 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianHair: Hair Modeling and Rendering with Light-aware Gaussians
Feb 16, 2024


Hairstyle reflects culture and ethnicity at first glance. In the digital era, various realistic human hairstyles are also critical to high-fidelity digital human assets for beauty and inclusivity. Yet, realistic hair modeling and real-time rendering for animation is a formidable challenge due to its sheer number of strands, complicated structures of geometry, and sophisticated interaction with light. This paper presents GaussianHair, a novel explicit hair representation. It enables comprehensive modeling of hair geometry and appearance from images, fostering innovative illumination effects and dynamic animation capabilities. At the heart of GaussianHair is the novel concept of representing each hair strand as a sequence of connected cylindrical 3D Gaussian primitives. This approach not only retains the hair's geometric structure and appearance but also allows for efficient rasterization onto a 2D image plane, facilitating differentiable volumetric rendering. We further enhance this model with the "GaussianHair Scattering Model", adept at recreating the slender structure of hair strands and accurately capturing their local diffuse color in uniform lighting. Through extensive experiments, we substantiate that GaussianHair achieves breakthroughs in both geometric and appearance fidelity, transcending the limitations encountered in state-of-the-art methods for hair reconstruction. Beyond representation, GaussianHair extends to support editing, relighting, and dynamic rendering of hair, offering seamless integration with conventional CG pipeline workflows. Complementing these advancements, we have compiled an extensive dataset of real human hair, each with meticulously detailed strand geometry, to propel further research in this field.
MVHuman: Tailoring 2D Diffusion with Multi-view Sampling For Realistic 3D Human Generation
Dec 15, 2023Recent months have witnessed rapid progress in 3D generation based on diffusion models. Most advances require fine-tuning existing 2D Stable Diffsuions into multi-view settings or tedious distilling operations and hence fall short of 3D human generation due to the lack of diverse 3D human datasets. We present an alternative scheme named MVHuman to generate human radiance fields from text guidance, with consistent multi-view images directly sampled from pre-trained Stable Diffsuions without any fine-tuning or distilling. Our core is a multi-view sampling strategy to tailor the denoising processes of the pre-trained network for generating consistent multi-view images. It encompasses view-consistent conditioning, replacing the original noises with ``consistency-guided noises'', optimizing latent codes, as well as utilizing cross-view attention layers. With the multi-view images through the sampling process, we adopt geometry refinement and 3D radiance field generation followed by a subsequent neural blending scheme for free-view rendering. Extensive experiments demonstrate the efficacy of our method, as well as its superiority to state-of-the-art 3D human generation methods.
Instant-NVR: Instant Neural Volumetric Rendering for Human-object Interactions from Monocular RGBD Stream
Apr 06, 2023Convenient 4D modeling of human-object interactions is essential for numerous applications. However, monocular tracking and rendering of complex interaction scenarios remain challenging. In this paper, we propose Instant-NVR, a neural approach for instant volumetric human-object tracking and rendering using a single RGBD camera. It bridges traditional non-rigid tracking with recent instant radiance field techniques via a multi-thread tracking-rendering mechanism. In the tracking front-end, we adopt a robust human-object capture scheme to provide sufficient motion priors. We further introduce a separated instant neural representation with a novel hybrid deformation module for the interacting scene. We also provide an on-the-fly reconstruction scheme of the dynamic/static radiance fields via efficient motion-prior searching. Moreover, we introduce an online key frame selection scheme and a rendering-aware refinement strategy to significantly improve the appearance details for online novel-view synthesis. Extensive experiments demonstrate the effectiveness and efficiency of our approach for the instant generation of human-object radiance fields on the fly, notably achieving real-time photo-realistic novel view synthesis under complex human-object interactions.
