 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoActor: Grounding Task Planning into Spatial-aware Egocentric Actions for Humanoid Robots via Visual-Language Models
Feb 04, 2026Deploying humanoid robots in real-world settings is fundamentally challenging, as it demands tight integration of perception, locomotion, and manipulation under partial-information observations and dynamically changing environments. As well as transitioning robustly between sub-tasks of different types. Towards addressing these challenges, we propose a novel task - EgoActing, which requires directly grounding high-level instructions into various, precise, spatially aware humanoid actions. We further instantiate this task by introducing EgoActor, a unified and scalable vision-language model (VLM) that can predict locomotion primitives (e.g., walk, turn, move sideways, change height), head movements, manipulation commands, and human-robot interactions to coordinate perception and execution in real-time. We leverage broad supervision over egocentric RGB-only data from real-world demonstrations, spatial reasoning question-answering, and simulated environment demonstrations, enabling EgoActor to make robust, context-aware decisions and perform fluent action inference (under 1s) with both 8B and 4B parameter models. Extensive evaluations in both simulated and real-world environments demonstrate that EgoActor effectively bridges abstract task planning and concrete motor execution, while generalizing across diverse tasks and unseen environments.
RANGER: A Monocular Zero-Shot Semantic Navigation Framework through Contextual Adaptation
Dec 30, 2025Efficiently finding targets in complex environments is fundamental to real-world embodied applications. While recent advances in multimodal foundation models have enabled zero-shot object goal navigation, allowing robots to search for arbitrary objects without fine-tuning, existing methods face two key limitations: (1) heavy reliance on precise depth and pose information provided by simulators, which restricts applicability in real-world scenarios; and (2) lack of in-context learning (ICL) capability, making it difficult to quickly adapt to new environments, as in leveraging short videos. To address these challenges, we propose RANGER, a novel zero-shot, open-vocabulary semantic navigation framework that operates using only a monocular camera. Leveraging powerful 3D foundation models, RANGER eliminates the dependency on depth and pose while exhibiting strong ICL capability. By simply observing a short video of a new environment, the system can also significantly improve task efficiency without requiring architectural modifications or fine-tuning. The framework integrates several key components: keyframe-based 3D reconstruction, semantic point cloud generation, vision-language model (VLM)-driven exploration value estimation, high-level adaptive waypoint selection, and low-level action execution. Experiments on the HM3D benchmark and real-world environments demonstrate that RANGER achieves competitive performance in terms of navigation success rate and exploration efficiency, while showing superior ICL adaptability, with no previous 3D mapping of the environment required.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025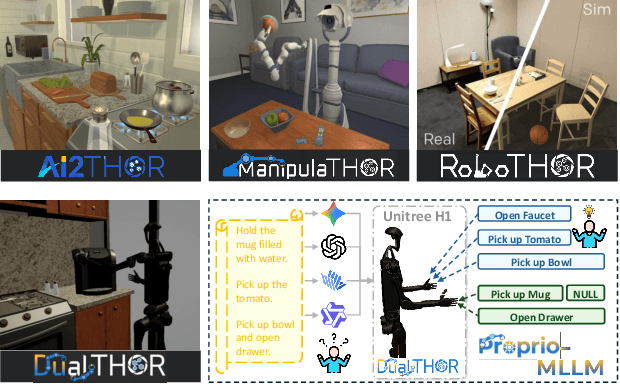


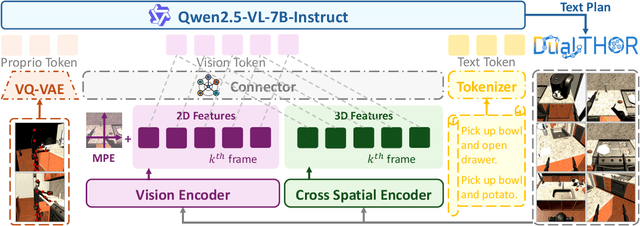
In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Aug 07, 2025Although Vision Language Models (VLMs) exhibit strong perceptual abilities and impressive visual reasoning, they struggle with attention to detail and precise action planning in complex, dynamic environments, leading to subpar performance. Real-world tasks typically require complex interactions, advanced spatial reasoning, long-term planning, and continuous strategy refinement, usually necessitating understanding the physics rules of the target scenario. However, evaluating these capabilities in real-world scenarios is often prohibitively expensive. To bridge this gap, we introduce DeepPHY, a novel benchmark framework designed to systematically evaluate VLMs' understanding and reasoning about fundamental physical principles through a series of challenging simulated environments. DeepPHY integrates multiple physical reasoning environments of varying difficulty levels and incorporates fine-grained evaluation metrics. Our evaluation finds that even state-of-the-art VLMs struggle to translate descriptive physical knowledge into precise, predictive control.
Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills
Mar 16, 2025Building autonomous robotic agents capable of achieving human-level performance in real-world embodied tasks is an ultimate goal in humanoid robot research. Recent advances have made significant progress in high-level cognition with Foundation Models (FMs) and low-level skill development for humanoid robots. However, directly combining these components often results in poor robustness and efficiency due to compounding errors in long-horizon tasks and the varied latency of different modules. We introduce Being-0, a hierarchical agent framework that integrates an FM with a modular skill library. The FM handles high-level cognitive tasks such as instruction understanding, task planning, and reasoning, while the skill library provides stable locomotion and dexterous manipulation for low-level control. To bridge the gap between these levels, we propose a novel Connector module, powered by a lightweight vision-language model (VLM). The Connector enhances the FM's embodied capabilities by translating language-based plans into actionable skill commands and dynamically coordinating locomotion and manipulation to improve task success. With all components, except the FM, deployable on low-cost onboard computation devices, Being-0 achieves efficient, real-time performance on a full-sized humanoid robot equipped with dexterous hands and active vision. Extensive experiments in large indoor environments demonstrate Being-0's effectiveness in solving complex, long-horizon tasks that require challenging navigation and manipulation subtasks. For further details and videos, visit https://beingbeyond.github.io/being-0.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Taking Notes Brings Focus? Towards Multi-Turn Multimodal Dialogue Learning
