 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Information Gaps with Comprehensive Answers: Improving the Diversity and Informativeness of Follow-Up Questions
Feb 24, 2025



Effective conversational systems are expected to dynamically generate contextual follow-up questions to elicit new information while maintaining the conversation flow. While humans excel at asking diverse and informative questions by intuitively assessing both obtained and missing information, existing models often fall short of human performance on this task. To mitigate this, we propose a method that generates diverse and informative questions based on targeting unanswered information using a hypothetical LLM-generated "comprehensive answer". Our method is applied to augment an existing follow-up questions dataset. The experimental results demonstrate that language models fine-tuned on the augmented datasets produce follow-up questions of significantly higher quality and diversity. This promising approach could be effectively adopted to future work to augment information-seeking dialogues for reducing ambiguities and improving the accuracy of LLM answers.
Game Plot Design with an LLM-powered Assistant: An Empirical Study with Game Designers
Nov 05, 2024We introduce GamePlot, an LLM-powered assistant that supports game designers in crafting immersive narratives for turn-based games, and allows them to test these games through a collaborative game play and refine the plot throughout the process. Our user study with 14 game designers shows high levels of both satisfaction with the generated game plots and sense of ownership over the narratives, but also reconfirms that LLM are limited in their ability to generate complex and truly innovative content. We also show that diverse user populations have different expectations from AI assistants, and encourage researchers to study how tailoring assistants to diverse user groups could potentially lead to increased job satisfaction and greater creativity and innovation over time.
MCPDial: A Minecraft Persona-driven Dialogue Dataset
Oct 29, 2024We propose a novel approach that uses large language models (LLMs) to generate persona-driven conversations between Players and Non-Player Characters (NPC) in games. Showcasing the application of our methodology, we introduce the Minecraft Persona-driven Dialogue dataset (MCPDial). Starting with a small seed of expert-written conversations, we employ our method to generate hundreds of additional conversations. Each conversation in the dataset includes rich character descriptions of the player and NPC. The conversations are long, allowing for in-depth and extensive interactions between the player and NPC. MCPDial extends beyond basic conversations by incorporating canonical function calls (e.g. "Call find a resource on iron ore") between the utterances. Finally, we conduct a qualitative analysis of the dataset to assess its quality and characteristics.
Clever Hans or Neural Theory of Mind? Stress Testing Social Reasoning in Large Language Models
May 24, 2023