NEPHELE: A Neural Platform for Highly Realistic Cloud Radiance Rendering
Mar 07, 2023We have recently seen tremendous progress in neural rendering (NR) advances, i.e., NeRF, for photo-real free-view synthesis. Yet, as a local technique based on a single computer/GPU, even the best-engineered Instant-NGP or i-NGP cannot reach real-time performance when rendering at a high resolution, and often requires huge local computing resources. In this paper, we resort to cloud rendering and present NEPHELE, a neural platform for highly realistic cloud radiance rendering. In stark contrast with existing NR approaches, our NEPHELE allows for more powerful rendering capabilities by combining multiple remote GPUs and facilitates collaboration by allowing multiple people to view the same NeRF scene simultaneously. We introduce i-NOLF to employ opacity light fields for ultra-fast neural radiance rendering in a one-query-per-ray manner. We further resemble the Lumigraph with geometry proxies for fast ray querying and subsequently employ a small MLP to model the local opacity lumishperes for high-quality rendering. We also adopt Perfect Spatial Hashing in i-NOLF to enhance cache coherence. As a result, our i-NOLF achieves an order of magnitude performance gain in terms of efficiency than i-NGP, especially for the multi-user multi-viewpoint setting under cloud rendering scenarios. We further tailor a task scheduler accompanied by our i-NOLF representation and demonstrate the advance of our methodological design through a comprehensive cloud platform, consisting of a series of cooperated modules, i.e., render farms, task assigner, frame composer, and detailed streaming strategies. Using such a cloud platform compatible with neural rendering, we further showcase the capabilities of our cloud radiance rendering through a series of applications, ranging from cloud VR/AR rendering.
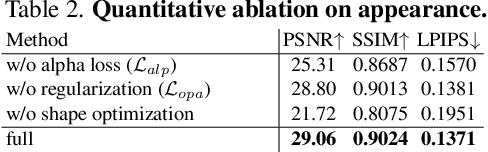
NeuralDome: A Neural Modeling Pipeline on Multi-View Human-Object Interactions
Dec 15, 2022
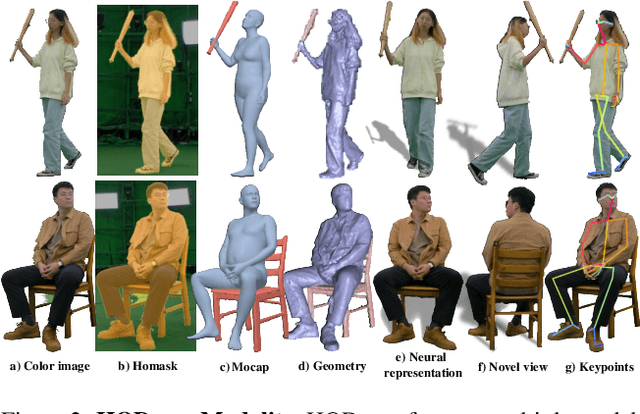
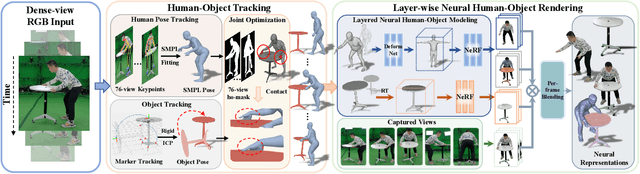
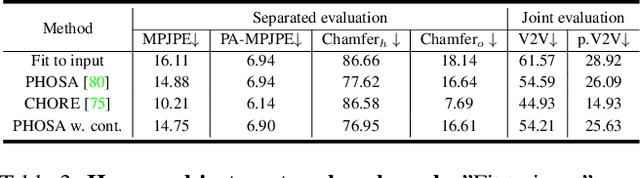
Humans constantly interact with objects in daily life tasks. Capturing such processes and subsequently conducting visual inferences from a fixed viewpoint suffers from occlusions, shape and texture ambiguities, motions, etc. To mitigate the problem, it is essential to build a training dataset that captures free-viewpoint interactions. We construct a dense multi-view dome to acquire a complex human object interaction dataset, named HODome, that consists of $\sim$75M frames on 10 subjects interacting with 23 objects. To process the HODome dataset, we develop NeuralDome, a layer-wise neural processing pipeline tailored for multi-view video inputs to conduct accurate tracking, geometry reconstruction and free-view rendering, for both human subjects and objects. Extensive experiments on the HODome dataset demonstrate the effectiveness of NeuralDome on a variety of inference, modeling, and rendering tasks. Both the dataset and the NeuralDome tools will be disseminated to the community for further development.
