 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeSwitch-Reddit: Exploration of Written Multilingual Discourse in Online Discussion Forums
Paper and Code
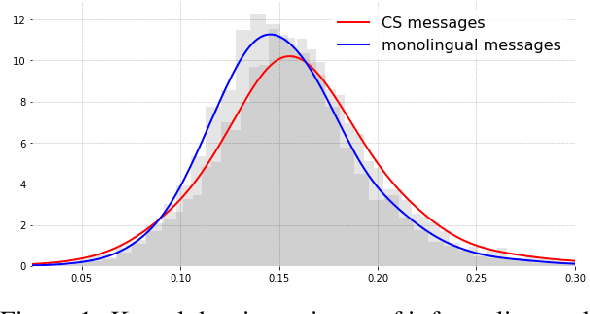



In contrast to many decades of research on oral code-switching, the study of written multilingual productions has only recently enjoyed a surge of interest. Many open questions remain regarding the sociolinguistic underpinnings of written code-switching, and progress has been limited by a lack of suitable resources. We introduce a novel, large, and diverse dataset of written code-switched productions, curated from topical threads of multiple bilingual communities on the Reddit discussion platform, and explore questions that were mainly addressed in the context of spoken language thus far. We investigate whether findings in oral code-switching concerning content and style, as well as speaker proficiency, are carried over into written code-switching in discussion forums. The released dataset can further facilitate a range of research and practical activities.