 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPRSteg: Printing and Photography Robust QR Code Steganography via Attention Flow-Based Model
May 26, 2024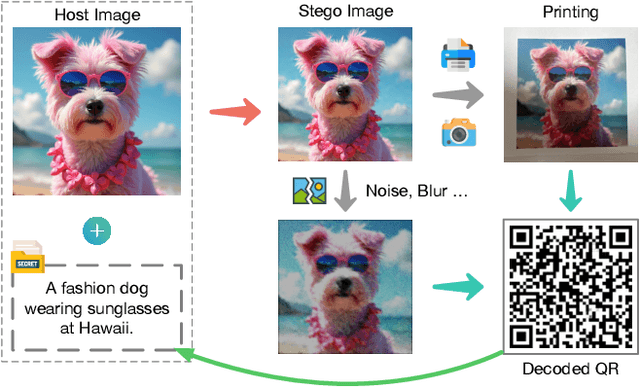
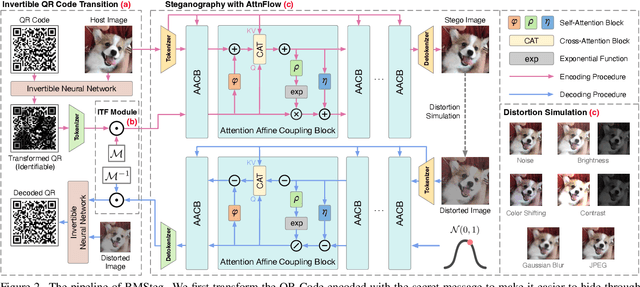


Image steganography can hide information in a host image and obtain a stego image that is perceptually indistinguishable from the original one. This technique has tremendous potential in scenarios like copyright protection, information retrospection, etc. Some previous studies have proposed to enhance the robustness of the methods against image disturbances to increase their applicability. However, they generally cannot achieve a satisfying balance between the steganography quality and robustness. In this paper, we focus on the issue of QR Code steganography that is robust to real-world printing and photography. Different from common image steganography, QR Code steganography aims to embed a non-natural image into a natural image and the restored QR Code is required to be recognizable, which increases the difficulty of data concealing and revealing. Inspired by the recent developments in transformer-based vision models, we discover that the tokenized representation of images is naturally suitable for steganography. In this paper, we propose a novel QR Code embedding framework, called Printing and Photography Robust Steganography (PPRSteg), which is competent to hide QR Code in a host image with unperceivable changes and can restore it even if the stego image is printed out and photoed. We outline a transition process to reduce the artifacts in stego images brought by QR Codes. We also propose a steganography model based on normalizing flow, which combines the attention mechanism to enhance its performance. To our best knowledge, this is the first work that integrates the advantages of transformer models into normalizing flow. We conduct comprehensive and detailed experiments to demonstrate the effectiveness of our method and the result shows that PPRSteg has great potential in robust, secure and high-quality QR Code steganography.
SalienTime: User-driven Selection of Salient Time Steps for Large-Scale Geospatial Data Visualization
Mar 06, 2024



The voluminous nature of geospatial temporal data from physical monitors and simulation models poses challenges to efficient data access, often resulting in cumbersome temporal selection experiences in web-based data portals. Thus, selecting a subset of time steps for prioritized visualization and pre-loading is highly desirable. Addressing this issue, this paper establishes a multifaceted definition of salient time steps via extensive need-finding studies with domain experts to understand their workflows. Building on this, we propose a novel approach that leverages autoencoders and dynamic programming to facilitate user-driven temporal selections. Structural features, statistical variations, and distance penalties are incorporated to make more flexible selections. User-specified priorities, spatial regions, and aggregations are used to combine different perspectives. We design and implement a web-based interface to enable efficient and context-aware selection of time steps and evaluate its efficacy and usability through case studies, quantitative evaluations, and expert interviews.
InvVis: Large-Scale Data Embedding for Invertible Visualization
Aug 04, 2023


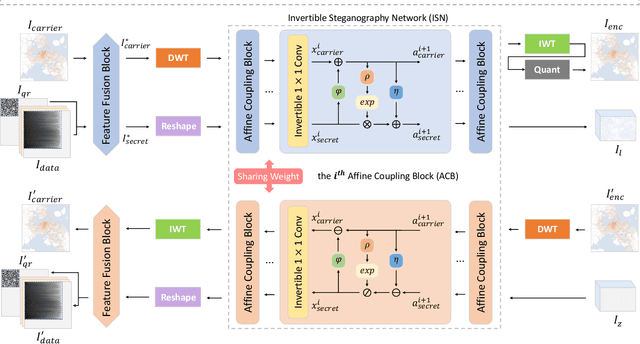
We present InvVis, a new approach for invertible visualization, which is reconstructing or further modifying a visualization from an image. InvVis allows the embedding of a significant amount of data, such as chart data, chart information, source code, etc., into visualization images. The encoded image is perceptually indistinguishable from the original one. We propose a new method to efficiently express chart data in the form of images, enabling large-capacity data embedding. We also outline a model based on the invertible neural network to achieve high-quality data concealing and revealing. We explore and implement a variety of application scenarios of InvVis. Additionally, we conduct a series of evaluation experiments to assess our method from multiple perspectives, including data embedding quality, data restoration accuracy, data encoding capacity, etc. The result of our experiments demonstrates the great potential of InvVis in invertible visualization.