HumanGen: Generating Human Radiance Fields with Explicit Priors
Dec 10, 2022



Recent years have witnessed the tremendous progress of 3D GANs for generating view-consistent radiance fields with photo-realism. Yet, high-quality generation of human radiance fields remains challenging, partially due to the limited human-related priors adopted in existing methods. We present HumanGen, a novel 3D human generation scheme with detailed geometry and $\text{360}^{\circ}$ realistic free-view rendering. It explicitly marries the 3D human generation with various priors from the 2D generator and 3D reconstructor of humans through the design of "anchor image". We introduce a hybrid feature representation using the anchor image to bridge the latent space of HumanGen with the existing 2D generator. We then adopt a pronged design to disentangle the generation of geometry and appearance. With the aid of the anchor image, we adapt a 3D reconstructor for fine-grained details synthesis and propose a two-stage blending scheme to boost appearance generation. Extensive experiments demonstrate our effectiveness for state-of-the-art 3D human generation regarding geometry details, texture quality, and free-view performance. Notably, HumanGen can also incorporate various off-the-shelf 2D latent editing methods, seamlessly lifting them into 3D.
Artemis: Articulated Neural Pets with Appearance and Motion synthesis
Feb 11, 2022
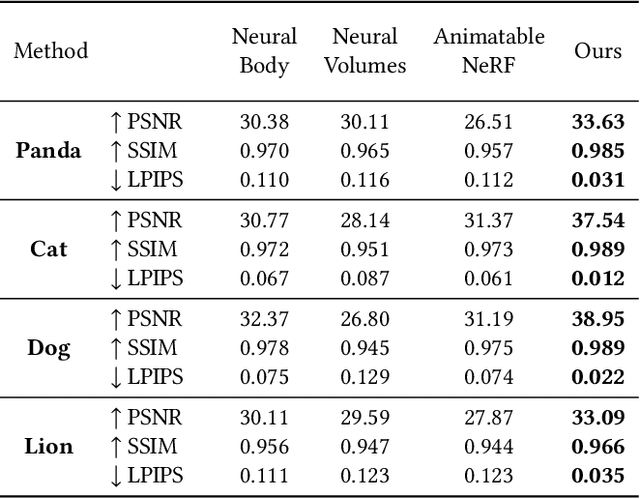
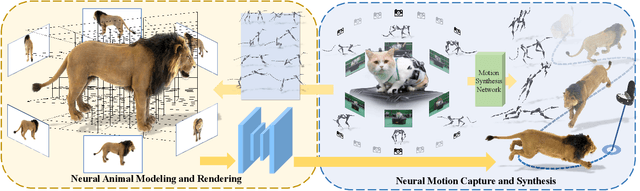
We human are entering into a virtual era, and surely want to bring animals to virtual world as well for companion. Yet, computer-generated (CGI) furry animals is limited by tedious off-line rendering, let alone interactive motion control. In this paper, we present ARTEMIS, a novel neural modeling and rendering pipeline for generating ARTiculated neural pets with appEarance and Motion synthesIS. Our ARTEMIS enables interactive motion control, real-time animation and photo-realistic rendering of furry animals. The core of ARTEMIS is a neural-generated (NGI) animal engine, which adopts an efficient octree based representation for animal animation and fur rendering. The animation then becomes equivalent to voxel level skeleton based deformation. We further use a fast octree indexing, an efficient volumetric rendering scheme to generate appearance and density features maps. Finally, we propose a novel shading network to generate high-fidelity details of appearance and opacity under novel poses. For the motion control module in ARTEMIS, we combine state-of-the-art animal motion capture approach with neural character control scheme. We introduce an effective optimization scheme to reconstruct skeletal motion of real animals captured by a multi-view RGB and Vicon camera array. We feed the captured motion into a neural character control scheme to generate abstract control signals with motion styles. We further integrate ARTEMIS into existing engines that support VR headsets, providing an unprecedented immersive experience where a user can intimately interact with a variety of virtual animals with vivid movements and photo-realistic appearance. Extensive experiments and showcases demonstrate the effectiveness of our ARTEMIS system to achieve highly realistic rendering of NGI animals in real-time, providing daily immersive and interactive experience with digital animals unseen before.
