 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion 3-to-4: 3D Motion Reconstruction for 4D Synthesis
Jan 20, 2026We present Motion 3-to-4, a feed-forward framework for synthesising high-quality 4D dynamic objects from a single monocular video and an optional 3D reference mesh. While recent advances have significantly improved 2D, video, and 3D content generation, 4D synthesis remains difficult due to limited training data and the inherent ambiguity of recovering geometry and motion from a monocular viewpoint. Motion 3-to-4 addresses these challenges by decomposing 4D synthesis into static 3D shape generation and motion reconstruction. Using a canonical reference mesh, our model learns a compact motion latent representation and predicts per-frame vertex trajectories to recover complete, temporally coherent geometry. A scalable frame-wise transformer further enables robustness to varying sequence lengths. Evaluations on both standard benchmarks and a new dataset with accurate ground-truth geometry show that Motion 3-to-4 delivers superior fidelity and spatial consistency compared to prior work. Project page is available at https://motion3-to-4.github.io/.
ConeGS: Error-Guided Densification Using Pixel Cones for Improved Reconstruction with Fewer Primitives
Nov 10, 2025



3D Gaussian Splatting (3DGS) achieves state-of-the-art image quality and real-time performance in novel view synthesis but often suffers from a suboptimal spatial distribution of primitives. This issue stems from cloning-based densification, which propagates Gaussians along existing geometry, limiting exploration and requiring many primitives to adequately cover the scene. We present ConeGS, an image-space-informed densification framework that is independent of existing scene geometry state. ConeGS first creates a fast Instant Neural Graphics Primitives (iNGP) reconstruction as a geometric proxy to estimate per-pixel depth. During the subsequent 3DGS optimization, it identifies high-error pixels and inserts new Gaussians along the corresponding viewing cones at the predicted depth values, initializing their size according to the cone diameter. A pre-activation opacity penalty rapidly removes redundant Gaussians, while a primitive budgeting strategy controls the total number of primitives, either by a fixed budget or by adapting to scene complexity, ensuring high reconstruction quality. Experiments show that ConeGS consistently enhances reconstruction quality and rendering performance across Gaussian budgets, with especially strong gains under tight primitive constraints where efficient placement is crucial.
TTT3R: 3D Reconstruction as Test-Time Training
Sep 30, 2025Modern Recurrent Neural Networks have become a competitive architecture for 3D reconstruction due to their linear-time complexity. However, their performance degrades significantly when applied beyond the training context length, revealing limited length generalization. In this work, we revisit the 3D reconstruction foundation models from a Test-Time Training perspective, framing their designs as an online learning problem. Building on this perspective, we leverage the alignment confidence between the memory state and incoming observations to derive a closed-form learning rate for memory updates, to balance between retaining historical information and adapting to new observations. This training-free intervention, termed TTT3R, substantially improves length generalization, achieving a $2\times$ improvement in global pose estimation over baselines, while operating at 20 FPS with just 6 GB of GPU memory to process thousands of images. Code available in https://rover-xingyu.github.io/TTT3R
Neural Shell Texture Splatting: More Details and Fewer Primitives
