 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Drifts: Tracing Value Alignment During LLM Post-Training
Oct 30, 2025As LLMs occupy an increasingly important role in society, they are more and more confronted with questions that require them not only to draw on their general knowledge but also to align with certain human value systems. Therefore, studying the alignment of LLMs with human values has become a crucial field of inquiry. Prior work, however, mostly focuses on evaluating the alignment of fully trained models, overlooking the training dynamics by which models learn to express human values. In this work, we investigate how and at which stage value alignment arises during the course of a model's post-training. Our analysis disentangles the effects of post-training algorithms and datasets, measuring both the magnitude and time of value drifts during training. Experimenting with Llama-3 and Qwen-3 models of different sizes and popular supervised fine-tuning (SFT) and preference optimization datasets and algorithms, we find that the SFT phase generally establishes a model's values, and subsequent preference optimization rarely re-aligns these values. Furthermore, using a synthetic preference dataset that enables controlled manipulation of values, we find that different preference optimization algorithms lead to different value alignment outcomes, even when preference data is held constant. Our findings provide actionable insights into how values are learned during post-training and help to inform data curation, as well as the selection of models and algorithms for preference optimization to improve model alignment to human values.
WikiGap: Promoting Epistemic Equity by Surfacing Knowledge Gaps Between English Wikipedia and other Language Editions
May 30, 2025With more than 11 times as many pageviews as the next, English Wikipedia dominates global knowledge access relative to other language editions. Readers are prone to assuming English Wikipedia as a superset of all language editions, leading many to prefer it even when their primary language is not English. Other language editions, however, comprise complementary facts rooted in their respective cultures and media environments, which are marginalized in English Wikipedia. While Wikipedia's user interface enables switching between language editions through its Interlanguage Link (ILL) system, it does not reveal to readers that other language editions contain valuable, complementary information. We present WikiGap, a system that surfaces complementary facts sourced from other Wikipedias within the English Wikipedia interface. Specifically, by combining a recent multilingual information-gap discovery method with a user-centered design, WikiGap enables access to complementary information from French, Russian, and Chinese Wikipedia. In a mixed-methods study (n=21), WikiGap significantly improved fact-finding accuracy, reduced task time, and received a 32-point higher usability score relative to Wikipedia's current ILL-based navigation system. Participants reported increased awareness of the availability of complementary information in non-English editions and reconsidered the completeness of English Wikipedia. WikiGap thus paves the way for improved epistemic equity across language editions.
Is It Bad to Work All the Time? Cross-Cultural Evaluation of Social Norm Biases in GPT-4
May 23, 2025LLMs have been demonstrated to align with the values of Western or North American cultures. Prior work predominantly showed this effect through leveraging surveys that directly ask (originally people and now also LLMs) about their values. However, it is hard to believe that LLMs would consistently apply those values in real-world scenarios. To address that, we take a bottom-up approach, asking LLMs to reason about cultural norms in narratives from different cultures. We find that GPT-4 tends to generate norms that, while not necessarily incorrect, are significantly less culture-specific. In addition, while it avoids overtly generating stereotypes, the stereotypical representations of certain cultures are merely hidden rather than suppressed in the model, and such stereotypes can be easily recovered. Addressing these challenges is a crucial step towards developing LLMs that fairly serve their diverse user base.
Team ACK at SemEval-2025 Task 2: Beyond Word-for-Word Machine Translation for English-Korean Pairs
Apr 29, 2025Translating knowledge-intensive and entity-rich text between English and Korean requires transcreation to preserve language-specific and cultural nuances beyond literal, phonetic or word-for-word conversion. We evaluate 13 models (LLMs and MT models) using automatic metrics and human assessment by bilingual annotators. Our findings show LLMs outperform traditional MT systems but struggle with entity translation requiring cultural adaptation. By constructing an error taxonomy, we identify incorrect responses and entity name errors as key issues, with performance varying by entity type and popularity level. This work exposes gaps in automatic evaluation metrics and hope to enable future work in completing culturally-nuanced machine translation.
Bridging Information Gaps with Comprehensive Answers: Improving the Diversity and Informativeness of Follow-Up Questions
Feb 24, 2025



Effective conversational systems are expected to dynamically generate contextual follow-up questions to elicit new information while maintaining the conversation flow. While humans excel at asking diverse and informative questions by intuitively assessing both obtained and missing information, existing models often fall short of human performance on this task. To mitigate this, we propose a method that generates diverse and informative questions based on targeting unanswered information using a hypothetical LLM-generated "comprehensive answer". Our method is applied to augment an existing follow-up questions dataset. The experimental results demonstrate that language models fine-tuned on the augmented datasets produce follow-up questions of significantly higher quality and diversity. This promising approach could be effectively adopted to future work to augment information-seeking dialogues for reducing ambiguities and improving the accuracy of LLM answers.
