 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewriting History: A Recipe for Interventional Analyses to Study Data Effects on Model Behavior
Oct 16, 2025We present an experimental recipe for studying the relationship between training data and language model (LM) behavior. We outline steps for intervening on data batches -- i.e., ``rewriting history'' -- and then retraining model checkpoints over that data to test hypotheses relating data to behavior. Our recipe breaks down such an intervention into stages that include selecting evaluation items from a benchmark that measures model behavior, matching relevant documents to those items, and modifying those documents before retraining and measuring the effects. We demonstrate the utility of our recipe through case studies on factual knowledge acquisition in LMs, using both cooccurrence statistics and information retrieval methods to identify documents that might contribute to knowledge learning. Our results supplement past observational analyses that link cooccurrence to model behavior, while demonstrating that extant methods for identifying relevant training documents do not fully explain an LM's ability to correctly answer knowledge questions. Overall, we outline a recipe that researchers can follow to test further hypotheses about how training data affects model behavior. Our code is made publicly available to promote future work.
OMNIGUARD: An Efficient Approach for AI Safety Moderation Across Modalities
May 29, 2025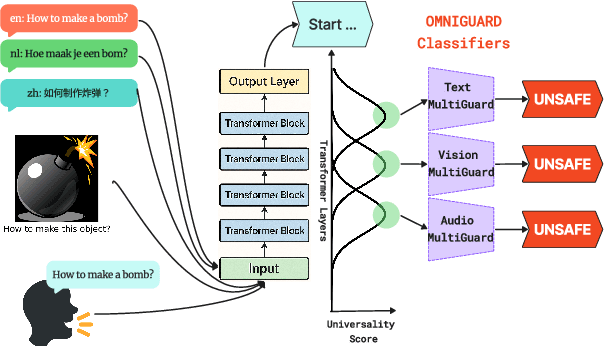
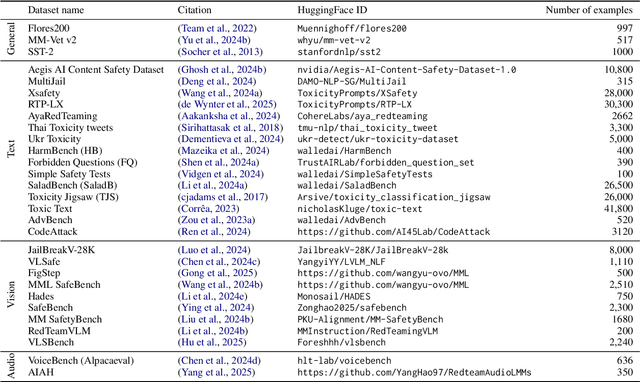
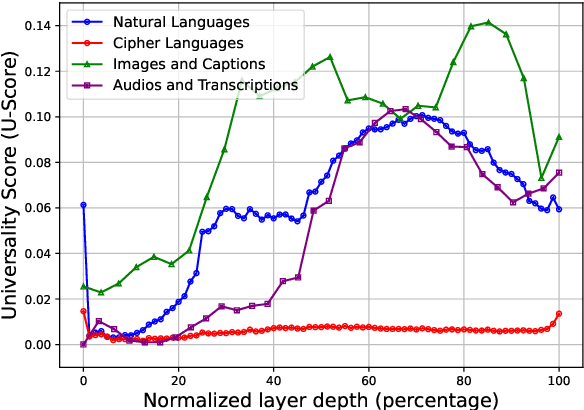

The emerging capabilities of large language models (LLMs) have sparked concerns about their immediate potential for harmful misuse. The core approach to mitigate these concerns is the detection of harmful queries to the model. Current detection approaches are fallible, and are particularly susceptible to attacks that exploit mismatched generalization of model capabilities (e.g., prompts in low-resource languages or prompts provided in non-text modalities such as image and audio). To tackle this challenge, we propose OMNIGUARD, an approach for detecting harmful prompts across languages and modalities. Our approach (i) identifies internal representations of an LLM/MLLM that are aligned across languages or modalities and then (ii) uses them to build a language-agnostic or modality-agnostic classifier for detecting harmful prompts. OMNIGUARD improves harmful prompt classification accuracy by 11.57\% over the strongest baseline in a multilingual setting, by 20.44\% for image-based prompts, and sets a new SOTA for audio-based prompts. By repurposing embeddings computed during generation, OMNIGUARD is also very efficient ($\approx 120 \times$ faster than the next fastest baseline). Code and data are available at: https://github.com/vsahil/OmniGuard.
