 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientists' First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
Jun 12, 2025Scientific discoveries increasingly rely on complex multimodal reasoning based on information-intensive scientific data and domain-specific expertise. Empowered by expert-level scientific benchmarks, scientific Multimodal Large Language Models (MLLMs) hold the potential to significantly enhance this discovery process in realistic workflows. However, current scientific benchmarks mostly focus on evaluating the knowledge understanding capabilities of MLLMs, leading to an inadequate assessment of their perception and reasoning abilities. To address this gap, we present the Scientists' First Exam (SFE) benchmark, designed to evaluate the scientific cognitive capacities of MLLMs through three interconnected levels: scientific signal perception, scientific attribute understanding, scientific comparative reasoning. Specifically, SFE comprises 830 expert-verified VQA pairs across three question types, spanning 66 multimodal tasks across five high-value disciplines. Extensive experiments reveal that current state-of-the-art GPT-o3 and InternVL-3 achieve only 34.08% and 26.52% on SFE, highlighting significant room for MLLMs to improve in scientific realms. We hope the insights obtained in SFE will facilitate further developments in AI-enhanced scientific discoveries.
Benchmarking Feature Upsampling Methods for Vision Foundation Models using Interactive Segmentation
May 04, 2025Vision Foundation Models (VFMs) are large-scale, pre-trained models that serve as general-purpose backbones for various computer vision tasks. As VFMs' popularity grows, there is an increasing interest in understanding their effectiveness for dense prediction tasks. However, VFMs typically produce low-resolution features, limiting their direct applicability in this context. One way to tackle this limitation is by employing a task-agnostic feature upsampling module that refines VFM features resolution. To assess the effectiveness of this approach, we investigate Interactive Segmentation (IS) as a novel benchmark for evaluating feature upsampling methods on VFMs. Due to its inherent multimodal input, consisting of an image and a set of user-defined clicks, as well as its dense mask output, IS creates a challenging environment that demands comprehensive visual scene understanding. Our benchmarking experiments show that selecting appropriate upsampling strategies significantly improves VFM features quality. The code is released at https://github.com/havrylovv/iSegProbe
LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models