Mar 10, 2025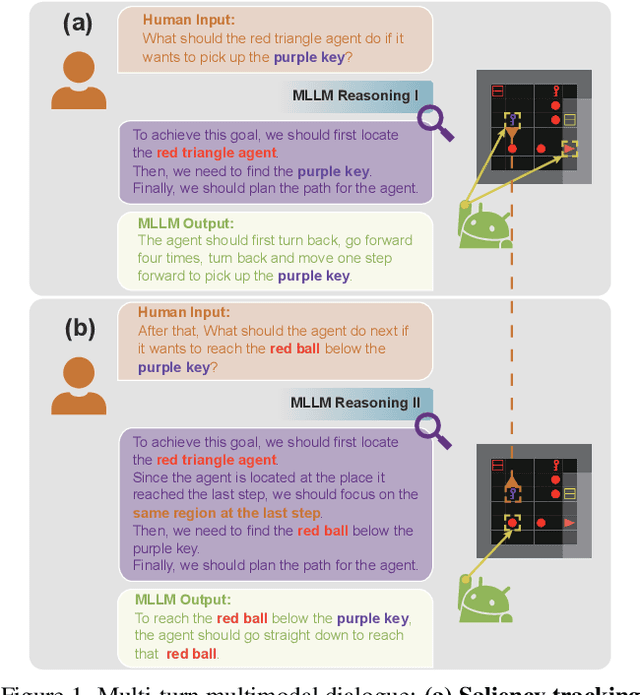

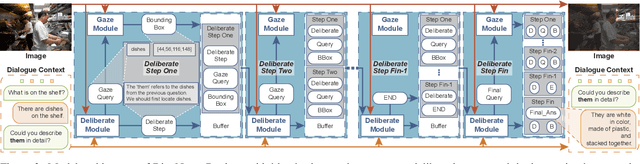
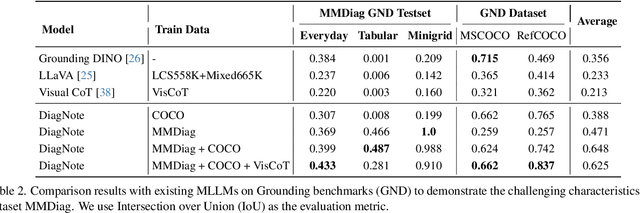
Multimodal large language models (MLLMs), built on large-scale pre-trained vision towers and language models, have shown great capabilities in multimodal understanding. However, most existing MLLMs are trained on single-turn vision question-answering tasks, which do not accurately reflect real-world human conversations. In this paper, we introduce MMDiag, a multi-turn multimodal dialogue dataset. This dataset is collaboratively generated through deliberately designed rules and GPT assistance, featuring strong correlations between questions, between questions and images, and among different image regions; thus aligning more closely with real-world scenarios. MMDiag serves as a strong benchmark for multi-turn multimodal dialogue learning and brings more challenges to the grounding and reasoning capabilities of MLLMs. Further, inspired by human vision processing, we present DiagNote, an MLLM equipped with multimodal grounding and reasoning capabilities. DiagNote consists of two modules (Deliberate and Gaze) interacting with each other to perform Chain-of-Thought and annotations respectively, throughout multi-turn dialogues. We empirically demonstrate the advantages of DiagNote in both grounding and jointly processing and reasoning with vision and language information over existing MLLMs.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
MLLM as Retriever: Interactively Learning Multimodal Retrieval for Embodied Agents