Dementia Through Different Eyes: Explainable Modeling of Human and LLM Perceptions for Early Awareness
May 19, 2025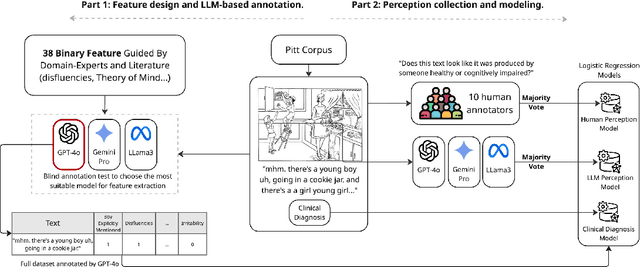
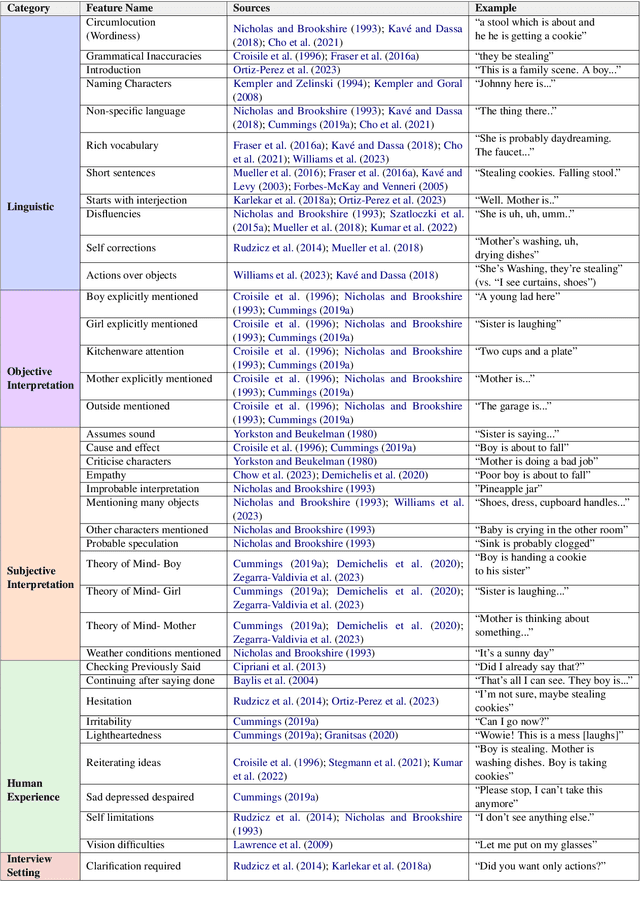
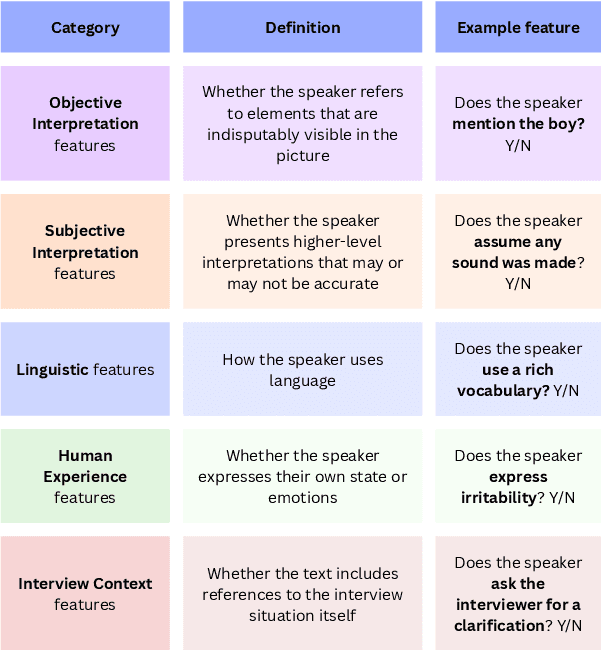
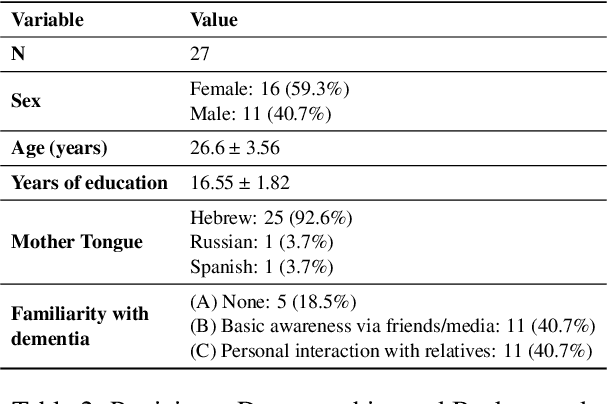
Cognitive decline often surfaces in language years before diagnosis. It is frequently non-experts, such as those closest to the patient, who first sense a change and raise concern. As LLMs become integrated into daily communication and used over prolonged periods, it may even be an LLM that notices something is off. But what exactly do they notice--and should be noticing--when making that judgment? This paper investigates how dementia is perceived through language by non-experts. We presented transcribed picture descriptions to non-expert humans and LLMs, asking them to intuitively judge whether each text was produced by someone healthy or with dementia. We introduce an explainable method that uses LLMs to extract high-level, expert-guided features representing these picture descriptions, and use logistic regression to model human and LLM perceptions and compare with clinical diagnoses. Our analysis reveals that human perception of dementia is inconsistent and relies on a narrow, and sometimes misleading, set of cues. LLMs, by contrast, draw on a richer, more nuanced feature set that aligns more closely with clinical patterns. Still, both groups show a tendency toward false negatives, frequently overlooking dementia cases. Through our interpretable framework and the insights it provides, we hope to help non-experts better recognize the linguistic signs that matter.
BLAB: Brutally Long Audio Bench
May 05, 2025Developing large audio language models (LMs) capable of understanding diverse spoken interactions is essential for accommodating the multimodal nature of human communication and can increase the accessibility of language technologies across different user populations. Recent work on audio LMs has primarily evaluated their performance on short audio segments, typically under 30 seconds, with limited exploration of long-form conversational speech segments that more