 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Diffusion to Rectified Flow: Rethinking Text-Based Segmentation
May 06, 2026Text-based image segmentation aims to delineate object boundaries within an image from text prompts, offering higher flexibility and broader application scope compared to traditional fixed-category segmentation tasks. Recent studies have shown that diffusion models (e.g., Stable Diffusion) can provide rich multimodal semantic features, leading to studies of using diffusion models as feature extractors for segmentation tasks. Such methods, however, inherit the generative natures of diffusion models that are harmful to discriminative segmentation tasks. In response, we propose RLFSeg, a novel framework that leverages Rectified Flow to learn direct mapping from the image to the segmentation mask within the latent space. The model is thus freed from the noise-denoise process and the need to optimize the time step of diffusion models, resulting in substantially better performance than previous diffusion-based methods, especially on zero-shot scenarios. By introducing label refinement and an Adaptive One-Step Sampling strategy, the model achieves higher accuracy even on a single inference step. The framework redirects a pretrained generative model to the discriminative segmentation task with zero modification to model structure, thus reveals promising application potential and significant research value.
Seen2Scene: Completing Realistic 3D Scenes with Visibility-Guided Flow
Mar 30, 2026We present Seen2Scene, the first flow matching-based approach that trains directly on incomplete, real-world 3D scans for scene completion and generation. Unlike prior methods that rely on complete and hence synthetic 3D data, our approach introduces visibility-guided flow matching, which explicitly masks out unknown regions in real scans, enabling effective learning from real-world, partial observations. We represent 3D scenes using truncated signed distance field (TSDF) volumes encoded in sparse grids and employ a sparse transformer to efficiently model complex scene structures while masking unknown regions. We employ 3D layout boxes as an input conditioning signal, and our approach is flexibly adapted to various other inputs such as text or partial scans. By learning directly from real-world, incomplete 3D scans, Seen2Scene enables realistic 3D scene completion for complex, cluttered real environments. Experiments demonstrate that our model produces coherent, complete, and realistic 3D scenes, outperforming baselines in completion accuracy and generation quality.
SceneFactor: Factored Latent 3D Diffusion for Controllable 3D Scene Generation
Dec 03, 2024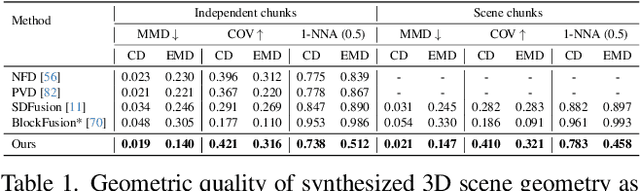
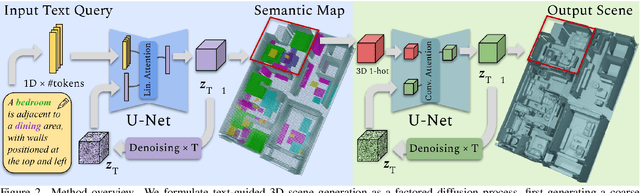
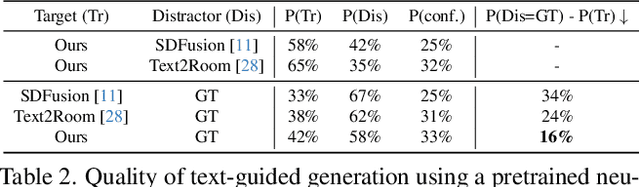
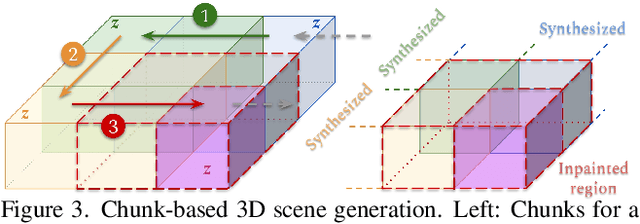
We present SceneFactor, a diffusion-based approach for large-scale 3D scene generation that enables controllable generation and effortless editing. SceneFactor enables text-guided 3D scene synthesis through our factored diffusion formulation, leveraging latent semantic and geometric manifolds for generation of arbitrary-sized 3D scenes. While text input enables easy, controllable generation, text guidance remains imprecise for intuitive, localized editing and manipulation of the generated 3D scenes. Our factored semantic diffusion generates a proxy semantic space composed of semantic 3D boxes that enables controllable editing of generated scenes by adding, removing, changing the size of the semantic 3D proxy boxes that guides high-fidelity, consistent 3D geometric editing. Extensive experiments demonstrate that our approach enables high-fidelity 3D scene synthesis with effective controllable editing through our factored diffusion approach.
