 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractalBench: Diagnosing Visual-Mathematical Reasoning Through Recursive Program Synthesis
Nov 09, 2025Mathematical reasoning requires abstracting symbolic rules from visual patterns -- inferring the infinite from the finite. We investigate whether multimodal AI systems possess this capability through FractalBench, a benchmark evaluating fractal program synthesis from images. Fractals provide ideal test cases: Iterated Function Systems with only a few contraction maps generate complex self-similar patterns through simple recursive rules, requiring models to bridge visual perception with mathematical abstraction. We evaluate four leading MLLMs -- GPT-4o, Claude 3.7 Sonnet, Gemini 2.5 Flash, and Qwen 2.5-VL -- on 12 canonical fractals. Models must generate executable Python code reproducing the fractal, enabling objective evaluation. Results reveal a striking disconnect: 76% generate syntactically valid code but only 4% capture mathematical structure. Success varies systematically -- models handle geometric transformations (Koch curves: 17-21%) but fail at branching recursion (trees: <2%), revealing fundamental gaps in mathematical abstraction. FractalBench provides a contamination-resistant diagnostic for visual-mathematical reasoning and is available at https://github.com/NaiveNeuron/FractalBench
skLEP: A Slovak General Language Understanding Benchmark
Jun 26, 2025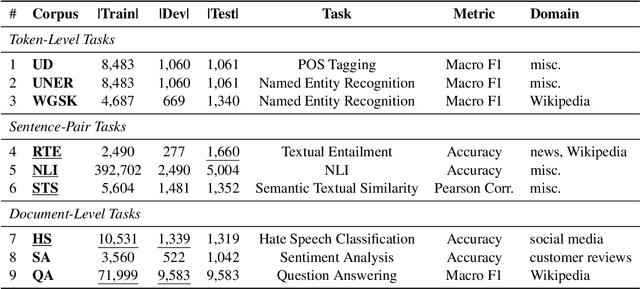

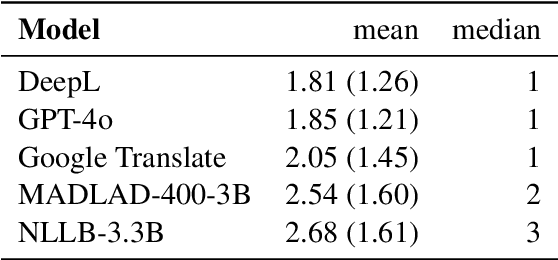
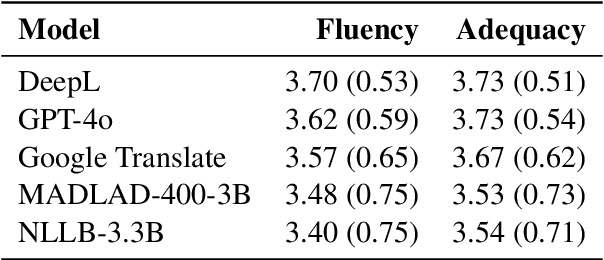
In this work, we introduce skLEP, the first comprehensive benchmark specifically designed for evaluating Slovak natural language understanding (NLU) models. We have compiled skLEP to encompass nine diverse tasks that span token-level, sentence-pair, and document-level challenges, thereby offering a thorough assessment of model capabilities. To create this benchmark, we curated new, original datasets tailored for Slovak and meticulously translated established English NLU resources. Within this paper, we also present the first systematic and extensive evaluation of a wide array of Slovak-specific, multilingual, and English pre-trained language models using the skLEP tasks. Finally, we also release the complete benchmark data, an open-source toolkit facilitating both fine-tuning and evaluation of models, and a public leaderboard at https://github.com/slovak-nlp/sklep in the hopes of fostering reproducibility and drive future research in Slovak NLU.
LCDC: Bridging Science and Machine Learning for Light Curve Analysis
Apr 14, 2025



