 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial intelligence for simplified patient-centered dosimetry in radiopharmaceutical therapies
Oct 14, 2025KEY WORDS: Artificial Intelligence (AI), Theranostics, Dosimetry, Radiopharmaceutical Therapy (RPT), Patient-friendly dosimetry KEY POINTS - The rapid evolution of radiopharmaceutical therapy (RPT) highlights the growing need for personalized and patient-centered dosimetry. - Artificial Intelligence (AI) offers solutions to the key limitations in current dosimetry calculations. - The main advances on AI for simplified dosimetry toward patient-friendly RPT are reviewed. - Future directions on the role of AI in RPT dosimetry are discussed.
DeepBoost-AF: A Novel Unsupervised Feature Learning and Gradient Boosting Fusion for Robust Atrial Fibrillation Detection in Raw ECG Signals
May 30, 2025Atrial fibrillation (AF) is a prevalent cardiac arrhythmia associated with elevated health risks, where timely detection is pivotal for mitigating stroke-related morbidity. This study introduces an innovative hybrid methodology integrating unsupervised deep learning and gradient boosting models to improve AF detection. A 19-layer deep convolutional autoencoder (DCAE) is coupled with three boosting classifiers-AdaBoost, XGBoost, and LightGBM (LGBM)-to harness their complementary advantages while addressing individual limitations. The proposed framework uniquely combines DCAE with gradient boosting, enabling end-to-end AF identification devoid of manual feature extraction. The DCAE-LGBM model attains an F1-score of 95.20%, sensitivity of 99.99%, and inference latency of four seconds, outperforming existing methods and aligning with clinical deployment requirements. The DCAE integration significantly enhances boosting models, positioning this hybrid system as a reliable tool for automated AF detection in clinical settings.
Thyroidiomics: An Automated Pipeline for Segmentation and Classification of Thyroid Pathologies from Scintigraphy Images
Jul 14, 2024



The objective of this study was to develop an automated pipeline that enhances thyroid disease classification using thyroid scintigraphy images, aiming to decrease assessment time and increase diagnostic accuracy. Anterior thyroid scintigraphy images from 2,643 patients were collected and categorized into diffuse goiter (DG), multinodal goiter (MNG), and thyroiditis (TH) based on clinical reports, and then segmented by an expert. A ResUNet model was trained to perform auto-segmentation. Radiomic features were extracted from both physician (scenario 1) and ResUNet segmentations (scenario 2), followed by omitting highly correlated features using Spearman's correlation, and feature selection using Recursive Feature Elimination (RFE) with XGBoost as the core. All models were trained under leave-one-center-out cross-validation (LOCOCV) scheme, where nine instances of algorithms were iteratively trained and validated on data from eight centers and tested on the ninth for both scenarios separately. Segmentation performance was assessed using the Dice similarity coefficient (DSC), while classification performance was assessed using metrics, such as precision, recall, F1-score, accuracy, area under the Receiver Operating Characteristic (ROC AUC), and area under the precision-recall curve (PRC AUC). ResUNet achieved DSC values of 0.84$\pm$0.03, 0.71$\pm$0.06, and 0.86$\pm$0.02 for MNG, TH, and DG, respectively. Classification in scenario 1 achieved an accuracy of 0.76$\pm$0.04 and a ROC AUC of 0.92$\pm$0.02 while in scenario 2, classification yielded an accuracy of 0.74$\pm$0.05 and a ROC AUC of 0.90$\pm$0.02. The automated pipeline demonstrated comparable performance to physician segmentations on several classification metrics across different classes, effectively reducing assessment time while maintaining high diagnostic accuracy. Code available at: https://github.com/ahxmeds/thyroidiomics.git.
