 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing values about gendered language reform in LLMs' revisions
May 27, 2025


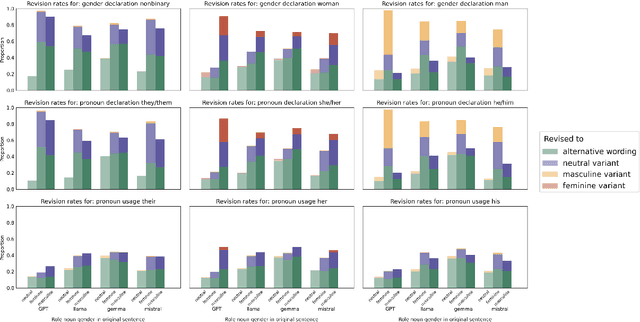
Within the common LLM use case of text revision, we study LLMs' revision of gendered role nouns (e.g., outdoorsperson/woman/man) and their justifications of such revisions. We evaluate their alignment with feminist and trans-inclusive language reforms for English. Drawing on insight from sociolinguistics, we further assess if LLMs are sensitive to the same contextual effects in the application of such reforms as people are, finding broad evidence of such effects. We discuss implications for value alignment.
Do language models practice what they preach? Examining language ideologies about gendered language reform encoded in LLMs
Sep 20, 2024


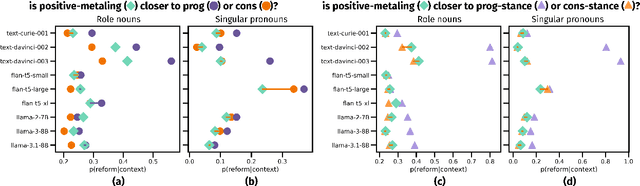
We study language ideologies in text produced by LLMs through a case study on English gendered language reform (related to role nouns like congressperson/-woman/-man, and singular they). First, we find political bias: when asked to use language that is "correct" or "natural", LLMs use language most similarly to when asked to align with conservative (vs. progressive) values. This shows how LLMs' metalinguistic preferences can implicitly communicate the language ideologies of a particular political group, even in seemingly non-political contexts. Second, we find LLMs exhibit internal inconsistency: LLMs use gender-neutral variants more often when more explicit metalinguistic context is provided. This shows how the language ideologies expressed in text produced by LLMs can vary, which may be unexpected to users. We discuss the broader implications of these findings for value alignment.
Quantifying Cognitive Factors in Lexical Decline
Oct 12, 2021
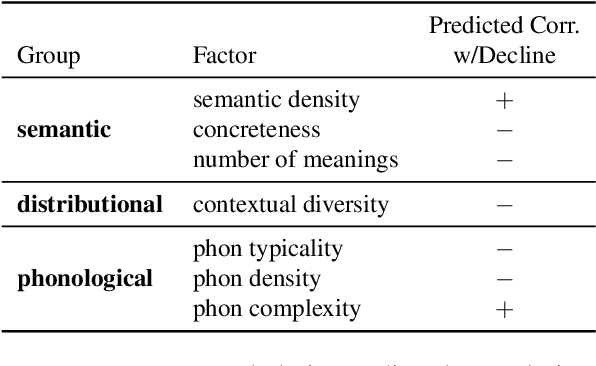

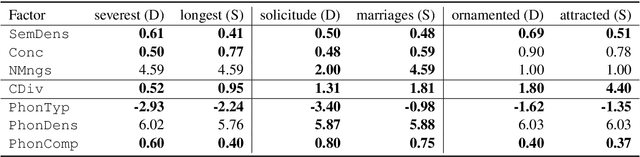
We adopt an evolutionary view on language change in which cognitive factors (in addition to social ones) affect the fitness of words and their success in the linguistic ecosystem. Specifically, we propose a variety of psycholinguistic factors -- semantic, distributional, and phonological -- that we hypothesize are predictive of lexical decline, in which words greatly decrease in frequency over time. Using historical data across three languages (English, French, and German), we find that most of our proposed factors show a significant difference in the expected direction between each curated set of declining words and their matched stable words. Moreover, logistic regression analyses show that semantic and distributional factors are significant in predicting declining words. Further diachronic analysis reveals that declining words tend to decrease in the diversity of their lexical contexts over time, gradually narrowing their 'ecological niches'.
Competition in Cross-situational Word Learning: A Computational Study
Dec 06, 2020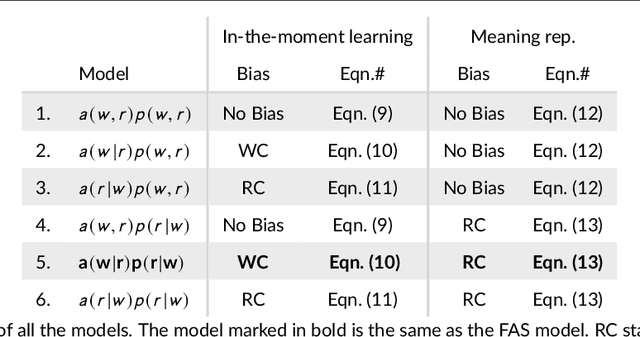

