 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeART: Towards Agentic Time Series Reasoning via Tool-Augmentation
Jan 20, 2026Time series data widely exist in real-world cyber-physical systems. Though analyzing and interpreting them contributes to significant values, e.g, disaster prediction and financial risk control, current workflows mainly rely on human data scientists, which requires significant labor costs and lacks automation. To tackle this, we introduce TimeART, a framework fusing the analytical capability of strong out-of-the-box tools and the reasoning capability of Large Language Models (LLMs), which serves as a fully agentic data scientist for Time Series Question Answering (TSQA). To teach the LLM-based Time Series Reasoning Models (TSRMs) strategic tool-use, we also collect a 100k expert trajectory corpus called TimeToolBench. To enhance TSRMs' generalization capability, we then devise a four-stage training strategy, which boosts TSRMs through learning from their own early experiences and self-reflections. Experimentally, we train an 8B TSRM on TimeToolBench and equip it with the TimeART framework, and it achieves consistent state-of-the-art performance on multiple TSQA tasks, which pioneers a novel approach towards agentic time series reasoning.
Learning to Factorize and Adapt: A Versatile Approach Toward Universal Spatio-Temporal Foundation Models
Jan 17, 2026Spatio-Temporal (ST) Foundation Models (STFMs) promise cross-dataset generalization, yet joint ST pretraining is computationally expensive and grapples with the heterogeneity of domain-specific spatial patterns. Substantially extending our preliminary conference version, we present FactoST-v2, an enhanced factorized framework redesigned for full weight transfer and arbitrary-length generalization. FactoST-v2 decouples universal temporal learning from domain-specific spatial adaptation. The first stage pretrains a minimalist encoder-only backbone using randomized sequence masking to capture invariant temporal dynamics, enabling probabilistic quantile prediction across variable horizons. The second stage employs a streamlined adapter to rapidly inject spatial awareness via meta adaptive learning and prompting. Comprehensive evaluations across diverse domains demonstrate that FactoST-v2 achieves state-of-the-art accuracy with linear efficiency - significantly outperforming existing foundation models in zero-shot and few-shot scenarios while rivaling domain-specific expert baselines. This factorized paradigm offers a practical, scalable path toward truly universal STFMs. Code is available at https://github.com/CityMind-Lab/FactoST.
FLAME: Flow Enhanced Legendre Memory Models for General Time Series Forecasting
Dec 16, 2025
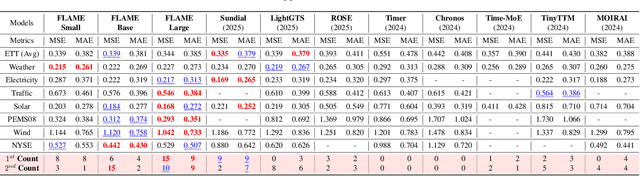
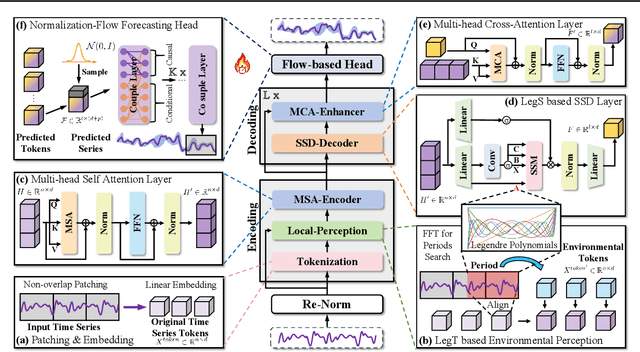

In this work, we introduce FLAME, a family of extremely lightweight and capable Time Series Foundation Models, which support both deterministic and probabilistic forecasting via generative probabilistic modeling, thus ensuring both efficiency and robustness. FLAME utilizes the Legendre Memory for strong generalization capabilities. Through adapting variants of Legendre Memory, i.e., translated Legendre (LegT) and scaled Legendre (LegS), in the Encoding and Decoding phases, FLAME can effectively capture the inherent inductive bias within data and make efficient long-range inferences. To enhance the accuracy of probabilistic forecasting while keeping efficient, FLAME adopts a Normalization Flow based forecasting head, which can model the arbitrarily intricate distributions over the forecasting horizon in a generative manner. Comprehensive experiments on well-recognized benchmarks, including TSFM-Bench and ProbTS, demonstrate the consistent state-of-the-art zero-shot performance of FLAME on both deterministic and probabilistic forecasting tasks.