Few-shot Neural Human Performance Rendering from Sparse RGBD Videos
Jul 14, 2021
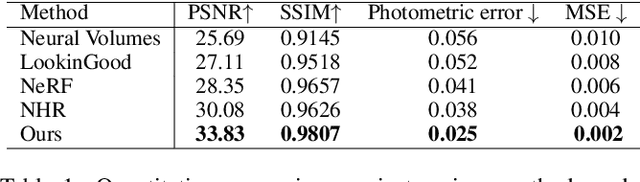

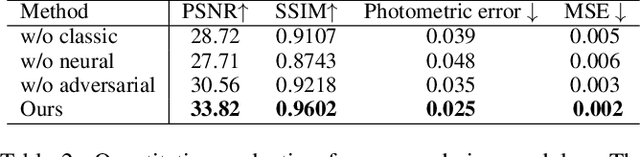
Recent neural rendering approaches for human activities achieve remarkable view synthesis results, but still rely on dense input views or dense training with all the capture frames, leading to deployment difficulty and inefficient training overload. However, existing advances will be ill-posed if the input is both spatially and temporally sparse. To fill this gap, in this paper we propose a few-shot neural human rendering approach (FNHR) from only sparse RGBD inputs, which exploits the temporal and spatial redundancy to generate photo-realistic free-view output of human activities. Our FNHR is trained only on the key-frames which expand the motion manifold in the input sequences. We introduce a two-branch neural blending to combine the neural point render and classical graphics texturing pipeline, which integrates reliable observations over sparse key-frames. Furthermore, we adopt a patch-based adversarial training process to make use of the local redundancy and avoids over-fitting to the key-frames, which generates fine-detailed rendering results. Extensive experiments demonstrate the effectiveness of our approach to generate high-quality free view-point results for challenging human performances under the sparse setting.
Convolutional Neural Opacity Radiance Fields
Apr 05, 2021
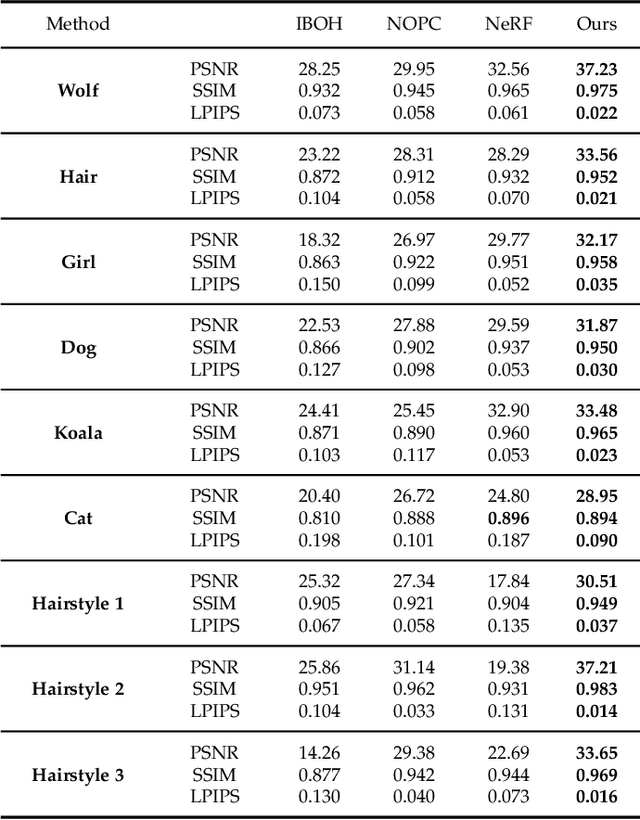
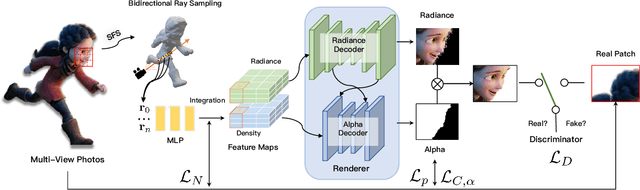