Children learn word meanings by tapping into the commonalities across different situations in which words are used and overcome the high level of uncertainty involved in early word learning experiences. In a set of computational studies, we show that to successfully learn word meanings in the face of uncertainty, a learner needs to use two types of competition: words competing for association to a referent when learning from an observation and referents competing for a word when the word is used.
Pick a Fight or Bite your Tongue: Investigation of Gender Differences in Idiomatic Language Usage
Oct 31, 2020



A large body of research on gender-linked language has established foundations regarding cross-gender differences in lexical, emotional, and topical preferences, along with their sociological underpinnings. We compile a novel, large and diverse corpus of spontaneous linguistic productions annotated with speakers' gender, and perform a first large-scale empirical study of distinctions in the usage of \textit{figurative language} between male and female authors. Our analyses suggest that (1) idiomatic choices reflect gender-specific lexical and semantic preferences in general language, (2) men's and women's idiomatic usages express higher emotion than their literal language, with detectable, albeit more subtle, differences between male and female authors along the dimension of dominance compared to similar distinctions in their literal utterances, and (3) contextual analysis of idiomatic expressions reveals considerable differences, reflecting subtle divergences in usage environments, shaped by cross-gender communication styles and semantic biases.
Exploration of Gender Differences in COVID-19 Discourse on Reddit
Aug 13, 2020



Decades of research on differences in the language of men and women have established postulates about preferences in lexical, topical, and emotional expression between the two genders, along with their sociological underpinnings. Using a novel dataset of male and female linguistic productions collected from the Reddit discussion platform, we further confirm existing assumptions about gender-linked affective distinctions, and demonstrate that these distinctions are amplified in social media postings involving emotionally-charged discourse related to COVID-19. Our analysis also confirms considerable differences in topical preferences between male and female authors in spontaneous pandemic-related discussions.
The Typology of Polysemy: A Multilingual Distributional Framework
Jun 02, 2020



Lexical semantic typology has identified important cross-linguistic generalizations about the variation and commonalities in polysemy patterns---how languages package up meanings into words. Recent computational research has enabled investigation of lexical semantics at a much larger scale, but little work has explored lexical typology across semantic domains, nor the factors that influence cross-linguistic similarities. We present a novel computational framework that quantifies semantic affinity, the cross-linguistic similarity of lexical semantics for a concept. Our approach defines a common multilingual semantic space that enables a direct comparison of the lexical expression of concepts across languages. We validate our framework against empirical findings on lexical semantic typology at both the concept and domain levels. Our results reveal an intricate interaction between semantic domains and extra-linguistic factors, beyond language phylogeny, that co-shape the typology of polysemy across languages.
Say Anything: Automatic Semantic Infelicity Detection in L2 English Indefinite Pronouns
Sep 17, 2019
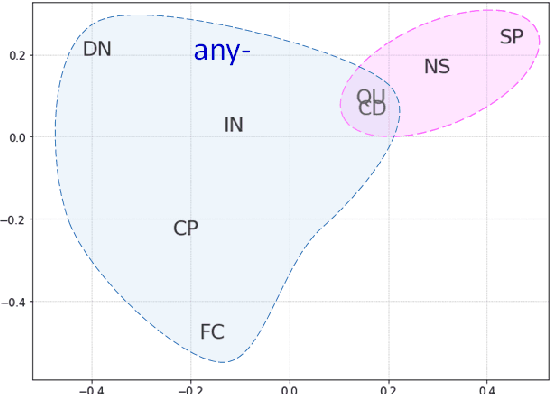