Towards Non-Stationary Time Series Forecasting with Temporal Stabilization and Frequency Differencing
Nov 17, 2025Time series forecasting is critical for decision-making across dynamic domains such as energy, finance, transportation, and cloud computing. However, real-world time series often exhibit non-stationarity, including temporal distribution shifts and spectral variability, which pose significant challenges for long-term time series forecasting. In this paper, we propose DTAF, a dual-branch framework that addresses non-stationarity in both the temporal and frequency domains. For the temporal domain, the Temporal Stabilizing Fusion (TFS) module employs a non-stationary mix of experts (MOE) filter to disentangle and suppress temporal non-stationary patterns while preserving long-term dependencies. For the frequency domain, the Frequency Wave Modeling (FWM) module applies frequency differencing to dynamically highlight components with significant spectral shifts. By fusing the complementary outputs of TFS and FWM, DTAF generates robust forecasts that adapt to both temporal and frequency domain non-stationarity. Extensive experiments on real-world benchmarks demonstrate that DTAF outperforms state-of-the-art baselines, yielding significant improvements in forecasting accuracy under non-stationary conditions. All codes are available at https://github.com/PandaJunk/DTAF.
SwiftTS: A Swift Selection Framework for Time Series Pre-trained Models via Multi-task Meta-Learning
Oct 27, 2025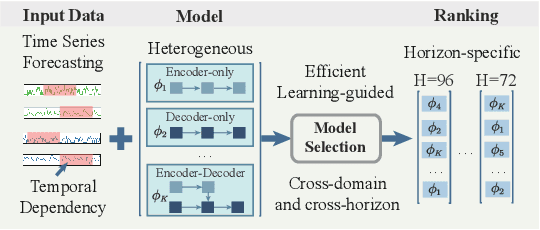
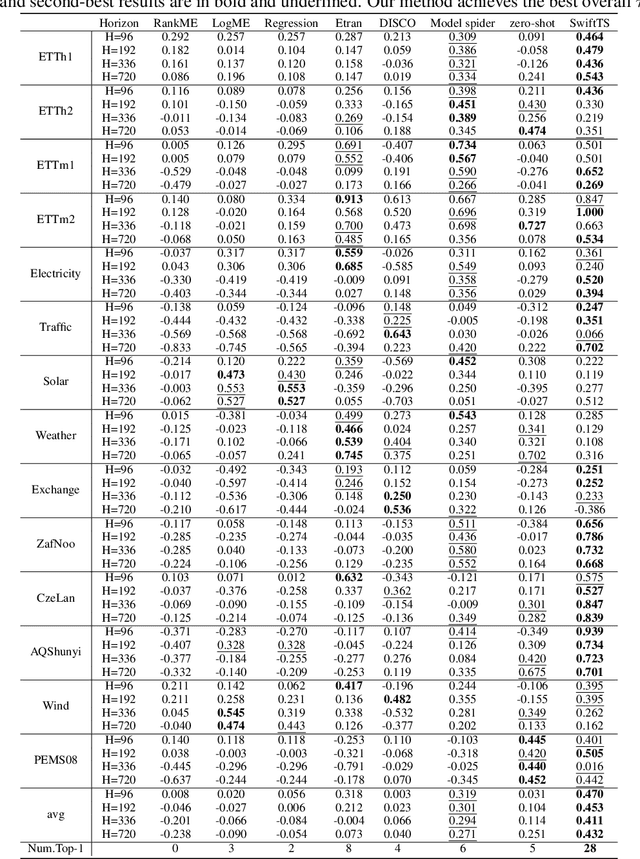
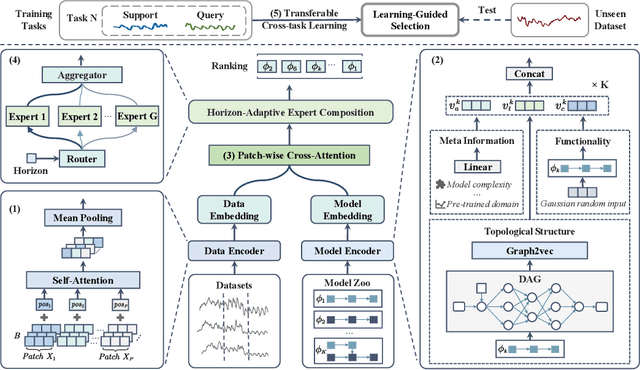
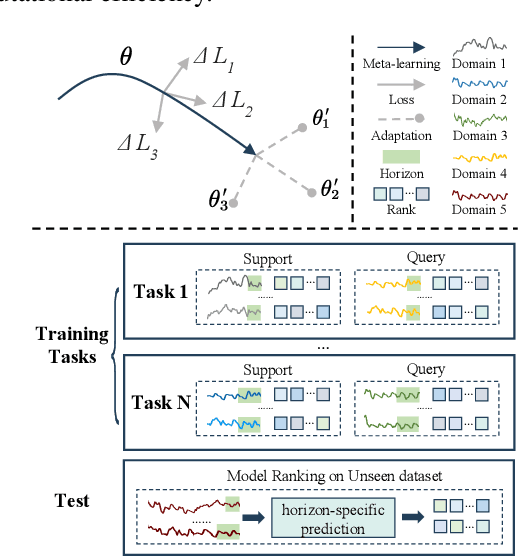
Pre-trained models exhibit strong generalization to various downstream tasks. However, given the numerous models available in the model hub, identifying the most suitable one by individually fine-tuning is time-consuming. In this paper, we propose \textbf{SwiftTS}, a swift selection framework for time series pre-trained models. To avoid expensive forward propagation through all candidates, SwiftTS adopts a learning-guided approach that leverages historical dataset-model performance pairs across diverse horizons to predict model performance on unseen datasets. It employs a lightweight dual-encoder architecture that embeds time series and candidate models with rich characteristics, computing patchwise compatibility scores between data and model embeddings for efficient selection. To further enhance the generalization across datasets and horizons, we introduce a horizon-adaptive expert composition module that dynamically adjusts expert weights, and the transferable cross-task learning with cross-dataset and cross-horizon task sampling to enhance out-of-distribution (OOD) robustness. Extensive experiments on 14 downstream datasets and 8 pre-trained models demonstrate that SwiftTS achieves state-of-the-art performance in time series pre-trained model selection.