Apr 18, 2025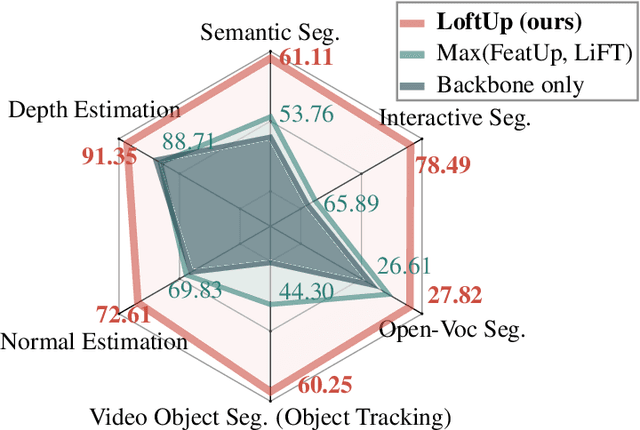
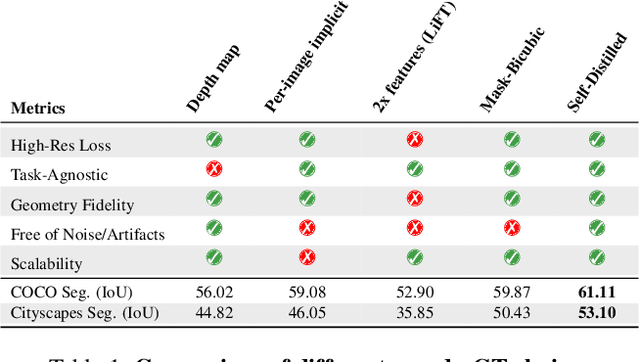
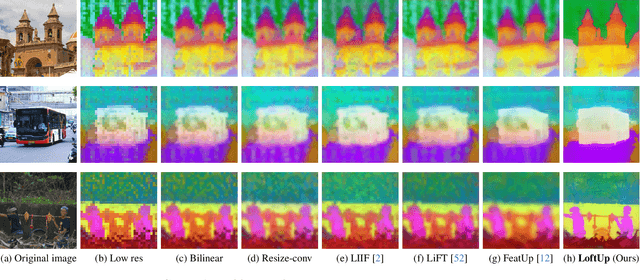
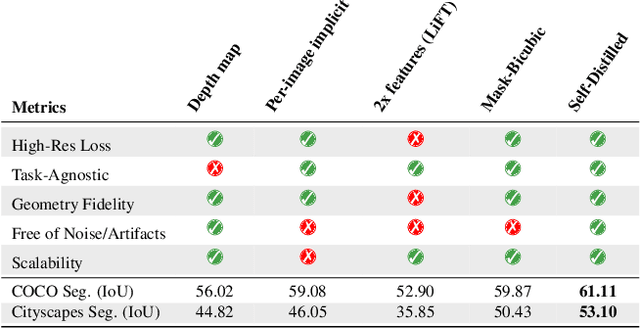
Vision foundation models (VFMs) such as DINOv2 and CLIP have achieved impressive results on various downstream tasks, but their limited feature resolution hampers performance in applications requiring pixel-level understanding. Feature upsampling offers a promising direction to address this challenge. In this work, we identify two critical factors for enhancing feature upsampling: the upsampler architecture and the training objective. For the upsampler architecture, we introduce a coordinate-based cross-attention transformer that integrates the high-resolution images with coordinates and low-resolution VFM features to generate sharp, high-quality features. For the training objective, we propose constructing high-resolution pseudo-groundtruth features by leveraging class-agnostic masks and self-distillation. Our approach effectively captures fine-grained details and adapts flexibly to various input and feature resolutions. Through experiments, we demonstrate that our approach significantly outperforms existing feature upsampling techniques across various downstream tasks. Our code is released at https://github.com/andrehuang/loftup.
Renovating Names in Open-Vocabulary Segmentation Benchmarks
Mar 14, 2024
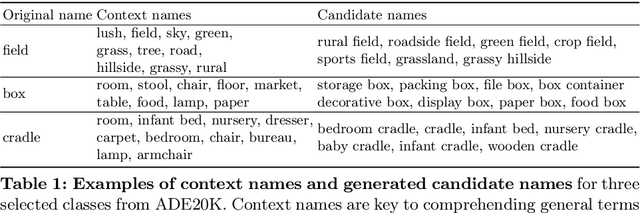
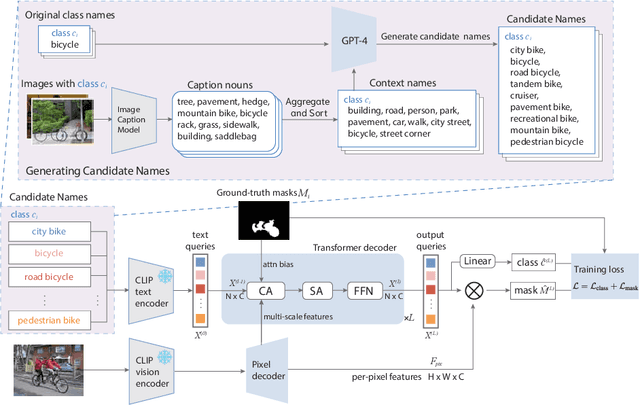
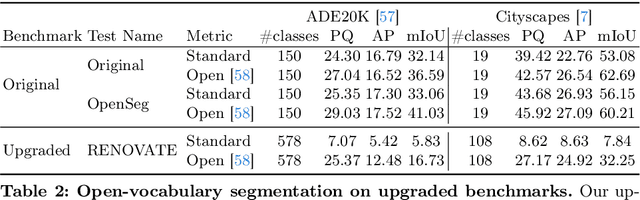
Names are essential to both human cognition and vision-language models. Open-vocabulary models utilize class names as text prompts to generalize to categories unseen during training. However, name qualities are often overlooked and lack sufficient precision in existing datasets. In this paper, we address this underexplored problem by presenting a framework for "renovating" names in open-vocabulary segmentation benchmarks (RENOVATE). Through human study, we demonstrate that the names generated by our model are more precise descriptions of the visual segments and hence enhance the quality of existing datasets by means of simple renaming. We further demonstrate that using our renovated names enables training of stronger open-vocabulary segmentation models. Using open-vocabulary segmentation for name quality evaluation, we show that our renovated names lead to up to 16% relative improvement from the original names on various benchmarks across various state-of-the-art models. We provide our code and relabelings for several popular segmentation datasets (ADE20K, Cityscapes, PASCAL Context) to the research community.