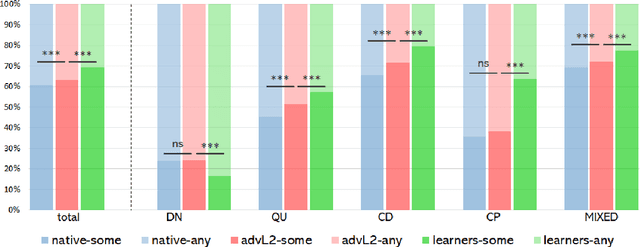
Computational research on error detection in second language speakers has mainly addressed clear grammatical anomalies typical to learners at the beginner-to-intermediate level. We focus instead on acquisition of subtle semantic nuances of English indefinite pronouns by non-native speakers at varying levels of proficiency. We first lay out theoretical, linguistically motivated hypotheses, and supporting empirical evidence on the nature of the challenges posed by indefinite pronouns to English learners. We then suggest and evaluate an automatic approach for detection of atypical usage patterns, demonstrating that deep learning architectures are promising for this task involving nuanced semantic anomalies.
CodeSwitch-Reddit: Exploration of Written Multilingual Discourse in Online Discussion Forums
Aug 30, 2019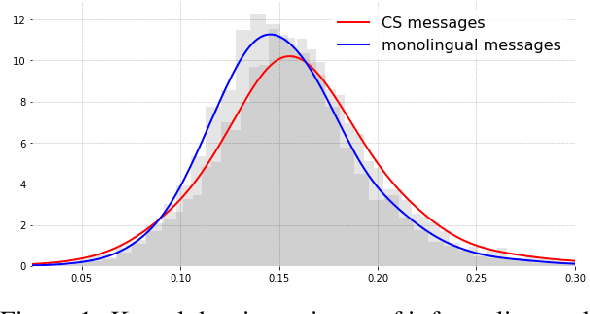



In contrast to many decades of research on oral code-switching, the study of written multilingual productions has only recently enjoyed a surge of interest. Many open questions remain regarding the sociolinguistic underpinnings of written code-switching, and progress has been limited by a lack of suitable resources. We introduce a novel, large, and diverse dataset of written code-switched productions, curated from topical threads of multiple bilingual communities on the Reddit discussion platform, and explore questions that were mainly addressed in the context of spoken language thus far. We investigate whether findings in oral code-switching concerning content and style, as well as speaker proficiency, are carried over into written code-switching in discussion forums. The released dataset can further facilitate a range of research and practical activities.
Predicting and Explaining Human Semantic Search in a Cognitive Model
Nov 29, 2017

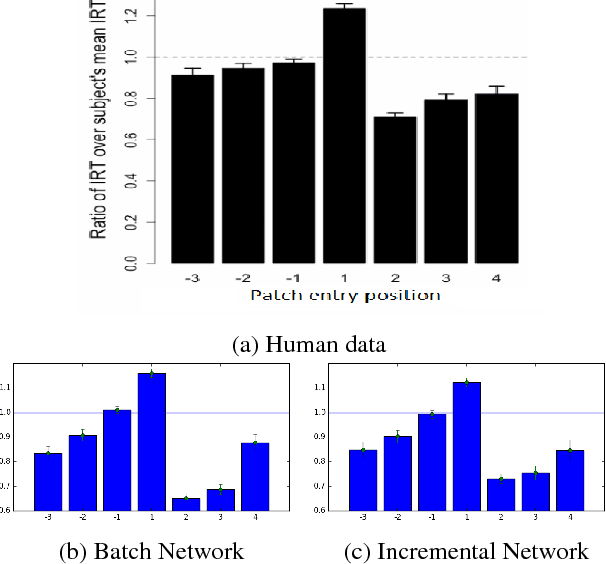
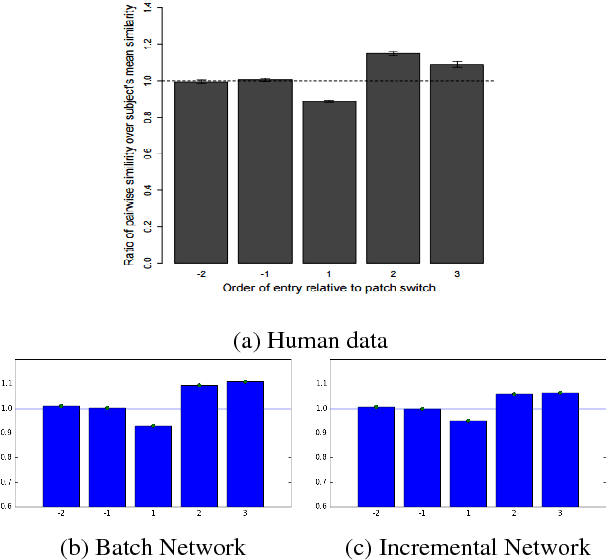
Recent work has attempted to characterize the structure of semantic memory and the search algorithms which, together, best approximate human patterns of search revealed in a semantic fluency task. There are a number of models that seek to capture semantic search processes over networks, but they vary in the cognitive plausibility of their implementation. Existing work has also neglected to consider the constraints that the incremental process of language acquisition must place on the structure of semantic memory. Here we present a model that incrementally updates a semantic network, with limited computational steps, and replicates many patterns found in human semantic fluency using a simple random walk. We also perform thorough analyses showing that a combination of both structural and semantic features are correlated with human performance patterns.