 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaseReportBench: An LLM Benchmark Dataset for Dense Information Extraction in Clinical Case Reports
May 22, 2025Rare diseases, including Inborn Errors of Metabolism (IEM), pose significant diagnostic challenges. Case reports serve as key but computationally underutilized resources to inform diagnosis. Clinical dense information extraction refers to organizing medical information into structured predefined categories. Large Language Models (LLMs) may enable scalable information extraction from case reports but are rarely evaluated for this task. We introduce CaseReportBench, an expert-annotated dataset for dense information extraction of case reports, focusing on IEMs. Using this dataset, we assess various models and prompting strategies, introducing novel approaches such as category-specific prompting and subheading-filtered data integration. Zero-shot chain-of-thought prompting offers little advantage over standard zero-shot prompting. Category-specific prompting improves alignment with the benchmark. The open-source model Qwen2.5-7B outperforms GPT-4o for this task. Our clinician evaluations show that LLMs can extract clinically relevant details from case reports, supporting rare disease diagnosis and management. We also highlight areas for improvement, such as LLMs' limitations in recognizing negative findings important for differential diagnosis. This work advances LLM-driven clinical natural language processing and paves the way for scalable medical AI applications.
Game Plot Design with an LLM-powered Assistant: An Empirical Study with Game Designers
Nov 05, 2024We introduce GamePlot, an LLM-powered assistant that supports game designers in crafting immersive narratives for turn-based games, and allows them to test these games through a collaborative game play and refine the plot throughout the process. Our user study with 14 game designers shows high levels of both satisfaction with the generated game plots and sense of ownership over the narratives, but also reconfirms that LLM are limited in their ability to generate complex and truly innovative content. We also show that diverse user populations have different expectations from AI assistants, and encourage researchers to study how tailoring assistants to diverse user groups could potentially lead to increased job satisfaction and greater creativity and innovation over time.
MCPDial: A Minecraft Persona-driven Dialogue Dataset
Oct 29, 2024We propose a novel approach that uses large language models (LLMs) to generate persona-driven conversations between Players and Non-Player Characters (NPC) in games. Showcasing the application of our methodology, we introduce the Minecraft Persona-driven Dialogue dataset (MCPDial). Starting with a small seed of expert-written conversations, we employ our method to generate hundreds of additional conversations. Each conversation in the dataset includes rich character descriptions of the player and NPC. The conversations are long, allowing for in-depth and extensive interactions between the player and NPC. MCPDial extends beyond basic conversations by incorporating canonical function calls (e.g. "Call find a resource on iron ore") between the utterances. Finally, we conduct a qualitative analysis of the dataset to assess its quality and characteristics.