SalienTime: User-driven Selection of Salient Time Steps for Large-Scale Geospatial Data Visualization
Mar 06, 2024



The voluminous nature of geospatial temporal data from physical monitors and simulation models poses challenges to efficient data access, often resulting in cumbersome temporal selection experiences in web-based data portals. Thus, selecting a subset of time steps for prioritized visualization and pre-loading is highly desirable. Addressing this issue, this paper establishes a multifaceted definition of salient time steps via extensive need-finding studies with domain experts to understand their workflows. Building on this, we propose a novel approach that leverages autoencoders and dynamic programming to facilitate user-driven temporal selections. Structural features, statistical variations, and distance penalties are incorporated to make more flexible selections. User-specified priorities, spatial regions, and aggregations are used to combine different perspectives. We design and implement a web-based interface to enable efficient and context-aware selection of time steps and evaluate its efficacy and usability through case studies, quantitative evaluations, and expert interviews.
GOOD: Exploring Geometric Cues for Detecting Objects in an Open World
Dec 24, 2022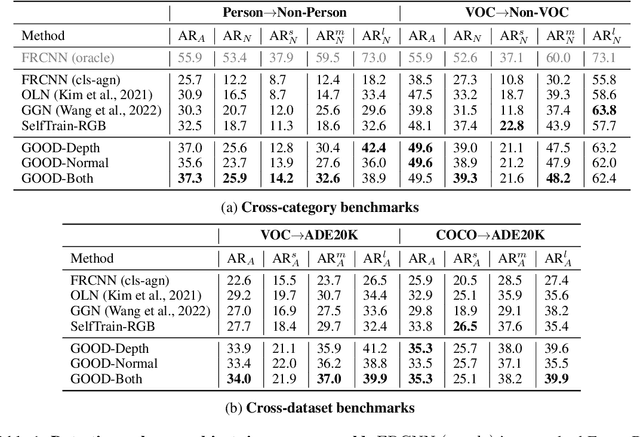

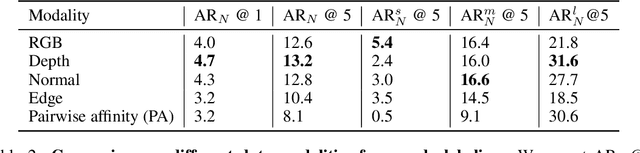
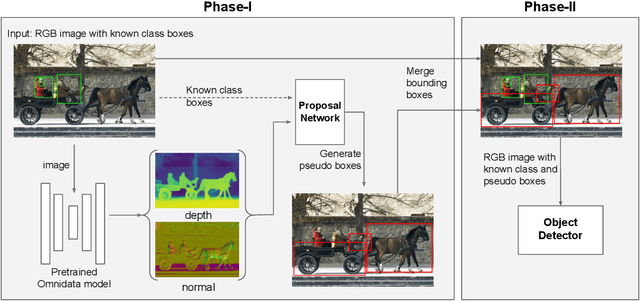
We address the task of open-world class-agnostic object detection, i.e., detecting every object in an image by learning from a limited number of base object classes. State-of-the-art RGB-based models suffer from overfitting the training classes and often fail at detecting novel-looking objects. This is because RGB-based models primarily rely on appearance similarity to detect novel objects and are also prone to overfitting short-cut cues such as textures and discriminative parts. To address these shortcomings of RGB-based object detectors, we propose incorporating geometric cues such as depth and normals, predicted by general-purpose monocular estimators. Specifically, we use the geometric cues to train an object proposal network for pseudo-labeling unannotated novel objects in the training set. Our resulting Geometry-guided Open-world Object Detector (GOOD) significantly improves detection recall for novel object categories and already performs well with only a few training classes. Using a single "person" class for training on the COCO dataset, GOOD surpasses SOTA methods by 5.0% AR@100, a relative improvement of 24%.