The characterization and analysis of light curves are vital for understanding the physical and rotational properties of artificial space objects such as satellites, rocket stages, and space debris. This paper introduces the Light Curve Dataset Creator (LCDC), a Python-based toolkit designed to facilitate the preprocessing, analysis, and machine learning applications of light curve data. LCDC enables seamless integration with publicly available datasets, such as the newly introduced Mini Mega Tortora (MMT) database. Moreover, it offers data filtering, transformation, as well as feature extraction tooling. To demonstrate the toolkit's capabilities, we created the first standardized dataset for rocket body classification, RoBo6, which was used to train and evaluate several benchmark machine learning models, addressing the lack of reproducibility and comparability in recent studies. Furthermore, the toolkit enables advanced scientific analyses, such as surface characterization of the Atlas 2AS Centaur and the rotational dynamics of the Delta 4 rocket body, by streamlining data preprocessing, feature extraction, and visualization. These use cases highlight LCDC's potential to advance space debris characterization and promote sustainable space exploration. Additionally, they highlight the toolkit's ability to enable AI-focused research within the space debris community.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
RoBo6: Standardized MMT Light Curve Dataset for Rocket Body Classification
Nov 30, 2024Space debris presents a critical challenge for the sustainability of future space missions, emphasizing the need for robust and standardized identification methods. However, a comprehensive benchmark for rocket body classification remains absent. This paper addresses this gap by introducing the RoBo6 dataset for rocket body classification based on light curves. The dataset, derived from the Mini Mega Tortora database, includes light curves for six rocket body classes: CZ-3B, Atlas 5 Centaur, Falcon 9, H-2A, Ariane 5, and Delta 4. With 5,676 training and 1,404 test samples, it addresses data inconsistencies using resampling, normalization, and filtering techniques. Several machine learning models were evaluated, including CNN and transformer-based approaches, with Astroconformer reporting the best performance. The dataset establishes a common benchmark for future comparisons and advancements in rocket body classification tasks.
Bryndza at ClimateActivism 2024: Stance, Target and Hate Event Detection via Retrieval-Augmented GPT-4 and LLaMA
Feb 09, 2024This study details our approach for the CASE 2024 Shared Task on Climate Activism Stance and Hate Event Detection, focusing on Hate Speech Detection, Hate Speech Target Identification, and Stance Detection as classification challenges. We explored the capability of Large Language Models (LLMs), particularly GPT-4, in zero- or few-shot settings enhanced by retrieval augmentation and re-ranking for Tweet classification. Our goal was to determine if LLMs could match or surpass traditional methods in this context. We conducted an ablation study with LLaMA for comparison, and our results indicate that our models significantly outperformed the baselines, securing second place in the Target Detection task. The code for our submission is available at https://github.com/NaiveNeuron/bryndza-case-2024
Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark
Nov 15, 2023
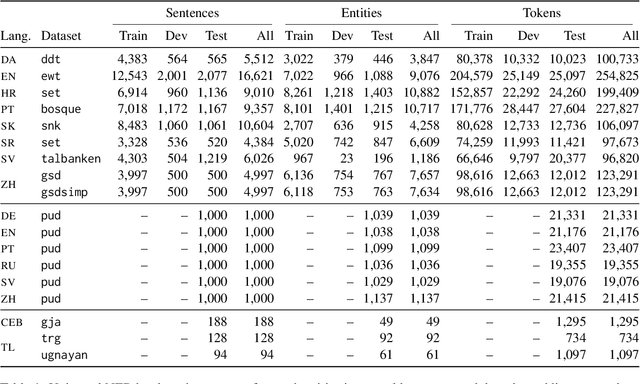


We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.
WikiGoldSK: Annotated Dataset, Baselines and Few-Shot Learning Experiments for Slovak Named Entity Recognition
Apr 08, 2023