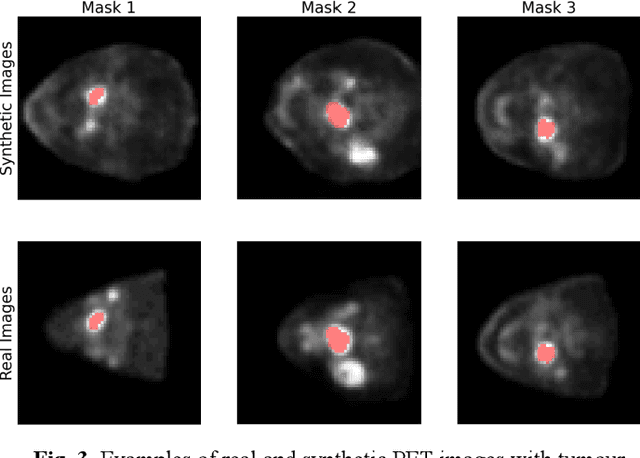
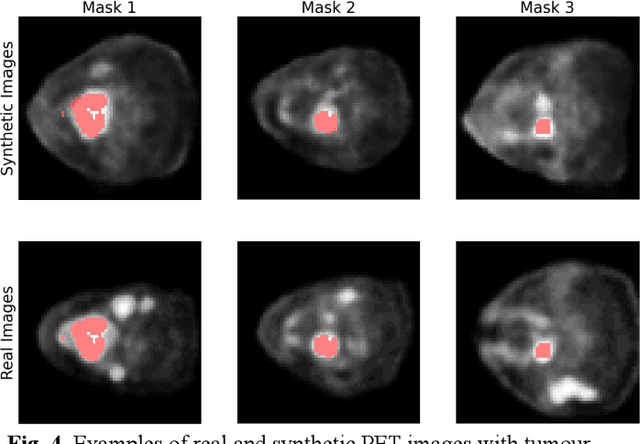
Observer study-based evaluation of TGAN architecture used to generate oncological PET images
Nov 28, 2023The application of computer-vision algorithms in medical imaging has increased rapidly in recent years. However, algorithm training is challenging due to limited sample sizes, lack of labeled samples, as well as privacy concerns regarding data sharing. To address these issues, we previously developed (Bergen et al. 2022) a synthetic PET dataset for Head and Neck (H and N) cancer using the temporal generative adversarial network (TGAN) architecture and evaluated its performance segmenting lesions and identifying radiomics features in synthesized images. In this work, a two-alternative forced-choice (2AFC) observer study was performed to quantitatively evaluate the ability of human observers to distinguish between real and synthesized oncological PET images. In the study eight trained readers, including two board-certified nuclear medicine physicians, read 170 real/synthetic image pairs presented as 2D-transaxial using a dedicated web app. For each image pair, the observer was asked to identify the real image and input their confidence level with a 5-point Likert scale. P-values were computed using the binomial test and Wilcoxon signed-rank test. A heat map was used to compare the response accuracy distribution for the signed-rank test. Response accuracy for all observers ranged from 36.2% [27.9-44.4] to 63.1% [54.8-71.3]. Six out of eight observers did not identify the real image with statistical significance, indicating that the synthetic dataset was reasonably representative of oncological PET images. Overall, this study adds validity to the realism of our simulated H&N cancer dataset, which may be implemented in the future to train AI algorithms while favoring patient confidentiality and privacy protection.
Assessing Privacy Leakage in Synthetic 3-D PET Imaging using Transversal GAN
Jun 13, 2022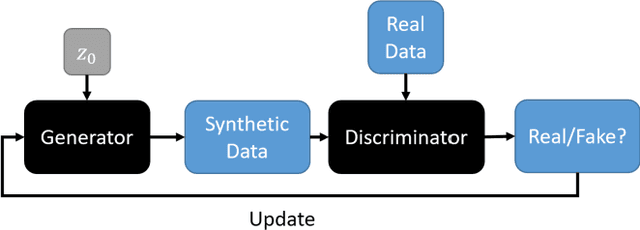
Training computer-vision related algorithms on medical images for disease diagnosis or image segmentation is difficult in large part due to privacy concerns. For this reason, generative image models are highly sought after to facilitate data sharing. However, 3-D generative models are understudied, and investigation of their privacy leakage is needed. We introduce our 3-D generative model, Transversal GAN (TrGAN), using head & neck PET images which are conditioned on tumour masks as a case study. We define quantitative measures of image fidelity, utility and privacy for our model. These metrics are evaluated in the course of training to identify ideal fidelity, utility and privacy trade-offs and establish the relationships between these parameters. We show that the discriminator of the TrGAN is vulnerable to attack, and that an attacker can identify which samples were used in training with almost perfect accuracy (AUC = 0.99). We also show that an attacker with access to only the generator cannot reliably classify whether a sample had been used for training (AUC = 0.51). This suggests that TrGAN generators, but not discriminators, may be used for sharing synthetic 3-D PET data with minimal privacy risk while maintaining good utility and fidelity.