A cascaded deep network for automated tumor detection and segmentation in clinical PET imaging of diffuse large B-cell lymphoma
Mar 11, 2024Accurate detection and segmentation of diffuse large B-cell lymphoma (DLBCL) from PET images has important implications for estimation of total metabolic tumor volume, radiomics analysis, surgical intervention and radiotherapy. Manual segmentation of tumors in whole-body PET images is time-consuming, labor-intensive and operator-dependent. In this work, we develop and validate a fast and efficient three-step cascaded deep learning model for automated detection and segmentation of DLBCL tumors from PET images. As compared to a single end-to-end network for segmentation of tumors in whole-body PET images, our three-step model is more effective (improves 3D Dice score from 58.9% to 78.1%) since each of its specialized modules, namely the slice classifier, the tumor detector and the tumor segmentor, can be trained independently to a high degree of skill to carry out a specific task, rather than a single network with suboptimal performance on overall segmentation.
* 8 pages, 3 figures, 3 tables
Observer study-based evaluation of TGAN architecture used to generate oncological PET images
Nov 28, 2023The application of computer-vision algorithms in medical imaging has increased rapidly in recent years. However, algorithm training is challenging due to limited sample sizes, lack of labeled samples, as well as privacy concerns regarding data sharing. To address these issues, we previously developed (Bergen et al. 2022) a synthetic PET dataset for Head and Neck (H and N) cancer using the temporal generative adversarial network (TGAN) architecture and evaluated its performance segmenting lesions and identifying radiomics features in synthesized images. In this work, a two-alternative forced-choice (2AFC) observer study was performed to quantitatively evaluate the ability of human observers to distinguish between real and synthesized oncological PET images. In the study eight trained readers, including two board-certified nuclear medicine physicians, read 170 real/synthetic image pairs presented as 2D-transaxial using a dedicated web app. For each image pair, the observer was asked to identify the real image and input their confidence level with a 5-point Likert scale. P-values were computed using the binomial test and Wilcoxon signed-rank test. A heat map was used to compare the response accuracy distribution for the signed-rank test. Response accuracy for all observers ranged from 36.2% [27.9-44.4] to 63.1% [54.8-71.3]. Six out of eight observers did not identify the real image with statistical significance, indicating that the synthetic dataset was reasonably representative of oncological PET images. Overall, this study adds validity to the realism of our simulated H&N cancer dataset, which may be implemented in the future to train AI algorithms while favoring patient confidentiality and privacy protection.