An Encode-then-Decompose Approach to Unsupervised Time Series Anomaly Detection on Contaminated Training Data--Extended Version
Oct 21, 2025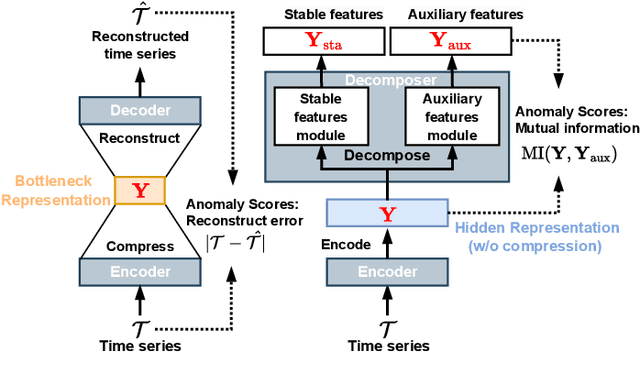
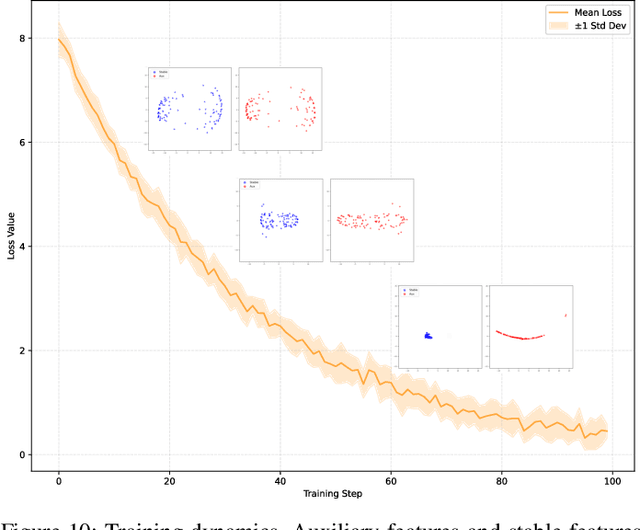
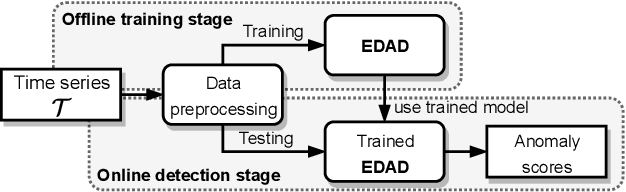
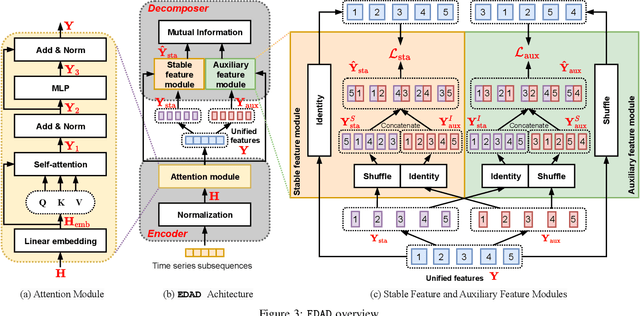
Time series anomaly detection is important in modern large-scale systems and is applied in a variety of domains to analyze and monitor the operation of diverse systems. Unsupervised approaches have received widespread interest, as they do not require anomaly labels during training, thus avoiding potentially high costs and having wider applications. Among these, autoencoders have received extensive attention. They use reconstruction errors from compressed representations to define anomaly scores. However, representations learned by autoencoders are sensitive to anomalies in training time series, causing reduced accuracy. We propose a novel encode-then-decompose paradigm, where we decompose the encoded representation into stable and auxiliary representations, thereby enhancing the robustness when training with contaminated time series. In addition, we propose a novel mutual information based metric to replace the reconstruction errors for identifying anomalies. Our proposal demonstrates competitive or state-of-the-art performance on eight commonly used multi- and univariate time series benchmarks and exhibits robustness to time series with different contamination ratios.
Enhancing Time Series Forecasting through Selective Representation Spaces: A Patch Perspective
Oct 16, 2025Time Series Forecasting has made significant progress with the help of Patching technique, which partitions time series into multiple patches to effectively retain contextual semantic information into a representation space beneficial for modeling long-term dependencies. However, conventional patching partitions a time series into adjacent patches, which causes a fixed representation space, thus resulting in insufficiently expressful representations. In this paper, we pioneer the exploration of constructing a selective representation space to flexibly include the most informative patches for forecasting. Specifically, we propose the Selective Representation Space (SRS) module, which utilizes the learnable Selective Patching and Dynamic