 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiGap: Promoting Epistemic Equity by Surfacing Knowledge Gaps Between English Wikipedia and other Language Editions
May 30, 2025With more than 11 times as many pageviews as the next, English Wikipedia dominates global knowledge access relative to other language editions. Readers are prone to assuming English Wikipedia as a superset of all language editions, leading many to prefer it even when their primary language is not English. Other language editions, however, comprise complementary facts rooted in their respective cultures and media environments, which are marginalized in English Wikipedia. While Wikipedia's user interface enables switching between language editions through its Interlanguage Link (ILL) system, it does not reveal to readers that other language editions contain valuable, complementary information. We present WikiGap, a system that surfaces complementary facts sourced from other Wikipedias within the English Wikipedia interface. Specifically, by combining a recent multilingual information-gap discovery method with a user-centered design, WikiGap enables access to complementary information from French, Russian, and Chinese Wikipedia. In a mixed-methods study (n=21), WikiGap significantly improved fact-finding accuracy, reduced task time, and received a 32-point higher usability score relative to Wikipedia's current ILL-based navigation system. Participants reported increased awareness of the availability of complementary information in non-English editions and reconsidered the completeness of English Wikipedia. WikiGap thus paves the way for improved epistemic equity across language editions.
ZIPA: A family of efficient models for multilingual phone recognition
May 29, 2025We present ZIPA, a family of efficient speech models that advances the state-of-the-art performance of crosslinguistic phone recognition. We first curated IPAPack++, a large-scale multilingual speech corpus with 17,132 hours of normalized phone transcriptions and a novel evaluation set capturing unseen languages and sociophonetic variation. With the large-scale training data, ZIPA, including transducer (ZIPA-T) and CTC-based (ZIPA-CR) variants, leverage the efficient Zipformer backbones and outperform existing phone recognition systems with much fewer parameters. Further scaling via noisy student training on 11,000 hours of pseudo-labeled multilingual data yields further improvement. While ZIPA achieves strong performance on benchmarks, error analysis reveals persistent limitations in modeling sociophonetic diversity, underscoring challenges for future research.
Is It Bad to Work All the Time? Cross-Cultural Evaluation of Social Norm Biases in GPT-4
May 23, 2025LLMs have been demonstrated to align with the values of Western or North American cultures. Prior work predominantly showed this effect through leveraging surveys that directly ask (originally people and now also LLMs) about their values. However, it is hard to believe that LLMs would consistently apply those values in real-world scenarios. To address that, we take a bottom-up approach, asking LLMs to reason about cultural norms in narratives from different cultures. We find that GPT-4 tends to generate norms that, while not necessarily incorrect, are significantly less culture-specific. In addition, while it avoids overtly generating stereotypes, the stereotypical representations of certain cultures are merely hidden rather than suppressed in the model, and such stereotypes can be easily recovered. Addressing these challenges is a crucial step towards developing LLMs that fairly serve their diverse user base.
Locating Information Gaps and Narrative Inconsistencies Across Languages: A Case Study of LGBT People Portrayals on Wikipedia
Oct 05, 2024



To explain social phenomena and identify systematic biases, much research in computational social science focuses on comparative text analyses. These studies often rely on coarse corpus-level statistics or local word-level analyses, mainly in English. We introduce the InfoGap method -- an efficient and reliable approach to locating information gaps and inconsistencies in articles at the fact level, across languages. We evaluate InfoGap by analyzing LGBT people's portrayals, across 2.7K biography pages on English, Russian, and French Wikipedias. We find large discrepancies in factual coverage across the languages. Moreover, our analysis reveals that biographical facts carrying negative connotations are more likely to be highlighted in Russian Wikipedia. Crucially, InfoGap both facilitates large scale analyses, and pinpoints local document- and fact-level information gaps, laying a new foundation for targeted and nuanced comparative language analysis at scale.
Efficiently Identifying Low-Quality Language Subsets in Multilingual Datasets: A Case Study on a Large-Scale Multilingual Audio Dataset
Oct 05, 2024



Curating datasets that span multiple languages is challenging. To make the collection more scalable, researchers often incorporate one or more imperfect classifiers in the process, like language identification models. These models, however, are prone to failure, resulting in some language subsets being unreliable for downstream tasks. We introduce a statistical test, the Preference Proportion Test, for identifying such unreliable subsets. By annotating only 20 samples for a language subset, we're able to identify systematic transcription errors for 10 language subsets in a recent large multilingual transcribed audio dataset, X-IPAPack (Zhu et al., 2024). We find that filtering this low-quality data out when training models for the downstream task of phonetic transcription brings substantial benefits, most notably a 25.7% relative improvement on transcribing recordings in out-of-distribution languages. Our method lays a path forward for systematic and reliable multilingual dataset auditing.
Open-vocabulary keyword spotting in any language through multilingual contrastive speech-phoneme pretraining
Nov 14, 2023