Named Entity Recognition (NER) is a fundamental NLP tasks with a wide range of practical applications. The performance of state-of-the-art NER methods depends on high quality manually anotated datasets which still do not exist for some languages. In this work we aim to remedy this situation in Slovak by introducing WikiGoldSK, the first sizable human labelled Slovak NER dataset. We benchmark it by evaluating state-of-the-art multilingual Pretrained Language Models and comparing it to the existing silver-standard Slovak NER dataset. We also conduct few-shot experiments and show that training on a sliver-standard dataset yields better results. To enable future work that can be based on Slovak NER, we release the dataset, code, as well as the trained models publicly under permissible licensing terms at https://github.com/NaiveNeuron/WikiGoldSK.
WaveGlove: Transformer-based hand gesture recognition using multiple inertial sensors
May 04, 2021



Hand Gesture Recognition (HGR) based on inertial data has grown considerably in recent years, with the state-of-the-art approaches utilizing a single handheld sensor and a vocabulary comprised of simple gestures. In this work we explore the benefits of using multiple inertial sensors. Using WaveGlove, a custom hardware prototype in the form of a glove with five inertial sensors, we acquire two datasets consisting of over $11000$ samples. To make them comparable with prior work, they are normalized along with $9$ other publicly available datasets, and subsequently used to evaluate a range of Machine Learning approaches for gesture recognition, including a newly proposed Transformer-based architecture. Our results show that even complex gestures involving different fingers can be recognized with high accuracy. An ablation study performed on the acquired datasets demonstrates the importance of multiple sensors, with an increase in performance when using up to three sensors and no significant improvements beyond that.
Cost-effective Deployment of BERT Models in Serverless Environment
Mar 19, 2021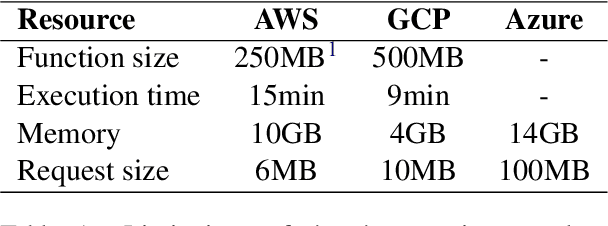
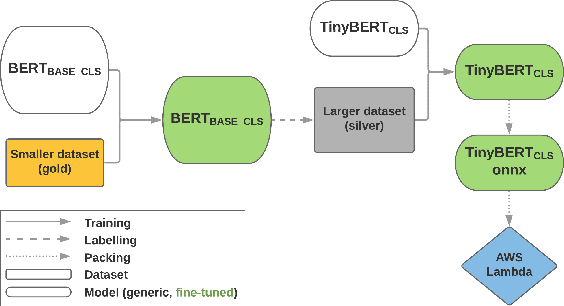

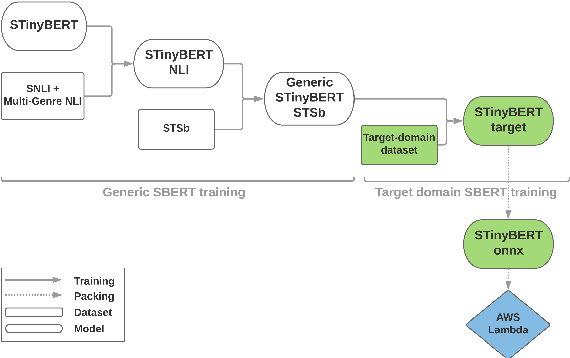
In this study we demonstrate the viability of deploying BERT-style models to AWS Lambda in a production environment. Since the freely available pre-trained models are too large to be deployed in this way, we utilize knowledge distillation and fine-tune the models on proprietary datasets for two real-world tasks: sentiment analysis and semantic textual similarity. As a result, we obtain models that are tuned for a specific domain and deployable in the serverless environment. The subsequent performance analysis shows that this solution does not only report latency levels acceptable for production use but that it is also a cost-effective alternative to small-to-medium size deployments of BERT models, all without any infrastructure overhead.