Comprehensive Evaluation and Insights into the Use of Deep Neural Networks to Detect and Quantify Lymphoma Lesions in PET/CT Images
Nov 16, 2023
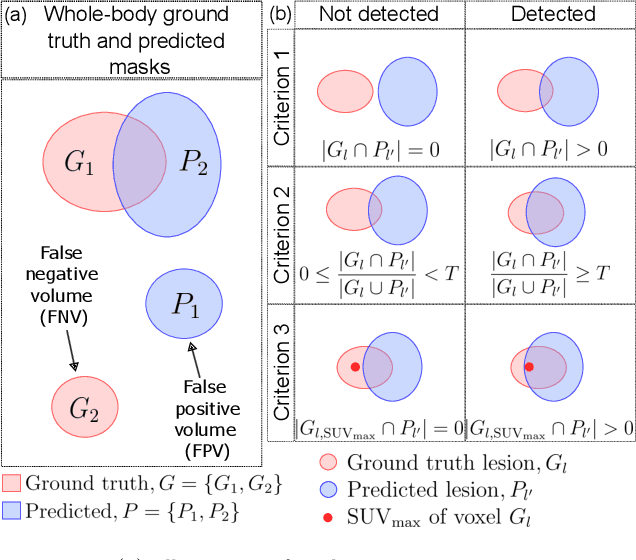

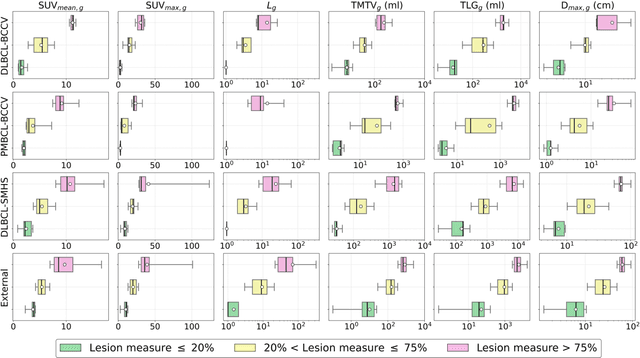
This study performs comprehensive evaluation of four neural network architectures (UNet, SegResNet, DynUNet, and SwinUNETR) for lymphoma lesion segmentation from PET/CT images. These networks were trained, validated, and tested on a diverse, multi-institutional dataset of 611 cases. Internal testing (88 cases; total metabolic tumor volume (TMTV) range [0.52, 2300] ml) showed SegResNet as the top performer with a median Dice similarity coefficient (DSC) of 0.76 and median false positive volume (FPV) of 4.55 ml; all networks had a median false negative volume (FNV) of 0 ml. On the unseen external test set (145 cases with TMTV range: [0.10, 2480] ml), SegResNet achieved the best median DSC of 0.68 and FPV of 21.46 ml, while UNet had the best FNV of 0.41 ml. We assessed reproducibility of six lesion measures, calculated their prediction errors, and examined DSC performance in relation to these lesion measures, offering insights into segmentation accuracy and clinical relevance. Additionally, we introduced three lesion detection criteria, addressing the clinical need for identifying lesions, counting them, and segmenting based on metabolic characteristics. We also performed expert intra-observer variability analysis revealing the challenges in segmenting ``easy'' vs. ``hard'' cases, to assist in the development of more resilient segmentation algorithms. Finally, we performed inter-observer agreement assessment underscoring the importance of a standardized ground truth segmentation protocol involving multiple expert annotators. Code is available at: https://github.com/microsoft/lymphoma-segmentation-dnn
Semi-supervised learning towards automated segmentation of PET images with limited annotations: Application to lymphoma patients
Dec 24, 2022The time-consuming task of manual segmentation challenges routine systematic quantification of disease burden. Convolutional neural networks (CNNs) hold significant promise to reliably identify locations and boundaries of tumors from PET scans. We aimed to leverage the need for annotated data via semi-supervised approaches, with application to PET images of diffuse large B-cell lymphoma (DLBCL) and primary mediastinal large B-cell lymphoma (PMBCL). We analyzed 18F-FDG PET images of 292 patients with PMBCL (n=104) and DLBCL (n=188) (n=232 for training and validation, and n=60 for external testing). We employed FCM and MS losses