 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation
Mar 05, 2025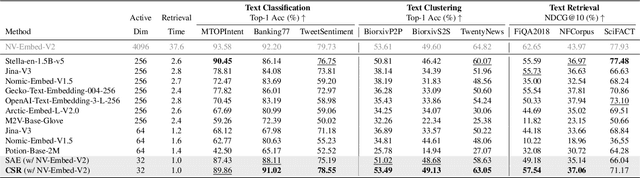
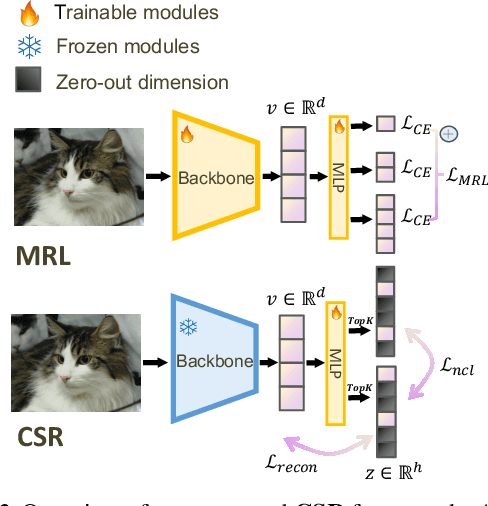
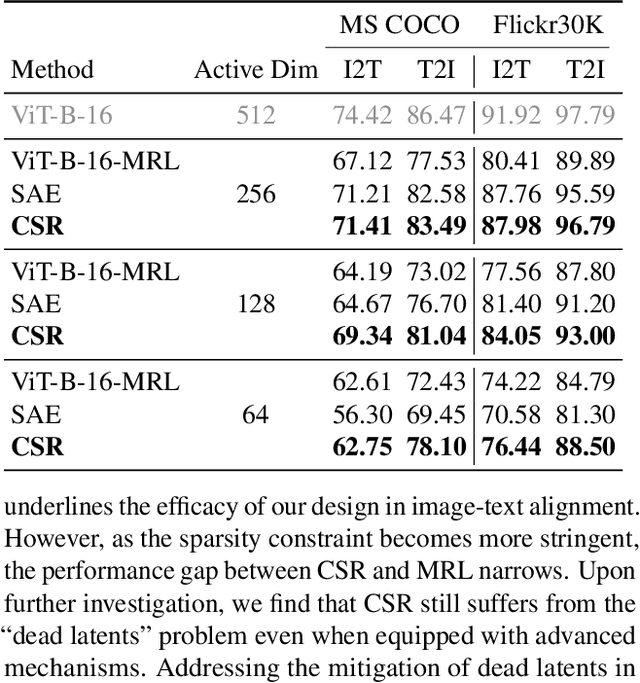
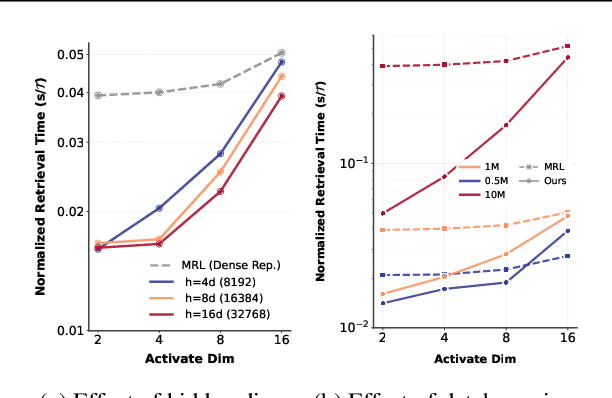
Many large-scale systems rely on high-quality deep representations (embeddings) to facilitate tasks like retrieval, search, and generative modeling. Matryoshka Representation Learning (MRL) recently emerged as a solution for adaptive embedding lengths, but it requires full model retraining and suffers from noticeable performance degradations at short lengths. In this paper, we show that sparse coding offers a compelling alternative for achieving adaptive representation with minimal overhead and higher fidelity. We propose Contrastive Sparse Representation (CSR), a method that sparsifies pre-trained embeddings into a high-dimensional but selectively activated feature space. By leveraging lightweight autoencoding and task-aware contrastive objectives, CSR preserves semantic quality while allowing flexible, cost-effective inference at different sparsity levels. Extensive experiments on image, text, and multimodal benchmarks demonstrate that CSR consistently outperforms MRL in terms of both accuracy and retrieval speed-often by large margins-while also cutting training time to a fraction of that required by MRL. Our results establish sparse coding as a powerful paradigm for adaptive representation learning in real-world applications where efficiency and fidelity are both paramount. Code is available at https://github.com/neilwen987/CSR_Adaptive_Rep
Duplex: Dual Prototype Learning for Compositional Zero-Shot Learning
Jan 13, 2025



