 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$K^2$VAE: A Koopman-Kalman Enhanced Variational AutoEncoder for Probabilistic Time Series Forecasting
May 29, 2025



Probabilistic Time Series Forecasting (PTSF) plays a crucial role in decision-making across various fields, including economics, energy, and transportation. Most existing methods excell at short-term forecasting, while overlooking the hurdles of Long-term Probabilistic Time Series Forecasting (LPTSF). As the forecast horizon extends, the inherent nonlinear dynamics have a significant adverse effect on prediction accuracy, and make generative models inefficient by increasing the cost of each iteration. To overcome these limitations, we introduce $K^2$VAE, an efficient VAE-based generative model that leverages a KoopmanNet to transform nonlinear time series into a linear dynamical system, and devises a KalmanNet to refine predictions and model uncertainty in such linear system, which reduces error accumulation in long-term forecasting. Extensive experiments demonstrate that $K^2$VAE outperforms state-of-the-art methods in both short- and long-term PTSF, providing a more efficient and accurate solution.
MM-Path: Multi-modal, Multi-granularity Path Representation Learning -- Extended Version
Nov 28, 2024



Developing effective path representations has become increasingly essential across various fields within intelligent transportation. Although pre-trained path representation learning models have shown improved performance, they predominantly focus on the topological structures from single modality data, i.e., road networks, overlooking the geometric and contextual features associated with path-related images, e.g., remote sensing images. Similar to human understanding, integrating information from multiple modalities can provide a more comprehensive view, enhancing both representation accuracy and generalization. However, variations in information granularity impede the semantic alignment of road network-based paths (road paths) and image-based paths (image paths), while the heterogeneity of multi-modal data poses substantial challenges for effective fusion and utilization. In this paper, we propose a novel Multi-modal, Multi-granularity Path Representation Learning Framework (MM-Path), which can learn a generic path representation by integrating modalities from both road paths and image paths. To enhance the alignment of multi-modal data, we develop a multi-granularity alignment strategy that systematically associates nodes, road sub-paths, and road paths with their corresponding image patches, ensuring the synchronization of both detailed local information and broader global contexts. To address the heterogeneity of multi-modal data effectively, we introduce a graph-based cross-modal residual fusion component designed to comprehensively fuse information across different modalities and granularities. Finally, we conduct extensive experiments on two large-scale real-world datasets under two downstream tasks, validating the effectiveness of the proposed MM-Path. The code is available at: https://github.com/decisionintelligence/MM-Path.
DiffImp: Efficient Diffusion Model for Probabilistic Time Series Imputation with Bidirectional Mamba Backbone
Oct 17, 2024
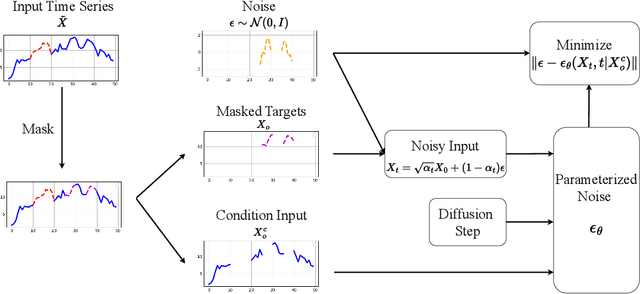
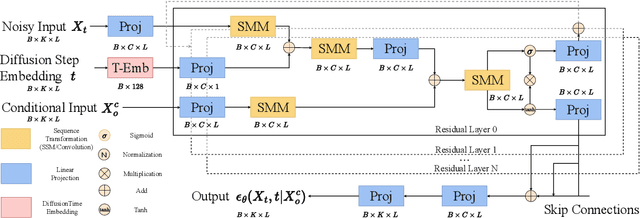
Probabilistic time series imputation has been widely applied in real-world scenarios due to its ability to estimate uncertainty of imputation results. Meanwhile, denoising diffusion probabilistic models (DDPMs) have achieved great success in probabilistic time series imputation tasks with its power to model complex distributions. However, current DDPM-based probabilistic time series imputation methodologies are confronted with two types of challenges: 1)~\textit{~The backbone modules of the denoising parts are not capable of achieving sequence modeling with low time complexity.} 2)~\textit{The architecture of denoising modules can not handle the inter-variable and bidirectional dependencies in the time series imputation problem effectively.} To address the first challenge, we integrate the computational efficient state space model, namely Mamba, as the backbone denosing module for DDPMs. To tackle the second challenge, we carefully devise several SSM-based blocks for bidirectional modeling and inter-variable relation understanding. Experimental results demonstrate that our approach can achieve state-of-the-art time series imputation results on multiple datasets, different missing scenarios and missing ratios.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
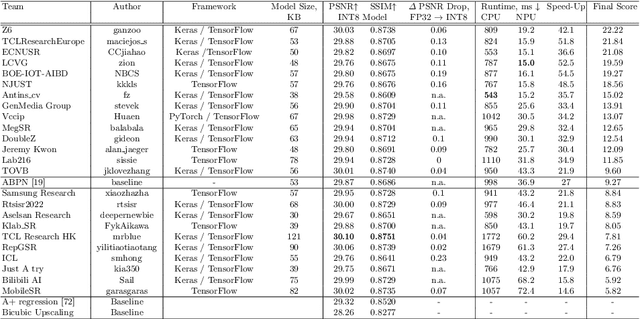
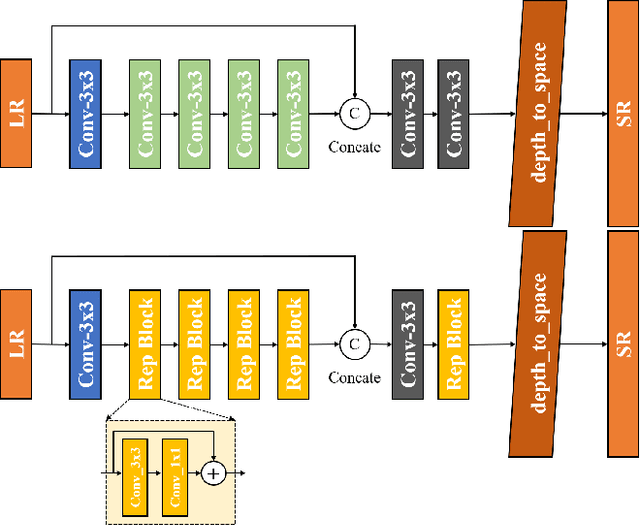
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.