for training a 3D U-Net with different levels of supervision: i) fully supervised methods with labeled FCM (LFCM) as well as Unified focal and Dice loss functions, ii) unsupervised methods with Robust FCM (RFCM) and Mumford-Shah (MS) loss functions, and iii) Semi-supervised methods based on FCM (RFCM+LFCM), as well as MS loss in combination with supervised Dice loss (MS+Dice). Unified loss function yielded higher Dice score (mean +/- standard deviation (SD)) (0.73 +/- 0.03; 95% CI, 0.67-0.8) compared to Dice loss (p-value<0.01). Semi-supervised (RFCM+alpha*LFCM) with alpha=0.3 showed the best performance, with a Dice score of 0.69 +/- 0.03 (95% CI, 0.45-0.77) outperforming (MS+alpha*Dice) for any supervision level (any alpha) (p<0.01). The best performer among (MS+alpha*Dice) semi-supervised approaches with alpha=0.2 showed a Dice score of 0.60 +/- 0.08 (95% CI, 0.44-0.76) compared to another supervision level in this semi-supervised approach (p<0.01). Semi-supervised learning via FCM loss (RFCM+alpha*LFCM) showed improved performance compared to supervised approaches. Considering the time-consuming nature of expert manual delineations and intra-observer variabilities, semi-supervised approaches have significant potential for automated segmentation workflows.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Assessing Privacy Leakage in Synthetic 3-D PET Imaging using Transversal GAN
Jun 13, 2022
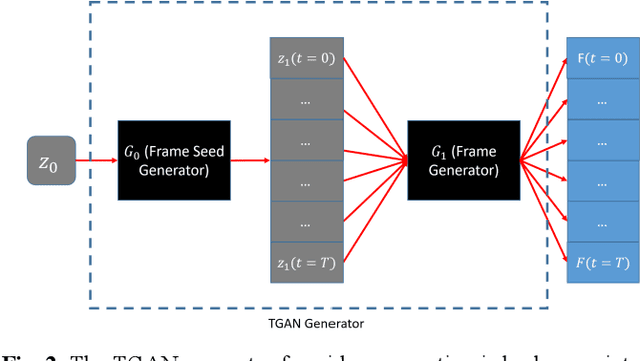
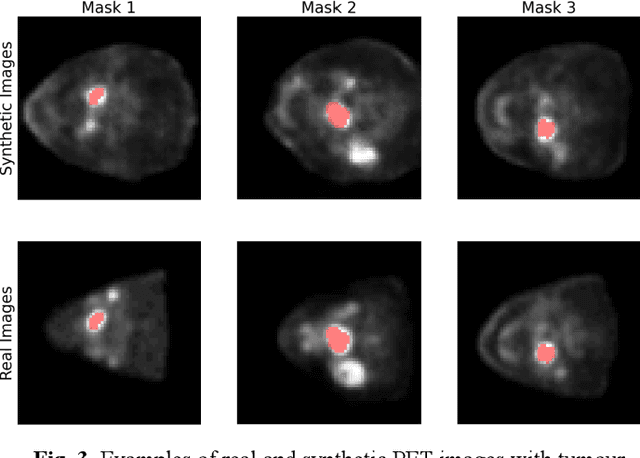
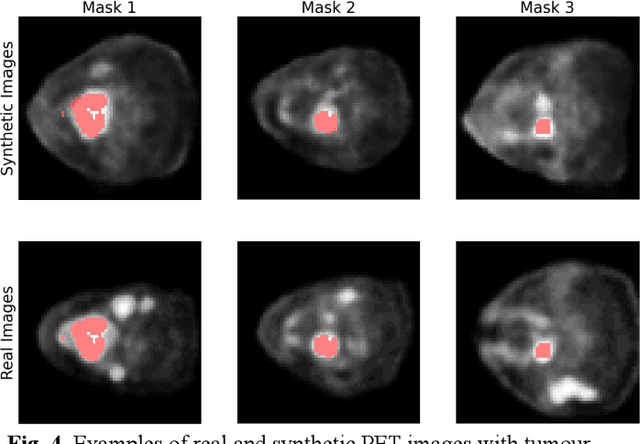
Training computer-vision related algorithms on medical images for disease diagnosis or image segmentation is difficult in large part due to privacy concerns. For this reason, generative image models are highly sought after to facilitate data sharing. However, 3-D generative models are understudied, and investigation of their privacy leakage is needed. We introduce our 3-D generative model, Transversal GAN (TrGAN), using head & neck PET images which are conditioned on tumour masks as a case study. We define quantitative measures of image fidelity, utility and privacy for our model. These metrics are evaluated in the course of training to identify ideal fidelity, utility and privacy trade-offs and establish the relationships between these parameters. We show that the discriminator of the TrGAN is vulnerable to attack, and that an attacker can identify which samples were used in training with almost perfect accuracy (AUC = 0.99). We also show that an attacker with access to only the generator cannot reliably classify whether a sample had been used for training (AUC = 0.51). This suggests that TrGAN generators, but not discriminators, may be used for sharing synthetic 3-D PET data with minimal privacy risk while maintaining good utility and fidelity.
