 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM as Retriever: Interactively Learning Multimodal Retrieval for Embodied Agents
Oct 04, 2024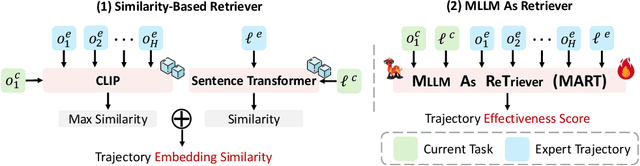

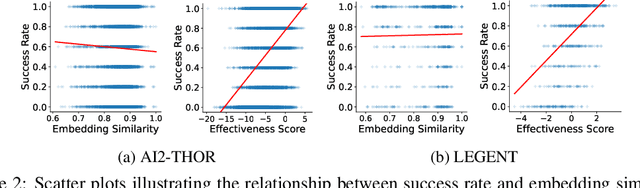
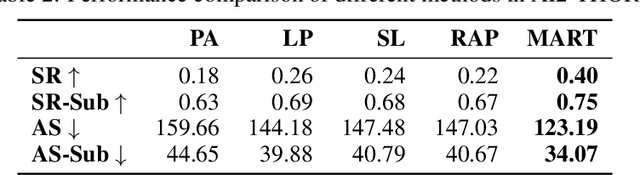
MLLM agents demonstrate potential for complex embodied tasks by retrieving multimodal task-relevant trajectory data. However, current retrieval methods primarily focus on surface-level similarities of textual or visual cues in trajectories, neglecting their effectiveness for the specific task at hand. To address this issue, we propose a novel method, MLLM as ReTriever (MART), which enhances the performance of embodied agents by utilizing interaction data to fine-tune an MLLM retriever based on preference learning, such that the retriever fully considers the effectiveness of trajectories and prioritize them for unseen tasks. We also introduce Trajectory Abstraction, a mechanism that leverages MLLMs' summarization capabilities to represent trajectories with fewer tokens while preserving key information, enabling agents to better comprehend milestones in the trajectory. Experimental results across various environments demonstrate our method significantly improves task success rates in unseen scenes compared to baseline methods. This work presents a new paradigm for multimodal retrieval in embodied agents, by fine-tuning a general-purpose MLLM as the retriever to assess trajectory effectiveness. All benchmark task sets and simulator code modifications for action and observation spaces will be released.
NeuralDome: A Neural Modeling Pipeline on Multi-View Human-Object Interactions
Dec 15, 2022
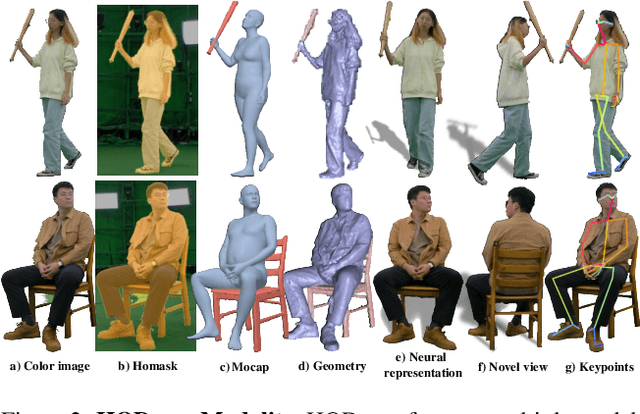
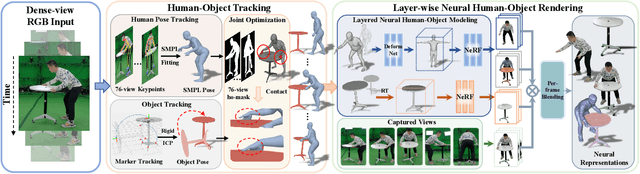
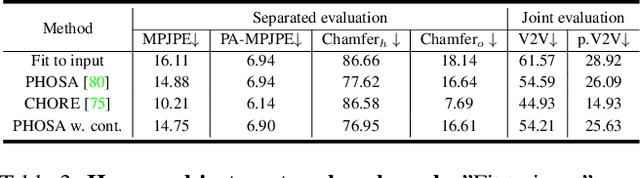
Humans constantly interact with objects in daily life tasks. Capturing such processes and subsequently conducting visual inferences from a fixed viewpoint suffers from occlusions, shape and texture ambiguities, motions, etc. To mitigate the problem, it is essential to build a training dataset that captures free-viewpoint interactions. We construct a dense multi-view dome to acquire a complex human object interaction dataset, named HODome, that consists of $\sim$75M frames on 10 subjects interacting with 23 objects. To process the HODome dataset, we develop NeuralDome, a layer-wise neural processing pipeline tailored for multi-view video inputs to conduct accurate tracking, geometry reconstruction and free-view rendering, for both human subjects and objects. Extensive experiments on the HODome dataset demonstrate the effectiveness of NeuralDome on a variety of inference, modeling, and rendering tasks. Both the dataset and the NeuralDome tools will be disseminated to the community for further development.