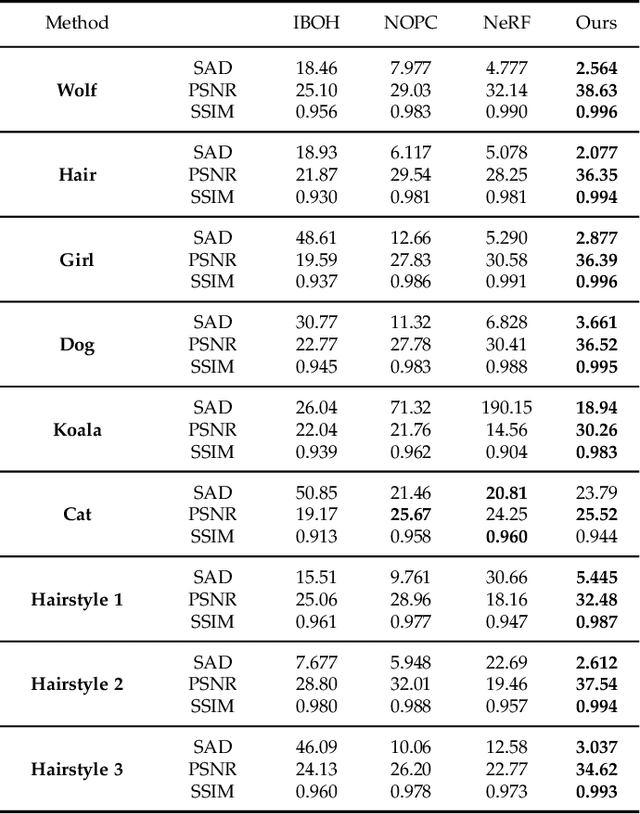
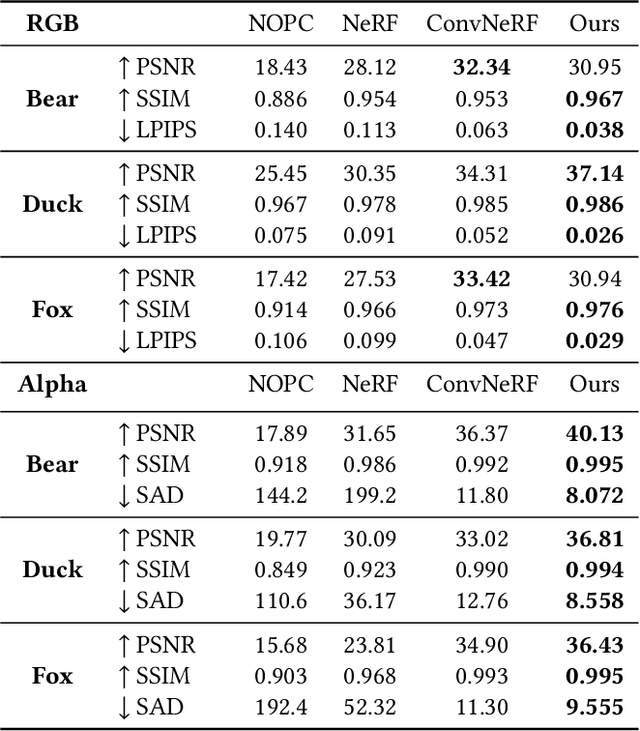
Photo-realistic modeling and rendering of fuzzy objects with complex opacity are critical for numerous immersive VR/AR applications, but it suffers from strong view-dependent brightness, color. In this paper, we propose a novel scheme to generate opacity radiance fields with a convolutional neural renderer for fuzzy objects, which is the first to combine both explicit opacity supervision and convolutional mechanism into the neural radiance field framework so as to enable high-quality appearance and global consistent alpha mattes generation in arbitrary novel views. More specifically, we propose an efficient sampling strategy along with both the camera rays and image plane, which enables efficient radiance field sampling and learning in a patch-wise manner, as well as a novel volumetric feature integration scheme that generates per-patch hybrid feature embeddings to reconstruct the view-consistent fine-detailed appearance and opacity output. We further adopt a patch-wise adversarial training scheme to preserve both high-frequency appearance and opacity details in a self-supervised framework. We also introduce an effective multi-view image capture system to capture high-quality color and alpha maps for challenging fuzzy objects. Extensive experiments on existing and our new challenging fuzzy object dataset demonstrate that our method achieves photo-realistic, globally consistent, and fined detailed appearance and opacity free-viewpoint rendering for various fuzzy objects.