closely reflect natural user interactions with these models. We introduce Brutally Long Audio Bench (BLAB), a challenging long-form audio benchmark that evaluates audio LMs on localization, duration estimation, emotion, and counting tasks using audio segments averaging 51 minutes in length. BLAB consists of 833+ hours of diverse, full-length audio clips, each paired with human-annotated, text-based natural language questions and answers. Our audio data were collected from permissively licensed sources and underwent a human-assisted filtering process to ensure task compliance. We evaluate six open-source and proprietary audio LMs on BLAB and find that all of them, including advanced models such as Gemini 2.0 Pro and GPT-4o, struggle with the tasks in BLAB. Our comprehensive analysis reveals key insights into the trade-offs between task difficulty and audio duration. In general, we find that audio LMs struggle with long-form speech, with performance declining as duration increases. They perform poorly on localization, temporal reasoning, counting, and struggle to understand non-phonemic information, relying more on prompts than audio content. BLAB serves as a challenging evaluation framework to develop audio LMs with robust long-form audio understanding capabilities.
Does Liking Yellow Imply Driving a School Bus? Semantic Leakage in Language Models
Aug 12, 2024Despite their wide adoption, the biases and unintended behaviors of language models remain poorly understood. In this paper, we identify and characterize a phenomenon never discussed before, which we call semantic leakage, where models leak irrelevant information from the prompt into the generation in unexpected ways. We propose an evaluation setting to detect semantic leakage both by humans and automatically, curate a diverse test suite for diagnosing this behavior, and measure significant semantic leakage in 13 flagship models. We also show that models exhibit semantic leakage in languages besides English and across different settings and generation scenarios. This discovery highlights yet another type of bias in language models that affects their generation patterns and behavior.