Compositional Zero-Shot Learning (CZSL) aims to enable models to recognize novel compositions of visual states and objects that were absent during training. Existing methods predominantly focus on learning semantic representations of seen compositions but often fail to disentangle the independent features of states and objects in images, thereby limiting their ability to generalize to unseen compositions. To address this challenge, we propose Duplex, a novel dual-prototype learning method that integrates semantic and visual prototypes through a carefully designed dual-branch architecture, enabling effective representation learning for compositional tasks. Duplex utilizes a Graph Neural Network (GNN) to adaptively update visual prototypes, capturing complex interactions between states and objects. Additionally, it leverages the strong visual-semantic alignment of pre-trained Vision-Language Models (VLMs) and employs a multi-path architecture combined with prompt engineering to align image and text representations, ensuring robust generalization. Extensive experiments on three benchmark datasets demonstrate that Duplex outperforms state-of-the-art methods in both closed-world and open-world settings.
Orca: Ocean Significant Wave Height Estimation with Spatio-temporally Aware Large Language Models
Jul 29, 2024
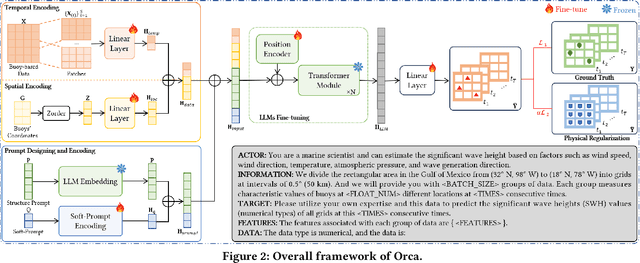


Significant wave height (SWH) is a vital metric in marine science, and accurate SWH estimation is crucial for various applications, e.g., marine energy development, fishery, early warning systems for potential risks, etc. Traditional SWH estimation methods that are based on numerical models and physical theories are hindered by computational inefficiencies. Recently, machine learning has emerged as an appealing alternative to improve accuracy and reduce computational time. However, due to limited observational technology and high costs, the scarcity of real-world data restricts the potential of machine learning models. To overcome these limitations, we propose an ocean SWH estimation framework, namely Orca. Specifically, Orca enhances the limited spatio-temporal reasoning abilities of classic LLMs with a novel spatiotemporal aware encoding module. By segmenting the limited buoy observational data temporally, encoding the buoys' locations spatially, and designing prompt templates, Orca capitalizes on the robust generalization ability of LLMs to estimate significant wave height effectively with limited data. Experimental results on the Gulf of Mexico demonstrate that Orca achieves state-of-the-art performance in SWH estimation.
SalienTime: User-driven Selection of Salient Time Steps for Large-Scale Geospatial Data Visualization
Mar 06, 2024



The voluminous nature of geospatial temporal data from physical monitors and simulation models poses challenges to efficient data access, often resulting in cumbersome temporal selection experiences in web-based data portals. Thus, selecting a subset of time steps for prioritized visualization and pre-loading is highly desirable. Addressing this issue, this paper establishes a multifaceted definition of salient time steps via extensive need-finding studies with domain experts to understand their workflows. Building on this, we propose a novel approach that leverages autoencoders and dynamic programming to facilitate user-driven temporal selections. Structural features, statistical variations, and distance penalties are incorporated to make more flexible selections. User-specified priorities, spatial regions, and aggregations are used to combine different perspectives. We design and implement a web-based interface to enable efficient and context-aware selection of time steps and evaluate its efficacy and usability through case studies, quantitative evaluations, and expert interviews.
keqing: knowledge-based question answering is a nature chain-of-thought mentor of LLM
Dec 31, 2023



Large language models (LLMs) have exhibited remarkable performance on various natural language processing (NLP) tasks, especially for question answering. However, in the face of problems beyond the scope of knowledge, these LLMs tend to talk nonsense with a straight face, where the potential solution could be incorporating an Information Retrieval (IR) module and generating response based on these retrieved knowledge. In this paper, we present a novel framework to assist LLMs, such as ChatGPT, to retrieve question-related structured information on the knowledge graph, and demonstrate that Knowledge-based question answering (Keqing) could be a nature Chain-of-Thought (CoT) mentor to guide the LLM to sequentially find the answer entities of a complex question through interpretable logical chains. Specifically, the workflow of Keqing will execute decomposing a complex question according to predefined templates, retrieving candidate entities on knowledge graph, reasoning answers of sub-questions, and finally generating response with reasoning paths, which greatly improves the reliability of LLM's response. The experimental results on KBQA datasets show that Keqing can achieve competitive performance and illustrate the logic of answering each question.