GNeRF: GAN-based Neural Radiance Field without Posed Camera
Mar 30, 2021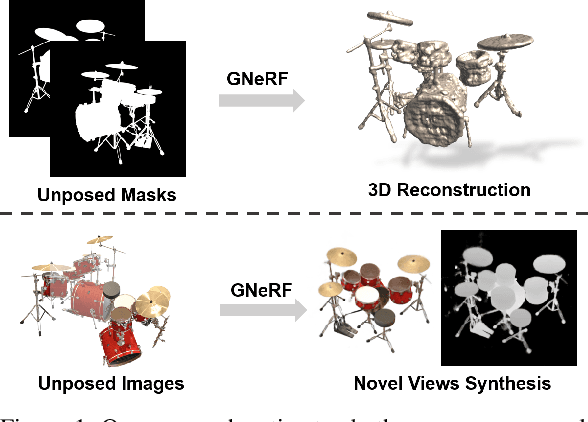
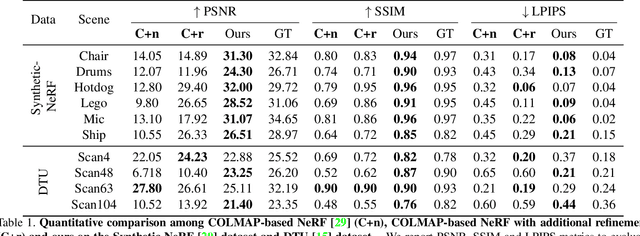
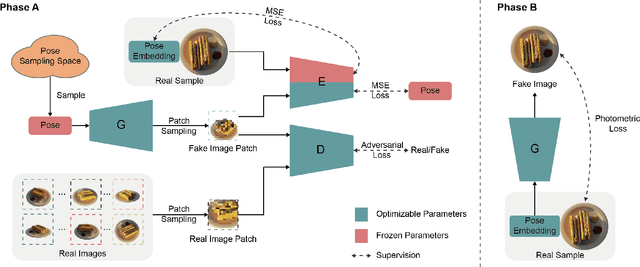

We introduce GNeRF, a framework to marry Generative Adversarial Networks (GAN) with Neural Radiance Field reconstruction for the complex scenarios with unknown and even randomly initialized camera poses. Recent NeRF-based advances have gained popularity for remarkable realistic novel view synthesis. However, most of them heavily rely on accurate camera poses estimation, while few recent methods can only optimize the unknown camera poses in roughly forward-facing scenes with relatively short camera trajectories and require rough camera poses initialization. Differently, our GNeRF only utilizes randomly initialized poses for complex outside-in scenarios. We propose a novel two-phases end-to-end framework. The first phase takes the use of GANs into the new realm for coarse camera poses and radiance fields jointly optimization, while the second phase refines them with additional photometric loss. We overcome local minima using a hybrid and iterative optimization scheme. Extensive experiments on a variety of synthetic and natural scenes demonstrate the effectiveness of GNeRF. More impressively, our approach outperforms the baselines favorably in those scenes with repeated patterns or even low textures that are regarded as extremely challenging before.