 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Learning on Graphs using Graph Neural Networks
Feb 19, 2026Graph neural networks (GNNs) work remarkably well in semi-supervised node regression, yet a rigorous theory explaining when and why they succeed remains lacking. To address this gap, we study an aggregate-and-readout model that encompasses several common message passing architectures: node features are first propagated over the graph then mapped to responses via a nonlinear function. For least-squares estimation over GNNs with linear graph convolutions and a deep ReLU readout, we prove a sharp non-asymptotic risk bound that separates approximation, stochastic, and optimization errors. The bound makes explicit how performance scales with the fraction of labeled nodes and graph-induced dependence. Approximation guarantees are further derived for graph-smoothing followed by smooth nonlinear readouts, yielding convergence rates that recover classical nonparametric behavior under full supervision while characterizing performance when labels are scarce. Numerical experiments validate our theory, providing a systematic framework for understanding GNN performance and limitations.
SigTime: Learning and Visually Explaining Time Series Signatures
Dec 12, 2025Understanding and distinguishing temporal patterns in time series data is essential for scientific discovery and decision-making. For example, in biomedical research, uncovering meaningful patterns in physiological signals can improve diagnosis, risk assessment, and patient outcomes. However, existing methods for time series pattern discovery face major challenges, including high computational complexity, limited interpretability, and difficulty in capturing meaningful temporal structures. To address these gaps, we introduce a novel learning framework that jointly trains two Transformer models using complementary time series representations: shapelet-based representations to capture localized temporal structures and traditional feature engineering to encode statistical properties. The learned shapelets serve as interpretable signatures that differentiate time series across classification labels. Additionally, we develop a visual analytics system -- SigTIme -- with coordinated views to facilitate exploration of time series signatures from multiple perspectives, aiding in useful insights generation. We quantitatively evaluate our learning framework on eight publicly available datasets and one proprietary clinical dataset. Additionally, we demonstrate the effectiveness of our system through two usage scenarios along with the domain experts: one involving public ECG data and the other focused on preterm labor analysis.
On the expressivity of deep Heaviside networks
Apr 30, 2025



We show that deep Heaviside networks (DHNs) have limited expressiveness but that this can be overcome by including either skip connections or neurons with linear activation. We provide lower and upper bounds for the Vapnik-Chervonenkis (VC) dimensions and approximation rates of these network classes. As an application, we derive statistical convergence rates for DHN fits in the nonparametric regression model.
InterChat: Enhancing Generative Visual Analytics using Multimodal Interactions
Mar 06, 2025



The rise of Large Language Models (LLMs) and generative visual analytics systems has transformed data-driven insights, yet significant challenges persist in accurately interpreting users' analytical and interaction intents. While language inputs offer flexibility, they often lack precision, making the expression of complex intents inefficient, error-prone, and time-intensive. To address these limitations, we investigate the design space of multimodal interactions for generative visual analytics through a literature review and pilot brainstorming sessions. Building on these insights, we introduce a highly extensible workflow that integrates multiple LLM agents for intent inference and visualization generation. We develop InterChat, a generative visual analytics system that combines direct manipulation of visual elements with natural language inputs. This integration enables precise intent communication and supports progressive, visually driven exploratory data analyses. By employing effective prompt engineering, and contextual interaction linking, alongside intuitive visualization and interaction designs, InterChat bridges the gap between user interactions and LLM-driven visualizations, enhancing both interpretability and usability. Extensive evaluations, including two usage scenarios, a user study, and expert feedback, demonstrate the effectiveness of InterChat. Results show significant improvements in the accuracy and efficiency of handling complex visual analytics tasks, highlighting the potential of multimodal interactions to redefine user engagement and analytical depth in generative visual analytics.
Understanding the Effect of GCN Convolutions in Regression Tasks
Oct 26, 2024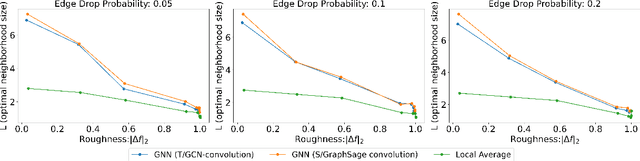
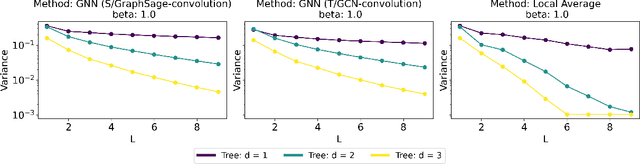
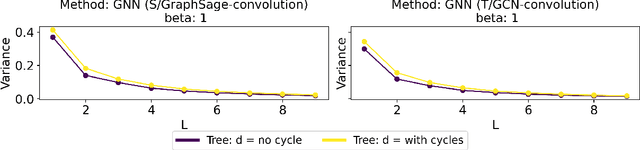
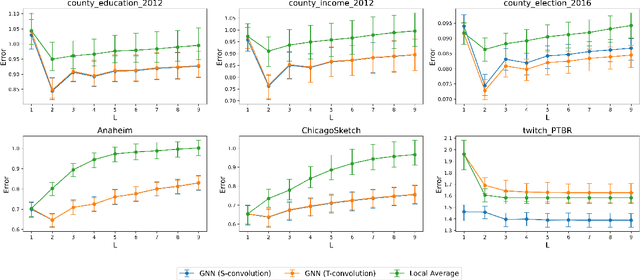
Graph Convolutional Networks (GCNs) have become a pivotal method in machine learning for modeling functions over graphs. Despite their widespread success across various applications, their statistical properties (e.g. consistency, convergence rates) remain ill-characterized. To begin addressing this knowledge gap, in this paper, we provide a formal analysis of the impact of convolution operators on regression tasks over homophilic networks. Focusing on estimators based solely on neighborhood aggregation, we examine how two common convolutions - the original GCN and GraphSage convolutions - affect the learning error as a function of the neighborhood topology and the number of convolutional layers. We explicitly characterize the bias-variance trade-off incurred by GCNs as a function of the neighborhood size and identify specific graph topologies where convolution operators are less effective. Our theoretical findings are corroborated by synthetic experiments, and provide a start to a deeper quantitative understanding of convolutional effects in GCNs for offering rigorous guidelines for practitioners.
SalienTime: User-driven Selection of Salient Time Steps for Large-Scale Geospatial Data Visualization
Mar 06, 2024



The voluminous nature of geospatial temporal data from physical monitors and simulation models poses challenges to efficient data access, often resulting in cumbersome temporal selection experiences in web-based data portals. Thus, selecting a subset of time steps for prioritized visualization and pre-loading is highly desirable. Addressing this issue, this paper establishes a multifaceted definition of salient time steps via extensive need-finding studies with domain experts to understand their workflows. Building on this, we propose a novel approach that leverages autoencoders and dynamic programming to facilitate user-driven temporal selections. Structural features, statistical variations, and distance penalties are incorporated to make more flexible selections. User-specified priorities, spatial regions, and aggregations are used to combine different perspectives. We design and implement a web-based interface to enable efficient and context-aware selection of time steps and evaluate its efficacy and usability through case studies, quantitative evaluations, and expert interviews.