Jul 27, 2025Gaussian splatting techniques have shown promising results in novel view synthesis, achieving high fidelity and efficiency. However, their high reconstruction quality comes at the cost of requiring a large number of primitives. We identify this issue as stemming from the entanglement of geometry and appearance in Gaussian Splatting. To address this, we introduce a neural shell texture, a global representation that encodes texture information around the surface. We use Gaussian primitives as both a geometric representation and texture field samplers, efficiently splatting texture features into image space. Our evaluation demonstrates that this disentanglement enables high parameter efficiency, fine texture detail reconstruction, and easy textured mesh extraction, all while using significantly fewer primitives.
LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models
Apr 18, 2025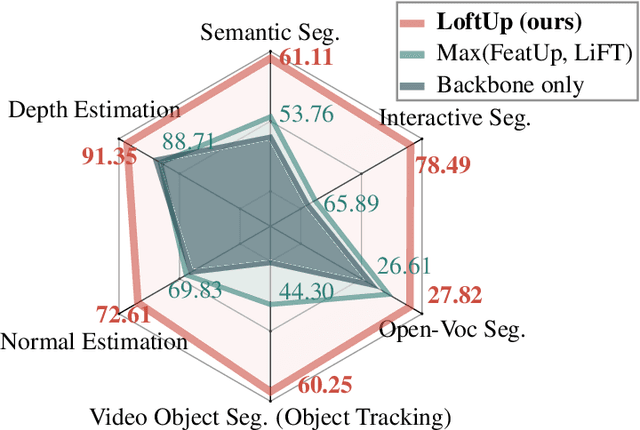
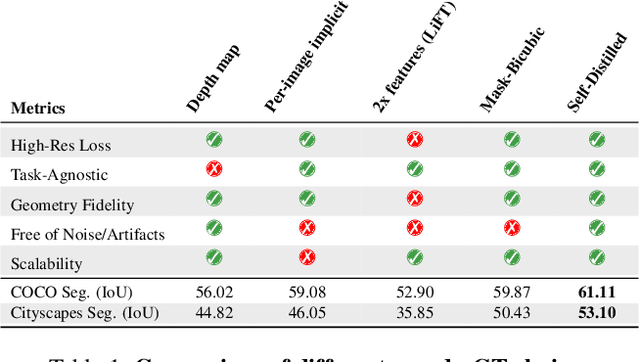
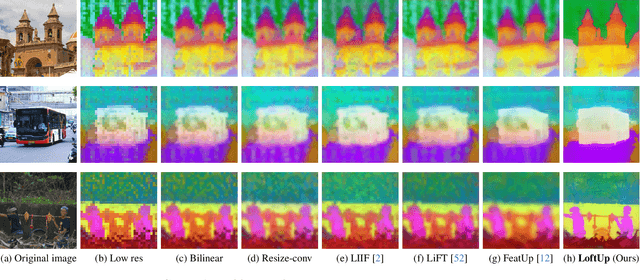
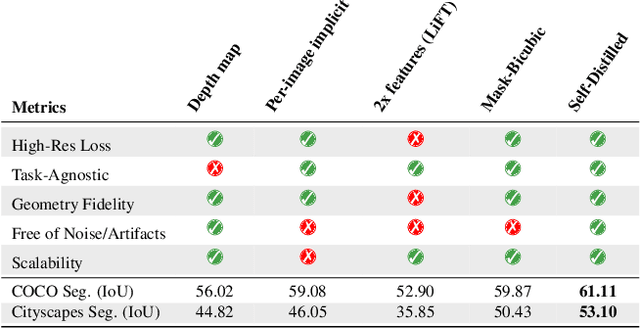
Vision foundation models (VFMs) such as DINOv2 and CLIP have achieved impressive results on various downstream tasks, but their limited feature resolution hampers performance in applications requiring pixel-level understanding. Feature upsampling offers a promising direction to address this challenge. In this work, we identify two critical factors for enhancing feature upsampling: the upsampler architecture and the training objective. For the upsampler architecture, we introduce a coordinate-based cross-attention transformer that integrates the high-resolution images with coordinates and low-resolution VFM features to generate sharp, high-quality features. For the training objective, we propose constructing high-resolution pseudo-groundtruth features by leveraging class-agnostic masks and self-distillation. Our approach effectively captures fine-grained details and adapts flexibly to various input and feature resolutions. Through experiments, we demonstrate that our approach significantly outperforms existing feature upsampling techniques across various downstream tasks. Our code is released at https://github.com/andrehuang/loftup.
Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
Mar 31, 2025



Recent advances in DUSt3R have enabled robust estimation of dense point clouds and camera parameters of static scenes, leveraging Transformer network architectures and direct supervision on large-scale 3D datasets. In contrast, the limited scale and diversity of available 4D datasets present a major bottleneck for training a highly generalizable 4D model. This constraint has driven conventional 4D methods to fine-tune 3D models on scalable dynamic video data with additional geometric priors such as optical flow and depths. In this work, we take an opposite path and introduce Easi3R, a simple yet efficient training-free method for 4D reconstruction. Our approach applies attention adaptation during inference, eliminating the need for from-scratch pre-training or network fine-tuning. We find that the attention layers in DUSt3R inherently encode rich information about camera and object motion. By carefully disentangling these attention maps, we achieve accurate dynamic region segmentation, camera pose estimation, and 4D dense point map reconstruction. Extensive experiments on real-world dynamic videos demonstrate that our lightweight attention adaptation significantly outperforms previous state-of-the-art methods that are trained or finetuned on extensive dynamic datasets. Our code is publicly available for research purpose at https://easi3r.github.io/
GenFusion: Closing the Loop between Reconstruction and Generation via Videos
Mar 27, 2025