Decomposing Representations for Deterministic Uncertainty Estimation
Dec 01, 2021
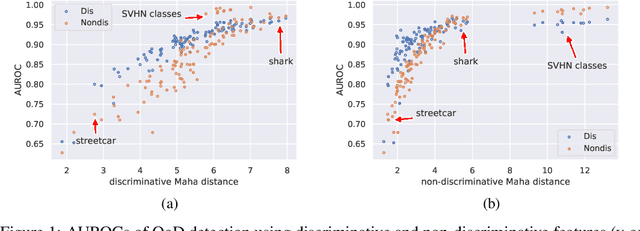
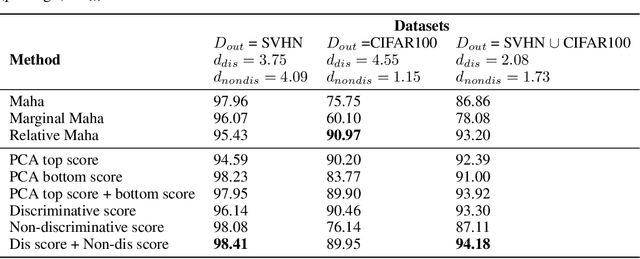
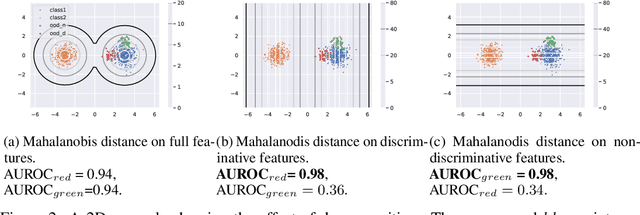
Uncertainty estimation is a key component in any deployed machine learning system. One way to evaluate uncertainty estimation is using "out-of-distribution" (OoD) detection, that is, distinguishing between the training data distribution and an unseen different data distribution using uncertainty. In this work, we show that current feature density based uncertainty estimators cannot perform well consistently across different OoD detection settings. To solve this, we propose to decompose the learned representations and integrate the uncertainties estimated on them separately. Through experiments, we demonstrate that we can greatly improve the performance and the interpretability of the uncertainty estimation.
Can convolutional ResNets approximately preserve input distances? A frequency analysis perspective
Jun 17, 2021
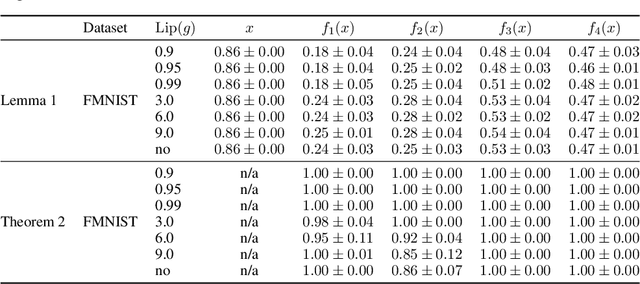

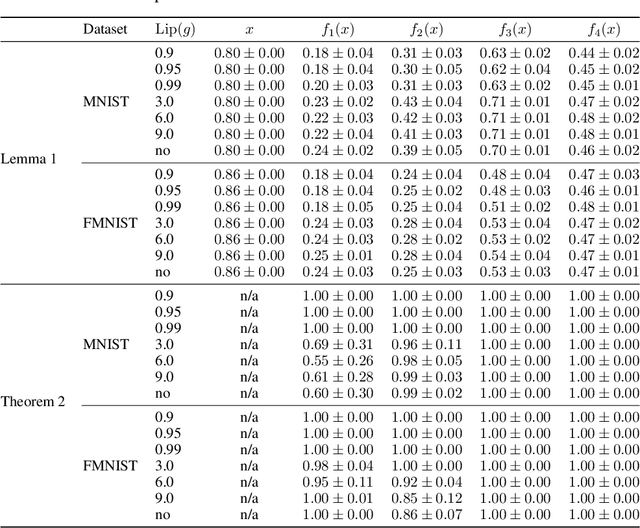
ResNets constrained to be bi-Lipschitz, that is, approximately distance preserving, have been a crucial component of recently proposed techniques for deterministic uncertainty quantification in neural models. We show that theoretical justifications for recent regularisation schemes trying to enforce such a constraint suffer from a crucial flaw -- the theoretical link between the regularisation scheme used and bi-Lipschitzness is only valid under conditions which do not hold in practice, rendering existing theory of limited use, despite the strong empirical performance of these models. We provide a theoretical explanation for the effectiveness of these regularisation schemes using a frequency analysis perspective, showing that under mild conditions these schemes will enforce a lower Lipschitz bound on the low-frequency projection of images. We then provide empirical evidence supporting our theoretical claims, and perform further experiments which demonstrate that our broader conclusions appear to hold when some of the mathematical assumptions of our proof are relaxed, corresponding to the setup used in prior work. In addition, we present a simple constructive algorithm to search for counter examples to the distance preservation condition, and discuss possible implications of our theory for future model design.