Oct 04, 2024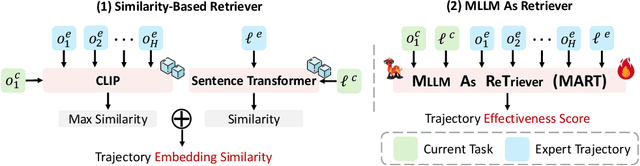

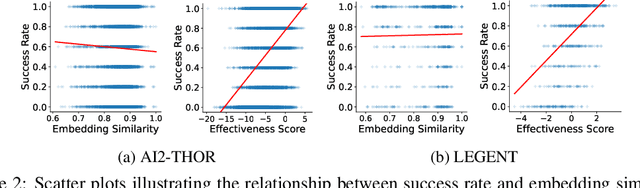
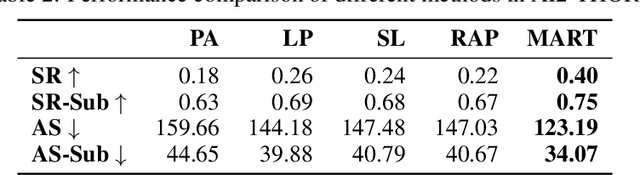
MLLM agents demonstrate potential for complex embodied tasks by retrieving multimodal task-relevant trajectory data. However, current retrieval methods primarily focus on surface-level similarities of textual or visual cues in trajectories, neglecting their effectiveness for the specific task at hand. To address this issue, we propose a novel method, MLLM as ReTriever (MART), which enhances the performance of embodied agents by utilizing interaction data to fine-tune an MLLM retriever based on preference learning, such that the retriever fully considers the effectiveness of trajectories and prioritize them for unseen tasks. We also introduce Trajectory Abstraction, a mechanism that leverages MLLMs' summarization capabilities to represent trajectories with fewer tokens while preserving key information, enabling agents to better comprehend milestones in the trajectory. Experimental results across various environments demonstrate our method significantly improves task success rates in unseen scenes compared to baseline methods. This work presents a new paradigm for multimodal retrieval in embodied agents, by fine-tuning a general-purpose MLLM as the retriever to assess trajectory effectiveness. All benchmark task sets and simulator code modifications for action and observation spaces will be released.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024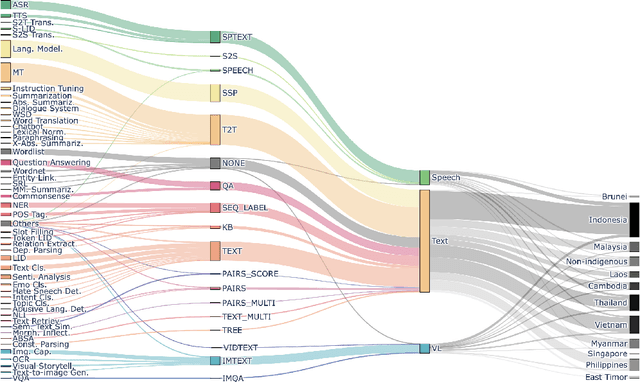
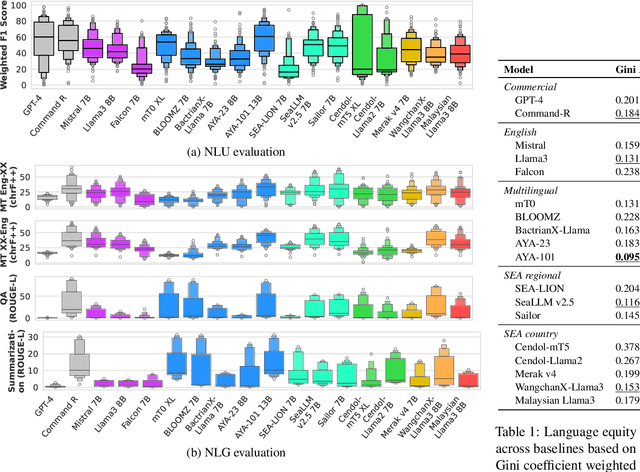
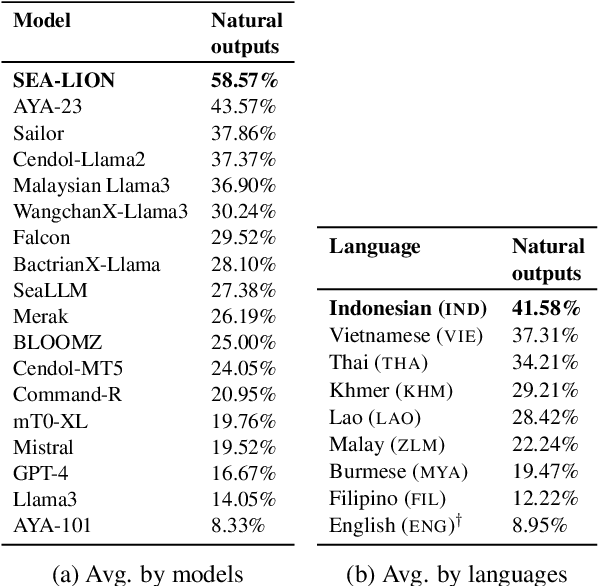
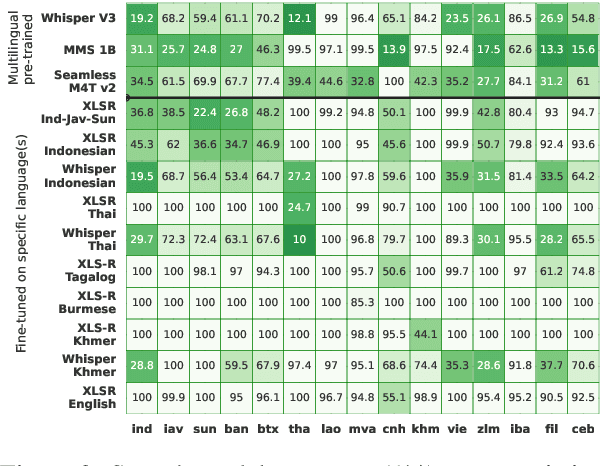
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.