Reassembly techniques to adaptively select and shuffle the patches from the contextual time series, aiming at fully exploiting the information of contextual time series to enhance the forecasting performance of patch-based models. To demonstrate the effectiveness of SRS module, we propose a simple yet effective SRSNet consisting of SRS and an MLP head, which achieves state-of-the-art performance on real-world datasets from multiple domains. Furthermore, as a novel plugin-and-play module, SRS can also enhance the performance of existing patch-based models. The resources are available at https://github.com/decisionintelligence/SRSNet.
CrossAD: Time Series Anomaly Detection with Cross-scale Associations and Cross-window Modeling
Oct 14, 2025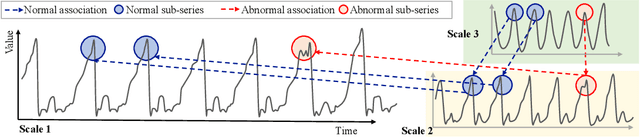
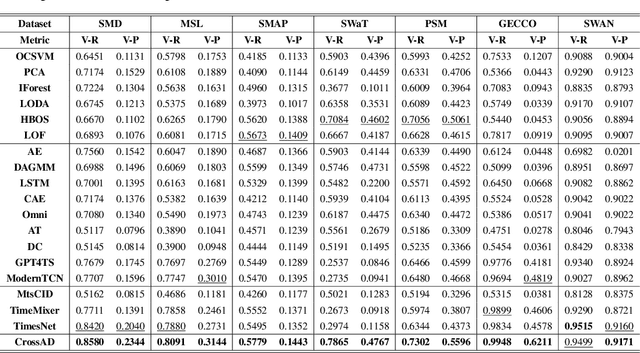
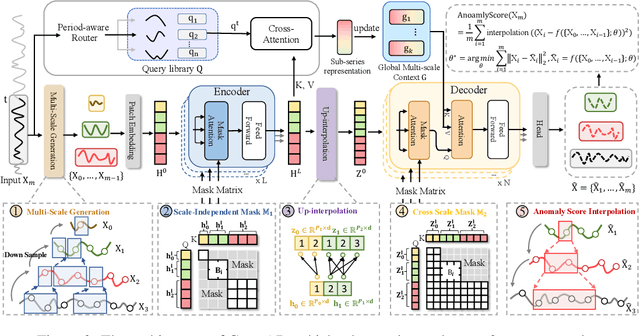
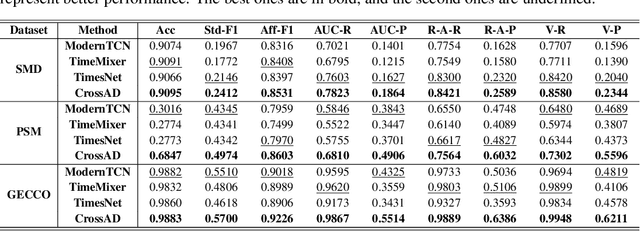
Time series anomaly detection plays a crucial role in a wide range of real-world applications. Given that time series data can exhibit different patterns at different sampling granularities, multi-scale modeling has proven beneficial for uncovering latent anomaly patterns that may not be apparent at a single scale. However, existing methods often model multi-scale information independently or rely on simple feature fusion strategies, neglecting the dynamic changes in cross-scale associations that occur during anomalies. Moreover, most approaches perform multi-scale modeling based on fixed sliding windows, which limits their ability to capture comprehensive contextual information. In this work, we propose CrossAD, a novel framework for time series Anomaly Detection that takes Cross-scale associations and Cross-window modeling into account. We propose a cross-scale reconstruction that reconstructs fine-grained series from coarser series, explicitly capturing cross-scale associations. Furthermore, we design a query library and incorporate global multi-scale context to overcome the limitations imposed by fixed window sizes. Extensive experiments conducted on multiple real-world datasets using nine evaluation metrics validate the effectiveness of CrossAD, demonstrating state-of-the-art performance in anomaly detection.
Aurora: Towards Universal Generative Multimodal Time Series Forecasting
