 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTPred: Benchmarking MLLMs for Interpretable Geo-localization and Time-of-capture Prediction
Jan 19, 2026Geo-localization aims to infer the geographic location where an image was captured using observable visual evidence. Traditional methods achieve impressive results through large-scale training on massive image corpora. With the emergence of multi-modal large language models (MLLMs), recent studies have explored their applications in geo-localization, benefiting from improved accuracy and interpretability. However, existing benchmarks largely ignore the temporal information inherent in images, which can further constrain the location. To bridge this gap, we introduce GTPred, a novel benchmark for geo-temporal prediction. GTPred comprises 370 globally distributed images spanning over 120 years. We evaluate MLLM predictions by jointly considering year and hierarchical location sequence matching, and further assess intermediate reasoning chains using meticulously annotated ground-truth reasoning processes. Experiments on 8 proprietary and 7 open-source MLLMs show that, despite strong visual perception, current models remain limited in world knowledge and geo-temporal reasoning. Results also demonstrate that incorporating temporal information significantly enhances location inference performance.
VizDefender: Unmasking Visualization Tampering through Proactive Localization and Intent Inference
Dec 21, 2025
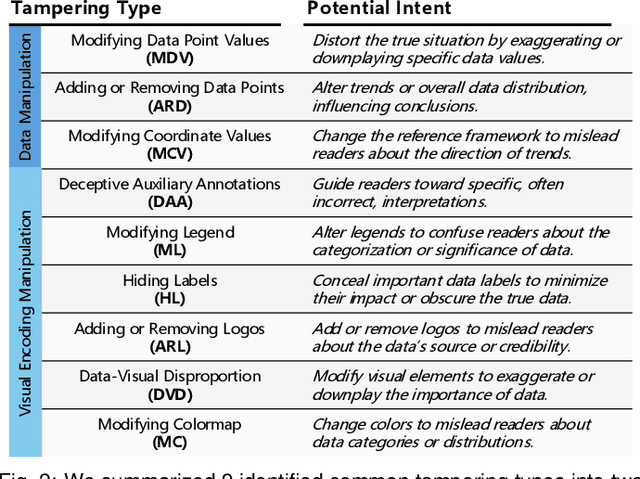
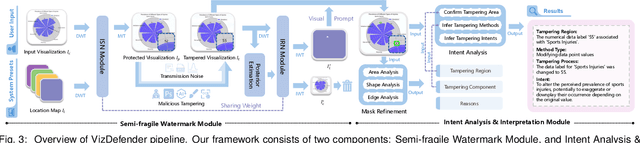
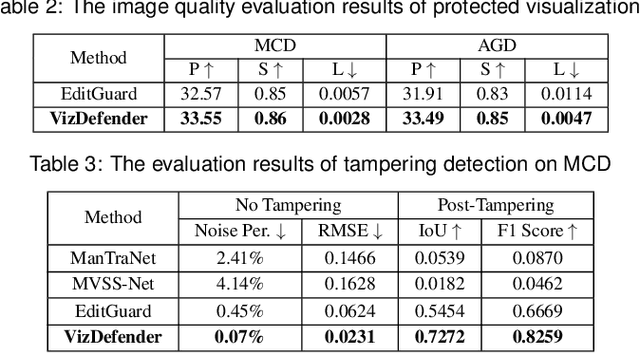
The integrity of data visualizations is increasingly threatened by image editing techniques that enable subtle yet deceptive tampering. Through a formative study, we define this challenge and categorize tampering techniques into two primary types: data manipulation and visual encoding manipulation. To address this, we present VizDefender, a framework for tampering detection and analysis. The framework integrates two core components: 1) a semi-fragile watermark module that protects the visualization by embedding a location map to images, which allows for the precise localization of tampered regions while preserving visual quality, and 2) an intent analysis module that leverages Multimodal Large Language Models (MLLMs) to interpret manipulation, inferring the attacker's intent and misleading effects. Extensive evaluations and user studies demonstrate the effectiveness of our methods.