Feature Space Singularity for Out-of-Distribution Detection
Dec 16, 2020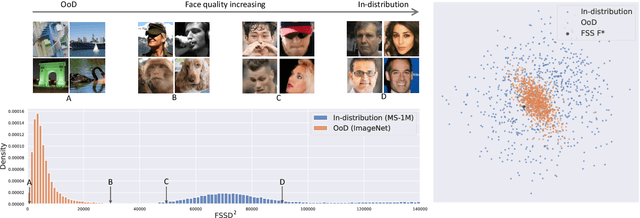
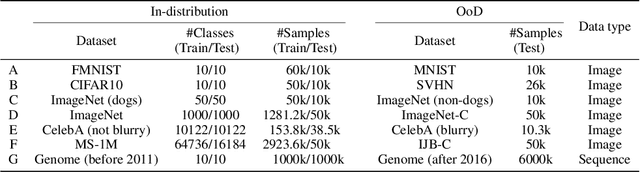
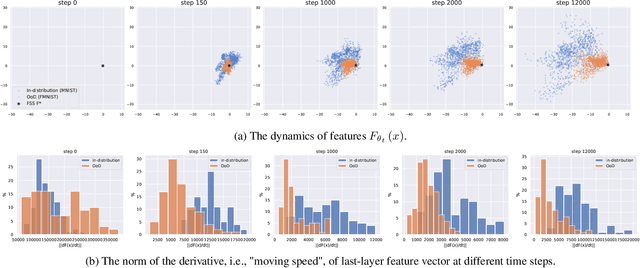
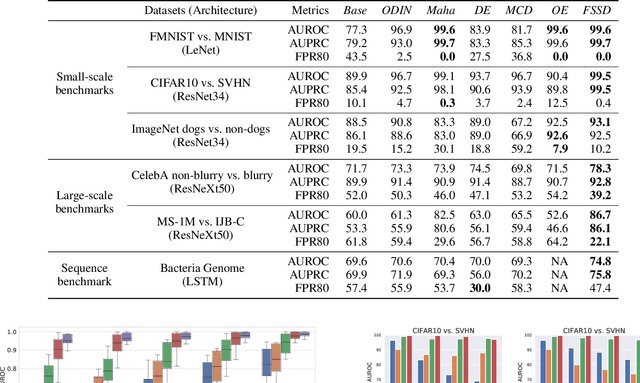
Out-of-Distribution (OoD) detection is important for building safe artificial intelligence systems. However, current OoD detection methods still cannot meet the performance requirements for practical deployment. In this paper, we propose a simple yet effective algorithm based on a novel observation: in a trained neural network, OoD samples with bounded norms well concentrate in the feature space. We call the center of OoD features the Feature Space Singularity (FSS), and denote the distance of a sample feature to FSS as FSSD. Then, OoD samples can be identified by taking a threshold on the FSSD. Our analysis of the phenomenon reveals why our algorithm works. We demonstrate that our algorithm achieves state-of-the-art performance on various OoD detection benchmarks. Besides, FSSD also enjoys robustness to slight corruption in test data and can be further enhanced by ensembling. These make FSSD a promising algorithm to be employed in real world. We release our code at \url{https://github.com/megvii-research/FSSD_OoD_Detection}.