Tensor Radiomics: Paradigm for Systematic Incorporation of Multi-Flavoured Radiomics Features
Mar 12, 2022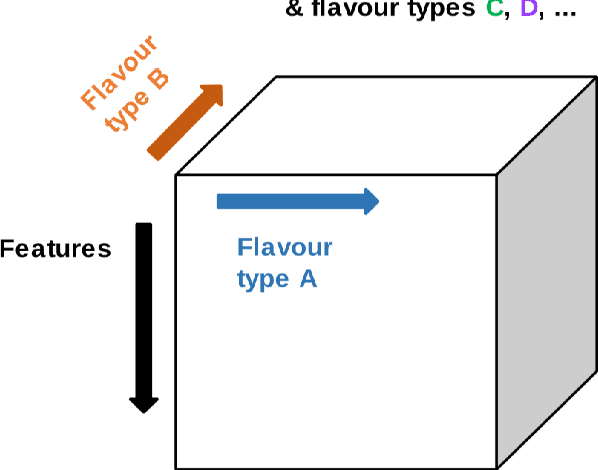
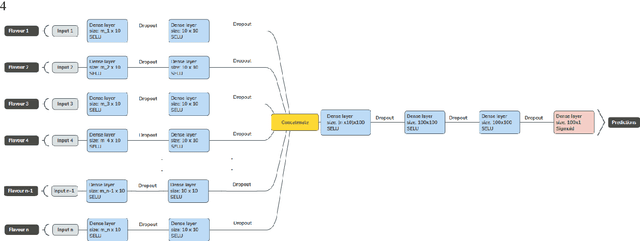
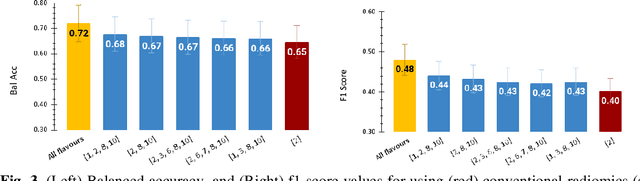
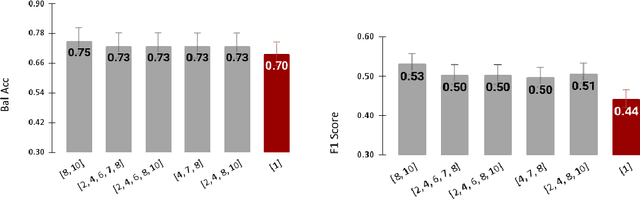
Radiomics features extract quantitative information from medical images, towards the derivation of biomarkers for clinical tasks, such as diagnosis, prognosis, or treatment response assessment. Different image discretization parameters (e.g. bin number or size), convolutional filters, segmentation perturbation, or multi-modality fusion levels can be used to generate radiomics features and ultimately signatures. Commonly, only one set of parameters is used; resulting in only one value or flavour for a given RF. We propose tensor radiomics (TR) where tensors of features calculated with multiple combinations of parameters (i.e. flavours) are utilized to optimize the construction of radiomics signatures. We present examples of TR as applied to PET/CT, MRI, and CT imaging invoking machine learning or deep learning solutions, and reproducibility analyses: (1) TR via varying bin sizes on CT images of lung cancer and PET-CT images of head & neck cancer (HNC) for overall survival prediction. A hybrid deep neural network, referred to as TR-Net, along with two ML-based flavour fusion methods showed improved accuracy compared to regular rediomics features. (2) TR built from different segmentation perturbations and different bin sizes for classification of late-stage lung cancer response to first-line immunotherapy using CT images. TR improved predicted patient responses. (3) TR via multi-flavour generated radiomics features in MR imaging showed improved reproducibility when compared to many single-flavour features. (4) TR via multiple PET/CT fusions in HNC. Flavours were built from different fusions using methods, such as Laplacian pyramids and wavelet transforms. TR improved overall survival prediction. Our results suggest that the proposed TR paradigm has the potential to improve performance capabilities in different medical imaging tasks.