Recently, 3D reconstruction and generation have demonstrated impressive novel view synthesis results, achieving high fidelity and efficiency. However, a notable conditioning gap can be observed between these two fields, e.g., scalable 3D scene reconstruction often requires densely captured views, whereas 3D generation typically relies on a single or no input view, which significantly limits their applications. We found that the source of this phenomenon lies in the misalignment between 3D constraints and generative priors. To address this problem, we propose a reconstruction-driven video diffusion model that learns to condition video frames on artifact-prone RGB-D renderings. Moreover, we propose a cyclical fusion pipeline that iteratively adds restoration frames from the generative model to the training set, enabling progressive expansion and addressing the viewpoint saturation limitations seen in previous reconstruction and generation pipelines. Our evaluation, including view synthesis from sparse view and masked input, validates the effectiveness of our approach.
Feat2GS: Probing Visual Foundation Models with Gaussian Splatting
Dec 12, 2024Given that visual foundation models (VFMs) are trained on extensive datasets but often limited to 2D images, a natural question arises: how well do they understand the 3D world? With the differences in architecture and training protocols (i.e., objectives, proxy tasks), a unified framework to fairly and comprehensively probe their 3D awareness is urgently needed. Existing works on 3D probing suggest single-view 2.5D estimation (e.g., depth and normal) or two-view sparse 2D correspondence (e.g., matching and tracking). Unfortunately, these tasks ignore texture awareness, and require 3D data as ground-truth, which limits the scale and diversity of their evaluation set. To address these issues, we introduce Feat2GS, which readout 3D Gaussians attributes from VFM features extracted from unposed images. This allows us to probe 3D awareness for geometry and texture via novel view synthesis, without requiring 3D data. Additionally, the disentanglement of 3DGS parameters - geometry ($\boldsymbol{x}, \alpha, \Sigma$) and texture ($\boldsymbol{c}$) - enables separate analysis of texture and geometry awareness. Under Feat2GS, we conduct extensive experiments to probe the 3D awareness of several VFMs, and investigate the ingredients that lead to a 3D aware VFM. Building on these findings, we develop several variants that achieve state-of-the-art across diverse datasets. This makes Feat2GS useful for probing VFMs, and as a simple-yet-effective baseline for novel-view synthesis. Code and data will be made available at https://fanegg.github.io/Feat2GS/.
Ref-GS: Directional Factorization for 2D Gaussian Splatting
Dec 01, 2024



In this paper, we introduce Ref-GS, a novel approach for directional light factorization in 2D Gaussian splatting, which enables photorealistic view-dependent appearance rendering and precise geometry recovery. Ref-GS builds upon the deferred rendering of Gaussian splatting and applies directional encoding to the deferred-rendered surface, effectively reducing the ambiguity between orientation and viewing angle. Next, we introduce a spherical Mip-grid to capture varying levels of surface roughness, enabling roughness-aware Gaussian shading. Additionally, we propose a simple yet efficient geometry-lighting factorization that connects geometry and lighting via the vector outer product, significantly reducing renderer overhead when integrating volumetric attributes. Our method achieves superior photorealistic rendering for a range of open-world scenes while also accurately recovering geometry.
Volumetric Surfaces: Representing Fuzzy Geometries with Multiple Meshes
Sep 04, 2024



High-quality real-time view synthesis methods are based on volume rendering, splatting, or surface rendering. While surface-based methods generally are the fastest, they cannot faithfully model fuzzy geometry like hair. In turn, alpha-blending techniques excel at representing fuzzy materials but require an unbounded number of samples per ray (P1). Further overheads are induced by empty space skipping in volume rendering (P2) and sorting input primitives in splatting (P3). These problems are exacerbated on low-performance graphics hardware, e.g. on mobile devices. We present a novel representation for real-time view synthesis where the (P1) number of sampling locations is small and bounded, (P2) sampling locations are efficiently found via rasterization, and (P3) rendering is sorting-free. We achieve this by representing objects as semi-transparent multi-layer meshes, rendered in fixed layer order from outermost to innermost. We model mesh layers as SDF shells with optimal spacing learned during training. After baking, we fit UV textures to the corresponding meshes. We show that our method can represent challenging fuzzy objects while achieving higher frame rates than volume-based and splatting-based methods on low-end and mobile devices.