LT3SD: Latent Trees for 3D Scene Diffusion
Sep 12, 2024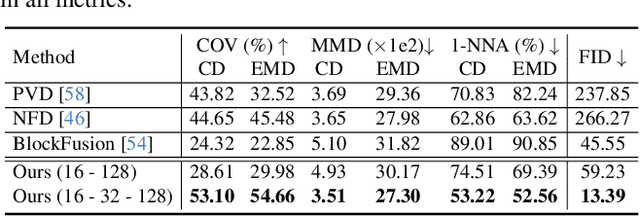


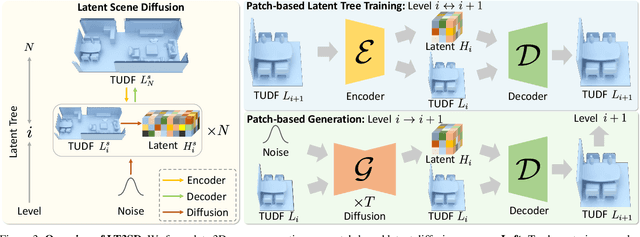
We present LT3SD, a novel latent diffusion model for large-scale 3D scene generation. Recent advances in diffusion models have shown impressive results in 3D object generation, but are limited in spatial extent and quality when extended to 3D scenes. To generate complex and diverse 3D scene structures, we introduce a latent tree representation to effectively encode both lower-frequency geometry and higher-frequency detail in a coarse-to-fine hierarchy. We can then learn a generative diffusion process in this latent 3D scene space, modeling the latent components of a scene at each resolution level. To synthesize large-scale scenes with varying sizes, we train our diffusion model on scene patches and synthesize arbitrary-sized output 3D scenes through shared diffusion generation across multiple scene patches. Through extensive experiments, we demonstrate the efficacy and benefits of LT3SD for large-scale, high-quality unconditional 3D scene generation and for probabilistic completion for partial scene observations.
GNeRF: GAN-based Neural Radiance Field without Posed Camera
Mar 30, 2021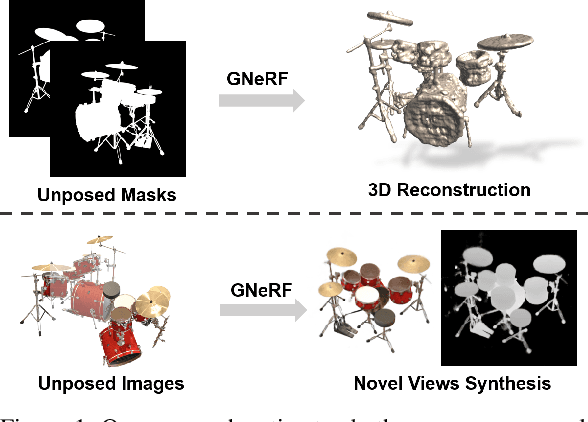
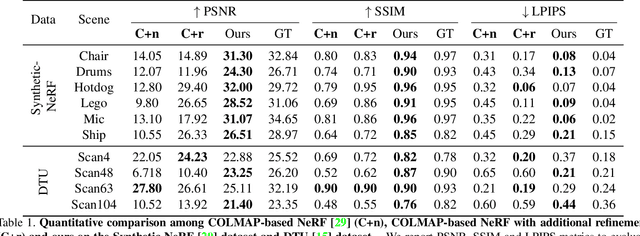
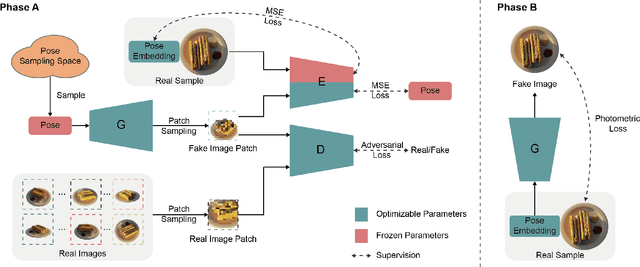

We introduce GNeRF, a framework to marry Generative Adversarial Networks (GAN) with Neural Radiance Field reconstruction for the complex scenarios with unknown and even randomly initialized camera poses. Recent NeRF-based advances have gained popularity for remarkable realistic novel view synthesis. However, most of them heavily rely on accurate camera poses estimation, while few recent methods can only optimize the unknown camera poses in roughly