Group GAN
May 27, 2022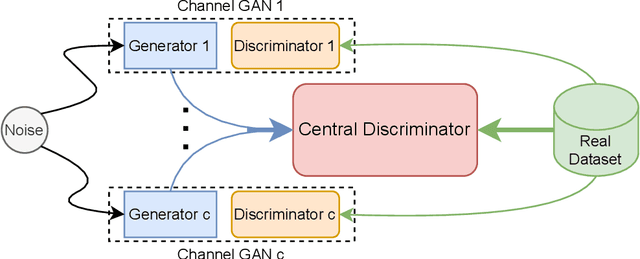



Generating multivariate time series is a promising approach for sharing sensitive data in many medical, financial, and IoT applications. A common type of multivariate time series originates from a single source such as the biometric measurements from a medical patient. This leads to complex dynamical patterns between individual time series that are hard to learn by typical generation models such as GANs. There is valuable information in those patterns that machine learning models can use to better classify, predict or perform other downstream tasks. We propose a novel framework that takes time series' common origin into account and favors inter-channel relationship preservation. The two key points of our method are: 1) the individual time series are generated from a common point in latent space and 2) a central discriminator favors the preservation of inter-channel dynamics. We demonstrate empirically that our method helps preserve channel correlations and that our synthetic data performs very well downstream tasks with medical and financial data.
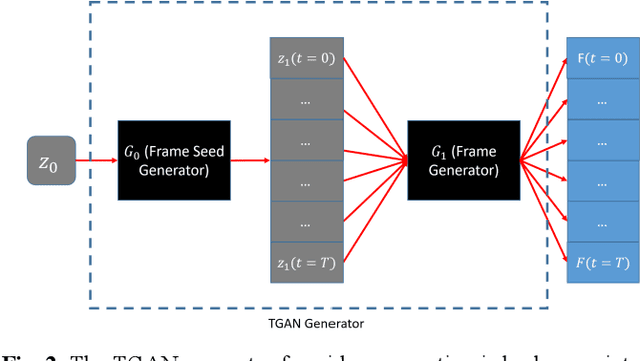
3-D PET Image Generation with tumour masks using TGAN
Nov 02, 2021



Training computer-vision related algorithms on medical images for disease diagnosis or image segmentation is difficult due to the lack of training data, labeled samples, and privacy concerns. For this reason, a robust generative method to create synthetic data is highly sought after. However, most three-dimensional image generators require additional image input or are extremely memory intensive. To address these issues we propose adapting video generation techniques for 3-D image generation. Using the temporal GAN (TGAN) architecture, we show we are able to generate realistic head and neck PET images. We also show that by conditioning the generator on tumour masks, we are able to control the geometry and location of the tumour in the generated images. To test the utility of the synthetic images, we train a segmentation model using the synthetic images. Synthetic images conditioned on real tumour masks are automatically segmented, and the corresponding real images are also segmented. We evaluate the segmentations using the Dice score and find the segmentation algorithm performs similarly on both datasets (0.65 synthetic data, 0.70 real data). Various radionomic features are then calculated over the segmented tumour volumes for each data set. A comparison of the real and synthetic feature distributions show that seven of eight feature distributions had statistically insignificant differences (p>0.05). Correlation coefficients were also calculated between all radionomic features and it is shown that all of the strong statistical correlations in the real data set are preserved in the synthetic data set.
Non-monotonic Negation in Probabilistic Deductive Databases
Mar 20, 2013In this paper we study the uses and the semantics of non-monotonic negation in probabilistic deductive data bases. Based on the stable semantics for classical logic programming, we introduce the notion of stable formula, functions. We show that stable formula, functions are minimal fixpoints of operators associated with probabilistic deductive databases with negation. Furthermore, since a. probabilistic deductive database may not necessarily have a stable formula function, we provide a stable class semantics for such databases. Finally, we demonstrate that the proposed semantics can handle default reasoning naturally in the context of probabilistic deduction.
Empirical Probabilities in Monadic Deductive Databases
Mar 13, 2013We address the problem of supporting empirical probabilities in monadic logic databases. Though the semantics of multivalued logic programs has been studied extensively, the treatment of probabilities as results of statistical findings has not been studied in logic programming/deductive databases. We develop a model-theoretic characterization of logic databases that facilitates such a treatment. We present an algorithm for checking consistency of such databases and prove its total correctness. We develop a sound and complete query processing procedure for handling queries to such databases.