Audio-VLA: Adding Contact Audio Perception to Vision-Language-Action Model for Robotic Manipulation
Nov 13, 2025The Vision-Language-Action models (VLA) have achieved significant advances in robotic manipulation recently. However, vision-only VLA models create fundamental limitations, particularly in perceiving interactive and manipulation dynamic processes. This paper proposes Audio-VLA, a multimodal manipulation policy that leverages contact audio to perceive contact events and dynamic process feedback. Audio-VLA overcomes the vision-only constraints of VLA models. Additionally, this paper introduces the Task Completion Rate (TCR) metric to systematically evaluate dynamic operational processes. Audio-VLA employs pre-trained DINOv2 and SigLIP as visual encoders, AudioCLIP as the audio encoder, and Llama2 as the large language model backbone. We apply LoRA fine-tuning to these pre-trained modules to achieve robust cross-modal understanding of both visual and acoustic inputs. A multimodal projection layer aligns features from different modalities into the same feature space. Moreover RLBench and LIBERO simulation environments are enhanced by adding collision-based audio generation to provide realistic sound feedback during object interactions. Since current robotic manipulation evaluations focus on final outcomes rather than providing systematic assessment of dynamic operational processes, the proposed TCR metric measures how well robots perceive dynamic processes during manipulation, creating a more comprehensive evaluation metric. Extensive experiments on LIBERO, RLBench, and two real-world tasks demonstrate Audio-VLA's superior performance over vision-only comparative methods, while the TCR metric effectively quantifies dynamic process perception capabilities.
MPJudge: Towards Perceptual Assessment of Music-Induced Paintings
Nov 10, 2025Music induced painting is a unique artistic practice, where visual artworks are created under the influence of music. Evaluating whether a painting faithfully reflects the music that inspired it poses a challenging perceptual assessment task. Existing methods primarily rely on emotion recognition models to assess the similarity between music and painting, but such models introduce considerable noise and overlook broader perceptual cues beyond emotion. To address these limitations, we propose a novel framework for music induced painting assessment that directly models perceptual coherence between music and visual art. We introduce MPD, the first large scale dataset of music painting pairs annotated by domain experts based on perceptual coherence. To better handle ambiguous cases, we further collect pairwise preference annotations. Building on this dataset, we present MPJudge, a model that integrates music features into a visual encoder via a modulation based fusion mechanism. To effectively learn from ambiguous cases, we adopt Direct Preference Optimization for training. Extensive experiments demonstrate that our method outperforms existing approaches. Qualitative results further show that our model more accurately identifies music relevant regions in paintings.
MMReID-Bench: Unleashing the Power of MLLMs for Effective and Versatile Person Re-identification
Aug 09, 2025Person re-identification (ReID) aims to retrieve the images of an interested person in the gallery images, with wide applications in medical rehabilitation, abnormal behavior detection, and public security. However, traditional person ReID models suffer from uni-modal capability, leading to poor generalization ability in multi-modal data, such as RGB, thermal, infrared, sketch images, textual descriptions, etc. Recently, the emergence of multi-modal large language models (MLLMs) shows a promising avenue for addressing this problem. Despite this potential, existing methods merely regard MLLMs as feature extractors or caption generators, which do not fully unleash their reasoning, instruction-following, and cross-modal understanding capabilities. To bridge this gap, we introduce MMReID-Bench, the first multi-task multi-modal benchmark specifically designed for person ReID. The MMReID-Bench includes 20,710 multi-modal queries and gallery images covering 10 different person ReID tasks. Comprehensive experiments demonstrate the remarkable capabilities of MLLMs in delivering effective and versatile person ReID. Nevertheless, they also have limitations in handling a few modalities, particularly thermal and infrared data. We hope MMReID-Bench can facilitate the community to develop more robust and generalizable multimodal foundation models for person ReID.