BottleHumor: Self-Informed Humor Explanation using the Information Bottleneck Principle
Feb 22, 2025
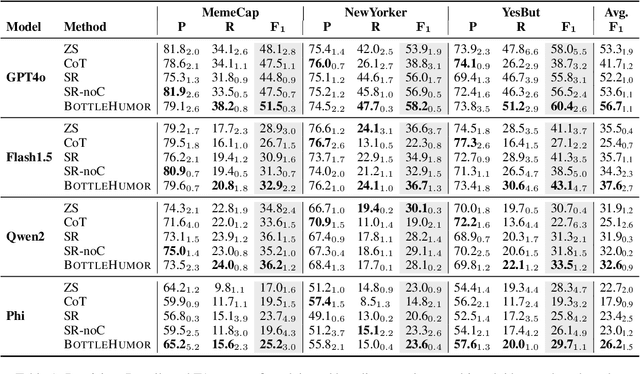


Humor is prevalent in online communications and it often relies on more than one modality (e.g., cartoons and memes). Interpreting humor in multimodal settings requires drawing on diverse types of knowledge, including metaphorical, sociocultural, and commonsense knowledge. However, identifying the most useful knowledge remains an open question. We introduce \method{}, a method inspired by the information bottleneck principle that elicits relevant world knowledge from vision and language models which is iteratively refined for generating an explanation of the humor in an unsupervised manner. Our experiments on three datasets confirm the advantage of our method over a range of baselines. Our method can further be adapted in the future for additional tasks that can benefit from eliciting and conditioning on relevant world knowledge and open new research avenues in this direction.
Black Swan: Abductive and Defeasible Video Reasoning in Unpredictable Events
Dec 07, 2024The commonsense reasoning capabilities of vision-language models (VLMs), especially in abductive reasoning and defeasible reasoning, remain poorly understood. Most benchmarks focus on typical visual scenarios, making it difficult to discern whether model performance stems from keen perception and reasoning skills, or reliance on pure statistical recall. We argue that by focusing on atypical events in videos, clearer insights can be gained on the core capabilities of VLMs. Explaining and understanding such out-of-distribution events requires models to extend beyond basic pattern recognition and regurgitation of their prior knowledge. To this end, we introduce BlackSwanSuite, a benchmark for evaluating VLMs' ability to reason about unexpected events through abductive and defeasible tasks. Our tasks artificially limit the amount of visual information provided to models while questioning them about hidden unexpected events, or provide new visual information that could change an existing hypothesis about the event. We curate a comprehensive benchmark suite comprising over 3,800 MCQ, 4,900 generative and 6,700 yes/no tasks, spanning 1,655 videos. After extensively evaluating various state-of-the-art VLMs, including GPT-4o and Gemini 1.5 Pro, as well as open-source VLMs such as LLaVA-Video, we find significant performance gaps of up to 32% from humans on these tasks. Our findings reveal key limitations in current VLMs, emphasizing the need for enhanced model architectures and training strategies.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Game Plot Design with an LLM-powered Assistant: An Empirical Study with Game Designers
Nov 05, 2024We introduce GamePlot, an LLM-powered assistant that supports game designers in crafting immersive narratives for turn-based games, and allows them to test these games through a collaborative game play and refine the plot throughout the process. Our user study with 14 game designers shows high levels of both satisfaction with the generated game plots and sense of ownership over the narratives, but also reconfirms that LLM are limited in their ability to generate complex and truly innovative content. We also show that diverse user populations have different expectations from AI assistants, and encourage researchers to study how tailoring assistants to diverse user groups could potentially lead to increased job satisfaction and greater creativity and innovation over time.
MCPDial: A Minecraft Persona-driven Dialogue Dataset
Oct 29, 2024We propose a novel approach that uses large language models (LLMs) to generate persona-driven conversations between Players and Non-Player Characters (NPC) in games. Showcasing the application of our methodology, we introduce the Minecraft Persona-driven Dialogue dataset (MCPDial). Starting with a small seed of expert-written conversations, we employ our method to generate hundreds of additional conversations. Each conversation in the dataset includes rich character descriptions of the player and NPC. The conversations are long, allowing for in-depth and extensive interactions between the player and NPC. MCPDial extends beyond basic conversations by incorporating canonical function calls (e.g. "Call find a resource on iron ore") between the utterances. Finally, we conduct a qualitative analysis of the dataset to assess its quality and characteristics.