forward-facing scenes with relatively short camera trajectories and require rough camera poses initialization. Differently, our GNeRF only utilizes randomly initialized poses for complex outside-in scenarios. We propose a novel two-phases end-to-end framework. The first phase takes the use of GANs into the new realm for coarse camera poses and radiance fields jointly optimization, while the second phase refines them with additional photometric loss. We overcome local minima using a hybrid and iterative optimization scheme. Extensive experiments on a variety of synthetic and natural scenes demonstrate the effectiveness of GNeRF. More impressively, our approach outperforms the baselines favorably in those scenes with repeated patterns or even low textures that are regarded as extremely challenging before.
LGNN: A Context-aware Line Segment Detector
Aug 29, 2020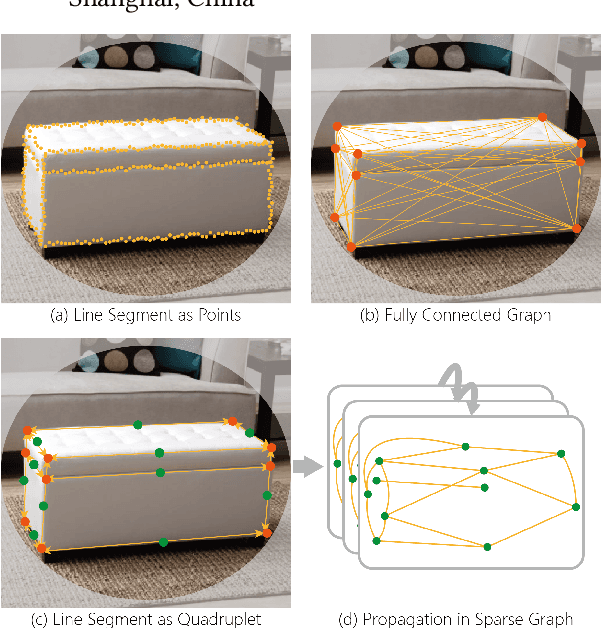



We present a novel real-time line segment detection scheme called Line Graph Neural Network (LGNN). Existing approaches require a computationally expensive verification or postprocessing step. Our LGNN employs a deep convolutional neural network (DCNN) for proposing line segment directly, with a graph neural network (GNN) module for reasoning their connectivities. Specifically, LGNN exploits a new quadruplet representation for each line segment where the GNN module takes the predicted candidates as vertexes and constructs a sparse graph to enforce structural context. Compared with the state-of-the-art, LGNN achieves near real-time performance without compromising accuracy. LGNN further enables time-sensitive 3D applications. When a 3D point cloud is accessible, we present a multi-modal line segment classification technique for extracting a 3D wireframe of the environment robustly and efficiently.