Sep 26, 2025Cross-domain generalization is very important in Time Series Forecasting because similar historical information may lead to distinct future trends due to the domain-specific characteristics. Recent works focus on building unimodal time series foundation models and end-to-end multimodal supervised models. Since domain-specific knowledge is often contained in modalities like texts, the former lacks the explicit utilization of them, thus hindering the performance. The latter is tailored for end-to-end scenarios and does not support zero-shot inference for cross-domain scenarios. In this work, we introduce Aurora, a Multimodal Time Series Foundation Model, which supports multimodal inputs and zero-shot inference. Pretrained on Corss-domain Multimodal Time Series Corpus, Aurora can adaptively extract and focus on key domain knowledge contained in corrsponding text or image modalities, thus possessing strong Cross-domain generalization capability. Through tokenization, encoding, and distillation, Aurora can extract multimodal domain knowledge as guidance and then utilizes a Modality-Guided Multi-head Self-Attention to inject them into the modeling of temporal representations. In the decoding phase, the multimodal representations are used to generate the conditions and prototypes of future tokens, contributing to a novel Prototype-Guided Flow Matching for generative probabilistic forecasting. Comprehensive experiments on well-recognized benchmarks, including TimeMMD, TSFM-Bench and ProbTS, demonstrate the consistent state-of-the-art performance of Aurora on both unimodal and multimodal scenarios.
Unlocking the Power of Mixture-of-Experts for Task-Aware Time Series Analytics
Sep 26, 2025Time Series Analysis is widely used in various real-world applications such as weather forecasting, financial fraud detection, imputation for missing data in IoT systems, and classification for action recognization. Mixture-of-Experts (MoE), as a powerful architecture, though demonstrating effectiveness in NLP, still falls short in adapting to versatile tasks in time series analytics due to its task-agnostic router and the lack of capability in modeling channel correlations. In this study, we propose a novel, general MoE-based time series framework called PatchMoE to support the intricate ``knowledge'' utilization for distinct tasks, thus task-aware. Based on the observation that hierarchical representations often vary across tasks, e.g., forecasting vs. classification, we propose a Recurrent Noisy Gating to utilize the hierarchical information in routing, thus obtaining task-sepcific capability. And the routing strategy is operated on time series tokens in both temporal and channel dimensions, and encouraged by a meticulously designed Temporal \& Channel Load Balancing Loss to model the intricate temporal and channel correlations. Comprehensive experiments on five downstream tasks demonstrate the state-of-the-art performance of PatchMoE.