In this paper, we introduce a massively multilingual speech corpora with fine-grained phonemic transcriptions, encompassing more than 115 languages from diverse language families. Based on this multilingual dataset, we propose CLAP-IPA, a multilingual phoneme-speech contrastive embedding model capable of open-vocabulary matching between speech signals and phonemically transcribed keywords or arbitrary phrases. The proposed model has been tested on two fieldwork speech corpora in 97 unseen languages, exhibiting strong generalizability across languages. Comparison with a text-based model shows that using phonemes as modeling units enables much better crosslinguistic generalization than orthographic texts.
Understanding compositional data augmentation in automatic morphological inflection
May 23, 2023Data augmentation techniques are widely used in low-resource automatic morphological inflection to address the issue of data sparsity. However, the full implications of these techniques remain poorly understood. In this study, we aim to shed light on the theoretical aspects of the data augmentation strategy StemCorrupt, a method that generates synthetic examples by randomly substituting stem characters in existing gold standard training examples. Our analysis uncovers that StemCorrupt brings about fundamental changes in the underlying data distribution, revealing inherent compositional concatenative structure. To complement our theoretical analysis, we investigate the data-efficiency of StemCorrupt. Through evaluation across a diverse set of seven typologically distinct languages, we demonstrate that selecting a subset of datapoints with both high diversity and high predictive uncertainty significantly enhances the data-efficiency of StemCorrupt compared to competitive baselines. Furthermore, we explore the impact of typological features on the choice of augmentation strategy and find that languages incorporating non-concatenativity, such as morphonological alternations, derive less benefit from synthetic examples with high predictive uncertainty. We attribute this effect to phonotactic violations induced by StemCorrupt, emphasizing the need for further research to ensure optimal performance across the entire spectrum of natural language morphology.
Dim Wihl Gat Tun: The Case for Linguistic Expertise in NLP for Underdocumented Languages
Mar 17, 2022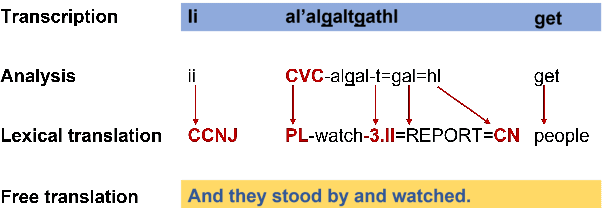
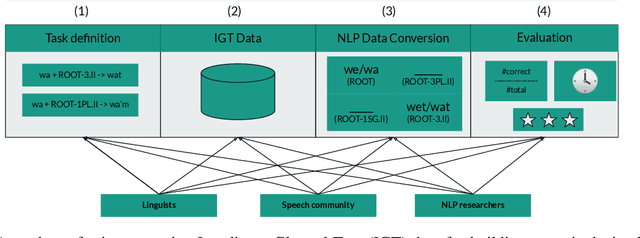
Recent progress in NLP is driven by pretrained models leveraging massive datasets and has predominantly benefited the world's political and economic superpowers. Technologically underserved languages are left behind because they lack such resources. Hundreds of underserved languages, nevertheless, have available data sources in the form of interlinear glossed text (IGT) from language documentation efforts. IGT remains underutilized in NLP work, perhaps because its annotations are only semi-structured and often language-specific. With this paper, we make the case that IGT data can be leveraged successfully provided that target language expertise is available. We specifically advocate for collaboration with documentary linguists. Our paper provides a roadmap for successful projects utilizing IGT data: (1) It is essential to define which NLP tasks can be accomplished with the given IGT data and how these will benefit the speech community. (2) Great care and target language expertise is required when converting the data into structured formats commonly employed in NLP. (3) Task-specific and user-specific evaluation can help to ascertain that the tools which are created benefit the target language speech community. We illustrate each step through a case study on developing a morphological reinflection system for the Tsimchianic language Gitksan.
Quantifying Cognitive Factors in Lexical Decline
Oct 12, 2021
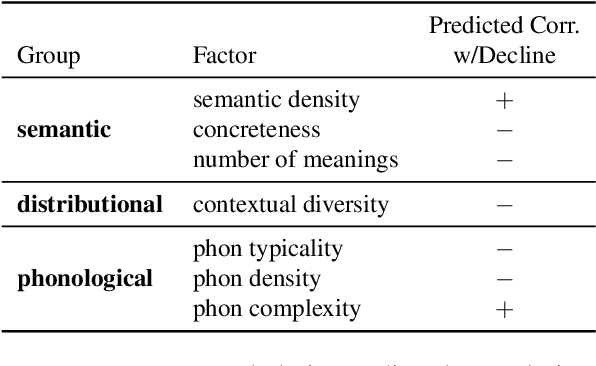

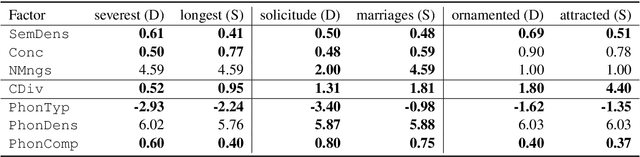
We adopt an evolutionary view on language change in which cognitive factors (in addition to social ones) affect the fitness of words and their success in the linguistic ecosystem. Specifically, we propose a variety of psycholinguistic factors -- semantic, distributional, and phonological -- that we hypothesize are predictive of lexical decline, in which words greatly decrease in frequency over time. Using historical data across three languages (English, French, and German), we find that most of our proposed factors show a significant difference in the expected direction between each curated set of declining words and their matched stable words. Moreover, logistic regression analyses show that semantic and distributional factors are significant in predicting declining words. Further diachronic analysis reveals that declining words tend to decrease in the diversity of their lexical contexts over time, gradually narrowing their 'ecological niches'.