GT^2-GS: Geometry-aware Texture Transfer for Gaussian Splatting
May 21, 2025



Transferring 2D textures to 3D modalities is of great significance for improving the efficiency of multimedia content creation. Existing approaches have rarely focused on transferring image textures onto 3D representations. 3D style transfer methods are capable of transferring abstract artistic styles to 3D scenes. However, these methods often overlook the geometric information of the scene, which makes it challenging to achieve high-quality 3D texture transfer results. In this paper, we present GT^2-GS, a geometry-aware texture transfer framework for gaussian splitting. From the perspective of matching texture features with geometric information in rendered views, we identify the issue of insufficient texture features and propose a geometry-aware texture augmentation module to expand the texture feature set. Moreover, a geometry-consistent texture loss is proposed to optimize texture features into the scene representation. This loss function incorporates both camera pose and 3D geometric information of the scene, enabling controllable texture-oriented appearance editing. Finally, a geometry preservation strategy is introduced. By alternating between the texture transfer and geometry correction stages over multiple iterations, this strategy achieves a balance between learning texture features and preserving geometric integrity. Extensive experiments demonstrate the effectiveness and controllability of our method. Through geometric awareness, our approach achieves texture transfer results that better align with human visual perception. Our homepage is available at https://vpx-ecnu.github.io/GT2-GS-website.
LMP: Leveraging Motion Prior in Zero-Shot Video Generation with Diffusion Transformer
May 20, 2025In recent years, large-scale pre-trained diffusion transformer models have made significant progress in video generation. While current DiT models can produce high-definition, high-frame-rate, and highly diverse videos, there is a lack of fine-grained control over the video content. Controlling the motion of subjects in videos using only prompts is challenging, especially when it comes to describing complex movements. Further, existing methods fail to control the motion in image-to-video generation, as the subject in the reference image often differs from the subject in the reference video in terms of initial position, size, and shape. To address this, we propose the Leveraging Motion Prior (LMP) framework for zero-shot video generation. Our framework harnesses the powerful generative capabilities of pre-trained diffusion transformers to enable motion in the generated videos to reference user-provided motion videos in both text-to-video and image-to-video generation. To this end, we first introduce a foreground-background disentangle module to distinguish between moving subjects and backgrounds in the reference video, preventing interference in the target video generation. A reweighted motion transfer module is designed to allow the target video to reference the motion from the reference video. To avoid interference from the subject in the reference video, we propose an appearance separation module to suppress the appearance of the reference subject in the target video. We annotate the DAVIS dataset with detailed prompts for our experiments and design evaluation metrics to validate the effectiveness of our method. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in generation quality, prompt-video consistency, and control capability. Our homepage is available at https://vpx-ecnu.github.io/LMP-Website/
TimeSoccer: An End-to-End Multimodal Large Language Model for Soccer Commentary Generation
Apr 24, 2025Soccer is a globally popular sporting event, typically characterized by long matches and distinctive highlight moments. Recent advances in Multimodal Large Language Models (MLLMs) offer promising capabilities in temporal grounding and video understanding, soccer commentary generation often requires precise temporal localization and semantically rich descriptions over long-form video. However, existing soccer MLLMs often rely on the temporal a priori for caption generation, so they cannot process the soccer video end-to-end. While some traditional approaches follow a two-step paradigm that is complex and fails to capture the global context to achieve suboptimal performance. To solve the above issues, we present TimeSoccer, the first end-to-end soccer MLLM for Single-anchor Dense Video Captioning (SDVC) in full-match soccer videos. TimeSoccer jointly predicts timestamps and generates captions in a single pass, enabling global context modeling across 45-minute matches. To support long video understanding of soccer matches, we introduce MoFA-Select, a training-free, motion-aware frame compression module that adaptively selects representative frames via a coarse-to-fine strategy, and incorporates complementary training paradigms to strengthen the model's ability to handle long temporal sequences. Extensive experiments demonstrate that our TimeSoccer achieves State-of-The-Art (SoTA) performance on the SDVC task in an end-to-end form, generating high-quality commentary with accurate temporal alignment and strong semantic relevance.