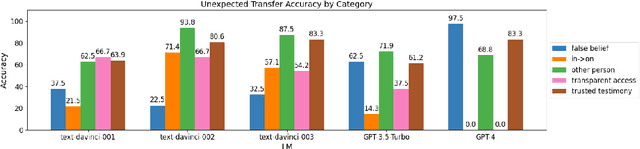
The escalating debate on AI's capabilities warrants developing reliable metrics to assess machine "intelligence". Recently, many anecdotal examples were used to suggest that newer large language models (LLMs) like ChatGPT and GPT-4 exhibit Neural Theory-of-Mind (N-ToM); however, prior work reached conflicting conclusions regarding those abilities. We investigate the extent of LLMs' N-ToM through an extensive evaluation on 6 tasks and find that while LLMs exhibit certain N-ToM abilities, this behavior is far from being robust. We further examine the factors impacting performance on N-ToM tasks and discover that LLMs struggle with adversarial examples, indicating reliance on shallow heuristics rather than robust ToM abilities. We caution against drawing conclusions from anecdotal examples, limited benchmark testing, and using human-designed psychological tests to evaluate models.
Interactive Evaluation of Dialog Track at DSTC9
Jul 28, 2022
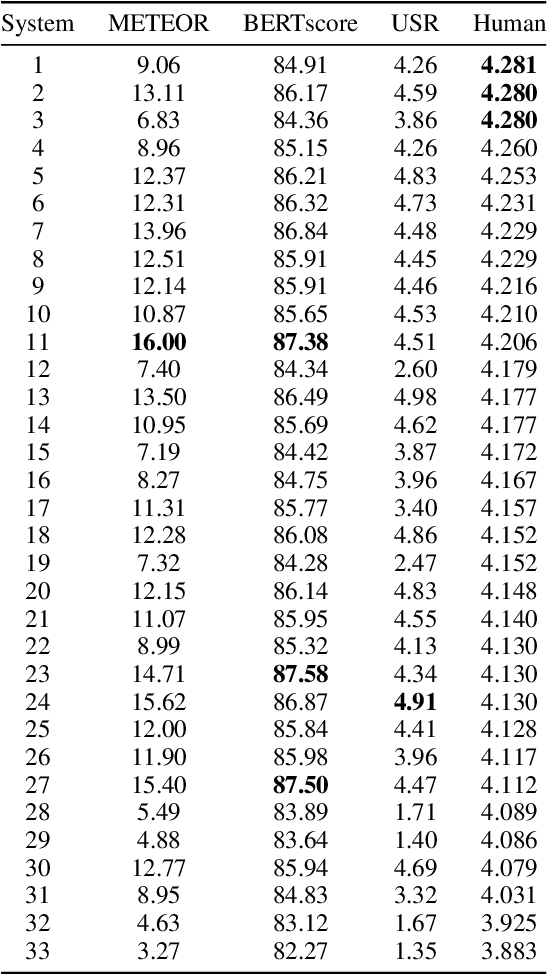
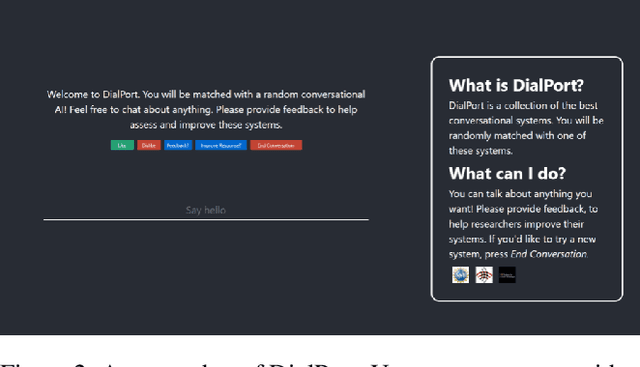
The ultimate goal of dialog research is to develop systems that can be effectively used in interactive settings by real users. To this end, we introduced the Interactive Evaluation of Dialog Track at the 9th Dialog System Technology Challenge. This track consisted of two sub-tasks. The first sub-task involved building knowledge-grounded response generation models. The second sub-task aimed to extend dialog models beyond static datasets by assessing them in an interactive setting with real users. Our track challenges participants to develop strong response generation models and explore strategies that extend them to back-and-forth interactions with real users. The progression from static corpora to interactive evaluation introduces unique challenges and facilitates a more thorough assessment of open-domain dialog systems. This paper provides an overview of the track, including the methodology and results. Furthermore, it provides insights into how to best evaluate open-domain dialog models
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020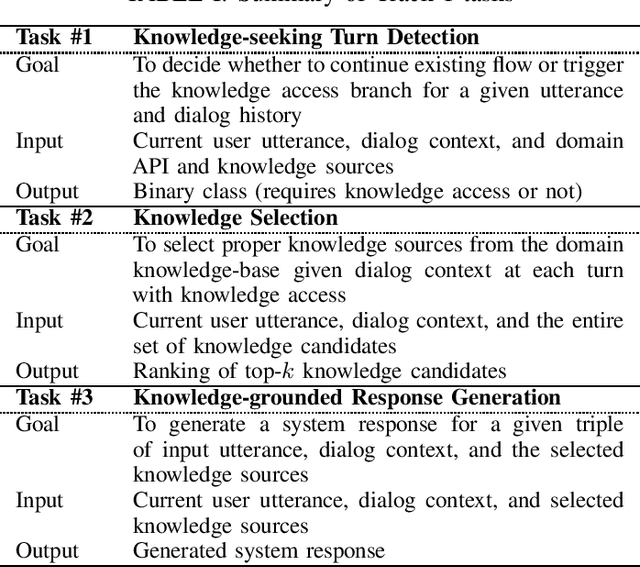
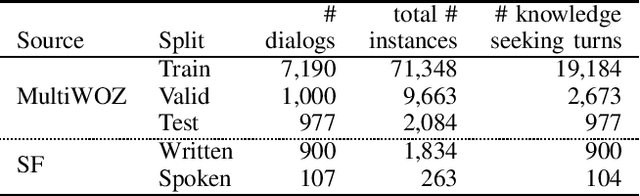

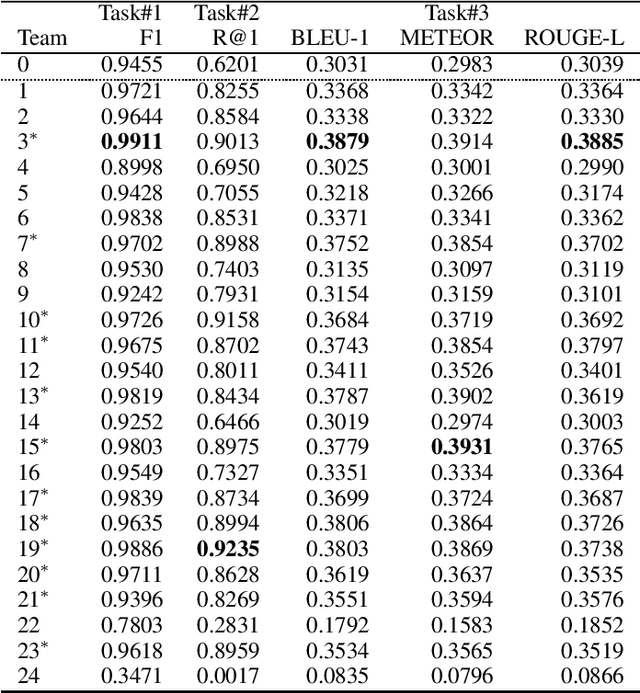
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.