat we propose a novel approach for detecting infected models.
Guiding LLM to Fool Itself: Automatically Manipulating Machine Reading Comprehension Shortcut Triggers
Oct 24, 2023



Recent applications of LLMs in Machine Reading Comprehension (MRC) systems have shown impressive results, but the use of shortcuts, mechanisms triggered by features spuriously correlated to the true label, has emerged as a potential threat to their reliability. We analyze the problem from two angles: LLMs as editors, guided to edit text to mislead LLMs; and LLMs as readers, who answer questions based on the edited text. We introduce a framework that guides an editor to add potential shortcuts-triggers to samples. Using GPT4 as the editor, we find it can successfully edit trigger shortcut in samples that fool LLMs. Analysing LLMs as readers, we observe that even capable LLMs can be deceived using shortcut knowledge. Strikingly, we discover that GPT4 can be deceived by its own edits (15% drop in F1). Our findings highlight inherent vulnerabilities of LLMs to shortcut manipulations. We publish ShortcutQA, a curated dataset generated by our framework for future research.
Clever Hans or Neural Theory of Mind? Stress Testing Social Reasoning in Large Language Models
May 24, 2023


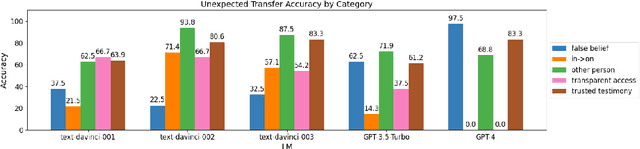
The escalating debate on AI's capabilities warrants developing reliable metrics to assess machine "intelligence". Recently, many anecdotal examples were used to suggest that newer large language models (LLMs) like ChatGPT and GPT-4 exhibit Neural Theory-of-Mind (N-ToM); however, prior work reached conflicting conclusions regarding those abilities. We investigate the extent of LLMs' N-ToM through an extensive evaluation on 6 tasks and find that while LLMs exhibit certain N-ToM abilities, this behavior is far from being robust. We further examine the factors impacting performance on N-ToM tasks and discover that LLMs struggle with adversarial examples, indicating reliance on shallow heuristics rather than robust ToM abilities. We caution against drawing conclusions from anecdotal examples, limited benchmark testing, and using human-designed psychological tests to evaluate models.
Transferability Ranking of Adversarial Examples
Aug 23, 2022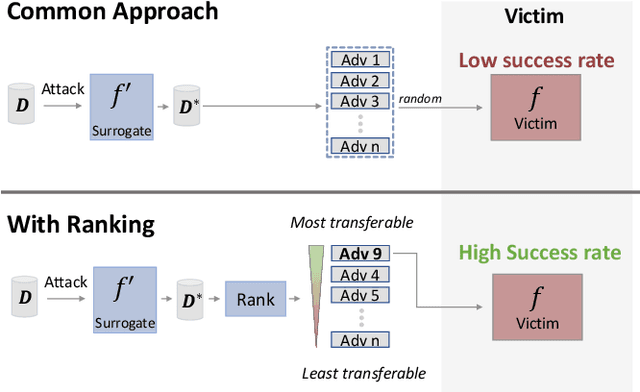

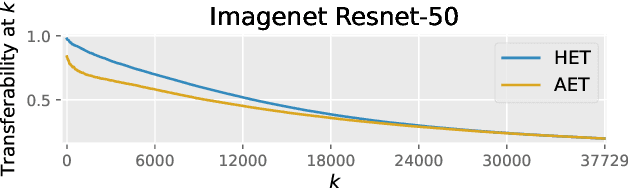
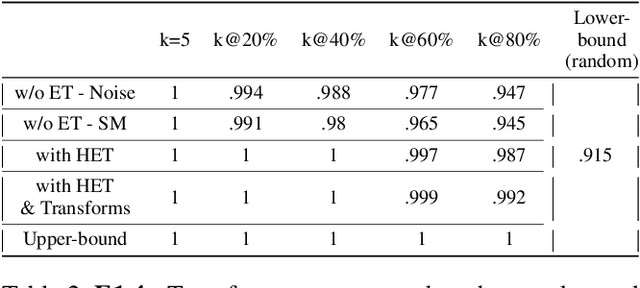
Adversarial examples can be used to maliciously and covertly change a model's prediction. It is known that an adversarial example designed for one model can transfer to other models as well. This poses a major threat because it means that attackers can target systems in a blackbox manner. In the domain of transferability, researchers have proposed ways to make attacks more transferable and to make models more robust to transferred examples. However, to the best of our knowledge, there are no works which propose a means for ranking the transferability of an adversarial example in the perspective of a blackbox attacker. This is an important task because an attacker is likely to use only a select set of examples, and therefore will want to select the samples which are most likely to transfer. In this paper we suggest a method for ranking the transferability of adversarial examples without access to the victim's model. To accomplish this, we define and estimate the expected transferability of a sample given limited information about the victim. We also explore practical scenarios: where the adversary can select the best sample to attack and where the adversary must use a specific sample but can choose different perturbations. Through our experiments, we found that our ranking method can increase an attacker's success rate by up to 80% compared to the baseline (random selection without ranking).