OBIFormer: A Fast Attentive Denoising Framework for Oracle Bone Inscriptions
Apr 18, 2025
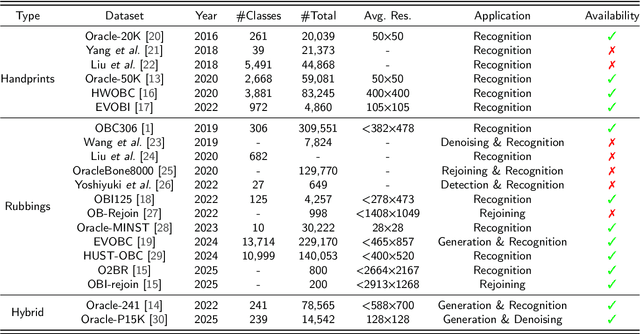
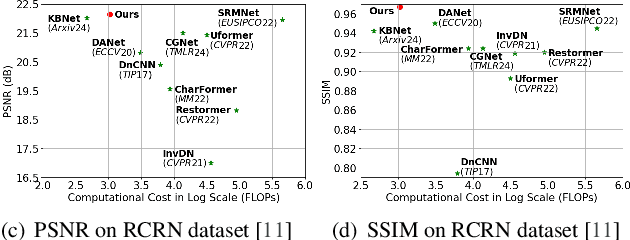
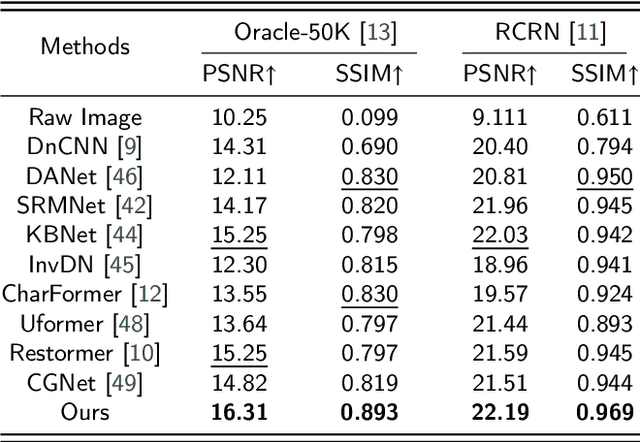
Oracle bone inscriptions (OBIs) are the earliest known form of Chinese characters and serve as a valuable resource for research in anthropology and archaeology. However, most excavated fragments are severely degraded due to thousands of years of natural weathering, corrosion, and man-made destruction, making automatic OBI recognition extremely challenging. Previous methods either focus on pixel-level information or utilize vanilla transformers for glyph-based OBI denoising, which leads to tremendous computational overhead. Therefore, this paper proposes a fast attentive denoising framework for oracle bone inscriptions, i.e., OBIFormer. It leverages channel-wise self-attention, glyph extraction, and selective kernel feature fusion to reconstruct denoised images precisely while being computationally efficient. Our OBIFormer achieves state-of-the-art denoising performance for PSNR and SSIM metrics on synthetic and original OBI datasets. Furthermore, comprehensive experiments on a real oracle dataset demonstrate the great potential of our OBIFormer in assisting automatic OBI recognition. The code will be made available at https://github.com/LJHolyGround/OBIFormer.
Mitigating Long-tail Distribution in Oracle Bone Inscriptions: Dataset, Model, and Benchmark
Apr 16, 2025The oracle bone inscription (OBI) recognition plays a significant role in understanding the history and culture of ancient China. However, the existing OBI datasets suffer from a long-tail distribution problem, leading to biased performance of OBI recognition models across majority and minority classes. With recent advancements in generative models, OBI synthesis-based data augmentation has become a promising avenue to expand the sample size of minority classes. Unfortunately, current OBI datasets lack large-scale structure-aligned image pairs for generative model training. To address these problems, we first present the Oracle-P15K, a structure-aligned OBI dataset for OBI generation and denoising, consisting of 14,542 images infused with domain knowledge from OBI experts. Second, we propose a diffusion model-based pseudo OBI generator, called OBIDiff, to achieve realistic and controllable OBI generation. Given a clean glyph image and a target rubbing-style image, it can effectively transfer the noise style of the original rubbing to the glyph image. Extensive experiments on OBI downstream tasks and user preference studies show the effectiveness of the proposed Oracle-P15K dataset and demonstrate that OBIDiff can accurately preserve inherent glyph structures while transferring authentic rubbing styles effectively.