Nostalgic Adam: Weighing more of the past gradients when designing the adaptive learning rate
May 19, 2018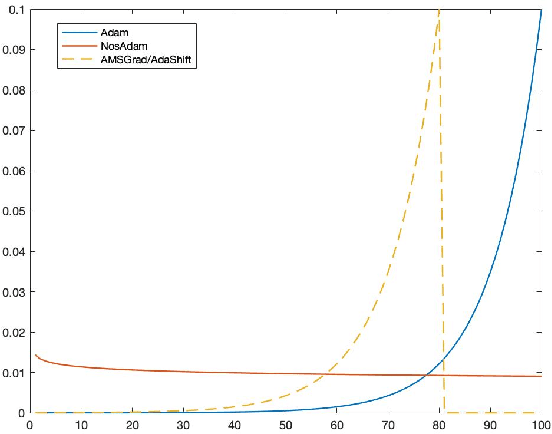
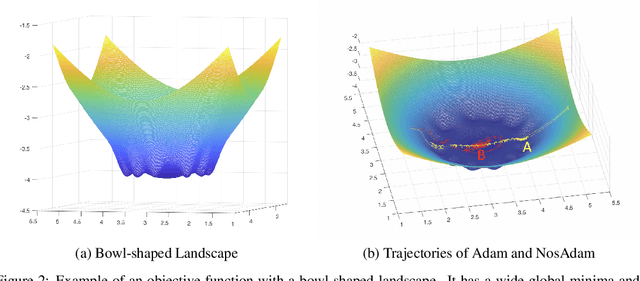
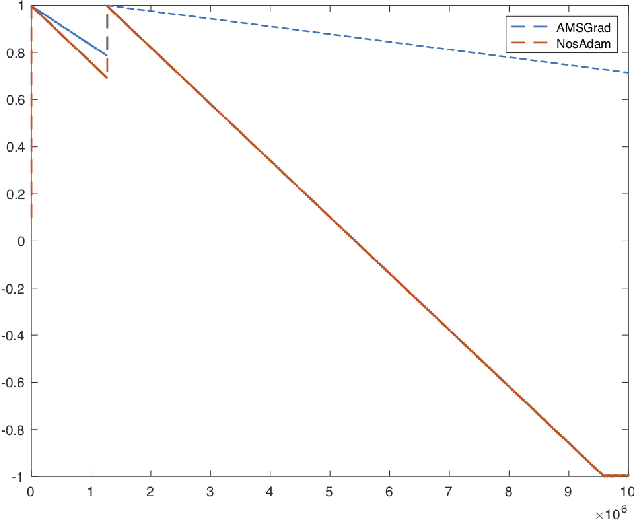
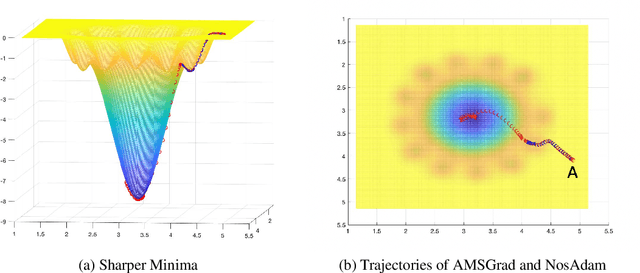
First-order optimization methods have been playing a prominent role in deep learning. Algorithms such as RMSProp and Adam are rather popular in training deep neural networks on large datasets. Recently, Reddi et al. discovered a flaw in the proof of convergence of Adam, and the authors proposed an alternative algorithm, AMSGrad, which has guaranteed convergence under certain conditions. In this paper, we propose a new algorithm, called Nostalgic Adam (NosAdam), which places bigger weights on the past gradients than the recent gradients when designing the adaptive learning rate. This is a new observation made through mathematical analysis of the algorithm. We also show that the estimate of the second moment of the gradient in NosAdam vanishes slower than Adam, which may account for faster convergence of NosAdam. We analyze the convergence of NosAdam and discover a convergence rate that achieves the best known convergence rate $O(1/\sqrt{T})$ for general convex online learning problems. Empirically, we show that NosAdam outperforms AMSGrad and Adam in some common machine learning problems.