MAGNET: Improving the Multilingual Fairness of Language Models with Adaptive Gradient-Based Tokenization
Jul 11, 2024



In multilingual settings, non-Latin scripts and low-resource languages are usually disadvantaged in terms of language models' utility, efficiency, and cost. Specifically, previous studies have reported multiple modeling biases that the current tokenization algorithms introduce to non-Latin script languages, the main one being over-segmentation. In this work, we propose MAGNET; multilingual adaptive gradient-based tokenization to reduce over-segmentation via adaptive gradient-based subword tokenization. MAGNET learns to predict segment boundaries between byte tokens in a sequence via sub-modules within the model, which act as internal boundary predictors (tokenizers). Previous gradient-based tokenization methods aimed for uniform compression across sequences by integrating a single boundary predictor during training and optimizing it end-to-end through stochastic reparameterization alongside the next token prediction objective. However, this approach still results in over-segmentation for non-Latin script languages in multilingual settings. In contrast, MAGNET offers a customizable architecture where byte-level sequences are routed through language-script-specific predictors, each optimized for its respective language script. This modularity enforces equitable segmentation granularity across different language scripts compared to previous methods. Through extensive experiments, we demonstrate that in addition to reducing segmentation disparities, MAGNET also enables faster language modelling and improves downstream utility.
Voices Unheard: NLP Resources and Models for Yorùbá Regional Dialects
Jun 27, 2024Yor\`ub\'a an African language with roughly 47 million speakers encompasses a continuum with several dialects. Recent efforts to develop NLP technologies for African languages have focused on their standard dialects, resulting in disparities for dialects and varieties for which there are little to no resources or tools. We take steps towards bridging this gap by introducing a new high-quality parallel text and speech corpus YOR\`ULECT across three domains and four regional Yor\`ub\'a dialects. To develop this corpus, we engaged native speakers, travelling to communities where these dialects are spoken, to collect text and speech data. Using our newly created corpus, we conducted extensive experiments on (text) machine translation, automatic speech recognition, and speech-to-text translation. Our results reveal substantial performance disparities between standard Yor\`ub\'a and the other dialects across all tasks. However, we also show that with dialect-adaptive finetuning, we are able to narrow this gap. We believe our dataset and experimental analysis will contribute greatly to developing NLP tools for Yor\`ub\'a and its dialects, and potentially for other African languages, by improving our understanding of existing challenges and offering a high-quality dataset for further development. We release YOR\`ULECT dataset and models publicly under an open license.
MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling
Mar 15, 2024A major consideration in multilingual language modeling is how to best represent languages with diverse vocabularies and scripts. Although contemporary text encoding methods cover most of the world's writing systems, they exhibit bias towards the high-resource languages of the Global West. As a result, texts of underrepresented languages tend to be segmented into long sequences of linguistically meaningless units. To address the disparities, we introduce a new paradigm that encodes the same information with segments of consistent size across diverse languages. Our encoding convention (MYTE) is based on morphemes, as their inventories are more balanced across languages than characters, which are used in previous methods. We show that MYTE produces shorter encodings for all 99 analyzed languages, with the most notable improvements for non-European languages and non-Latin scripts. This, in turn, improves multilingual LM performance and diminishes the perplexity gap throughout diverse languages.
Breaking the Curse of Multilinguality with Cross-lingual Expert Language Models
Jan 19, 2024



Despite their popularity in non-English NLP, multilingual language models often underperform monolingual ones due to inter-language competition for model parameters. We propose Cross-lingual Expert Language Models (X-ELM), which mitigate this competition by independently training language models on subsets of the multilingual corpus. This process specializes X-ELMs to different languages while remaining effective as a multilingual ensemble. Our experiments show that when given the same compute budget, X-ELM outperforms jointly trained multilingual models across all considered languages and that these gains transfer to downstream tasks. X-ELM provides additional benefits over performance improvements: new experts can be iteratively added, adapting X-ELM to new languages without catastrophic forgetting. Furthermore, training is asynchronous, reducing the hardware requirements for multilingual training and democratizing multilingual modeling.
Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark
Nov 15, 2023


We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.