 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAN: Enhance Time Series Anomaly Detection via Multi-Scale Neighborhood-Centered Clustering
Jun 17, 2026Time series anomaly detection plays a crucial role in a wide range of real-world applications. Reconstruction-based methods have become the mainstream paradigm, but they suffer from over-generalization and under-generalization problems, which are challenging to balance. To address this, we introduce multi-scale clustering to enhance reconstruction-based methods. At the representation level, we integrate the cluster center representations of normal patterns to constrain the model to target representative normal patterns for reconstruction, preventing dominance of powerful capacity and representation capability. At the anomaly criterion level, we derive anomaly confidence score based on cluster membership probability and combine it with reconstruction error, providing dual criteria for detection. Furthermore, the effectiveness of the cluster center representations and anomaly confidence score depends on the clustering performance. Accordingly, we extract neighborhood-centered representations for multi-view clustering to improve clustering performance. Extensive experiments on multiple real-world datasets from diverse application domains demonstrate the state-of-the-art performance of SCAN.
CoRA: Boosting Time Series Foundation Models for Multivariate Forecasting through Correlation-aware Adapter
Mar 23, 2026Most existing Time Series Foundation Models (TSFMs) use channel independent modeling and focus on capturing and generalizing temporal dependencies, while neglecting the correlations among channels or overlooking the different aspects of correlations. However, these correlations play a vital role in Multivariate time series forecasting. To address this, we propose a CoRrelation-aware Adapter (CoRA), a lightweight plug-and-play method that requires only fine-tuning with TSFMs and is able to capture different types of correlations, so as to improve forecast performance. Specifically, to reduce complexity, we innovatively decompose the correlation matrix into low-rank Time-Varying and Time-Invariant components. For the Time-Varying component, we further design learnable polynomials to learn dynamic correlations by capturing trends or periodic patterns. To learn positive and negative correlations that appear only among some channels, we introduce a novel dual contrastive learning method that identifies correlations through projection layers, regulated by a Heterogeneous-Partial contrastive loss during training, without introducing additional complexity in the inference stage. Extensive experiments on 10 real-world datasets demonstrate that CoRA can improve TSFMs in multivariate forecasting performance.
SEER: Transformer-based Robust Time Series Forecasting via Automated Patch Enhancement and Replacement
Jan 31, 2026Time series forecasting is important in many fields that require accurate predictions for decision-making. Patching techniques, commonly used and effective in time series modeling, help capture temporal dependencies by dividing the data into patches. However, existing patch-based methods fail to dynamically select patches and typically use all patches during the prediction process. In real-world time series, there are often low-quality issues during data collection, such as missing values, distribution shifts, anomalies and white noise, which may cause some patches to contain low-quality information, negatively impacting the prediction results. To address this issue, this study proposes a robust time series forecasting framework called SEER. Firstly, we propose an Augmented Embedding Module, which improves patch-wise representations using a Mixture-of-Experts (MoE) architecture and obtains series-wise token representations through a channel-adaptive perception mechanism. Secondly, we introduce a Learnable Patch Replacement Module, which enhances forecasting robustness and model accuracy through a two-stage process: 1) a dynamic filtering mechanism eliminates negative patch-wise tokens; 2) a replaced attention module substitutes the identified low-quality patches with global series-wise token, further refining their representations through a causal attention mechanism. Comprehensive experimental results demonstrate the SOTA performance of SEER.
FLAME: Flow Enhanced Legendre Memory Models for General Time Series Forecasting
Dec 16, 2025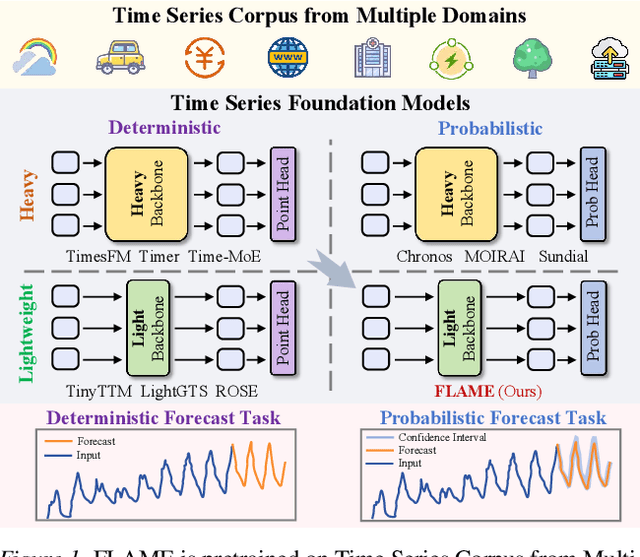
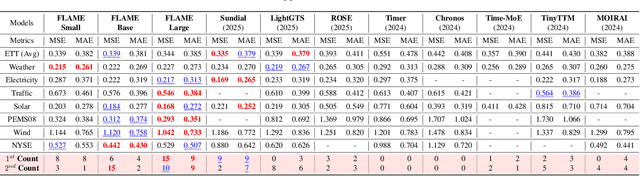
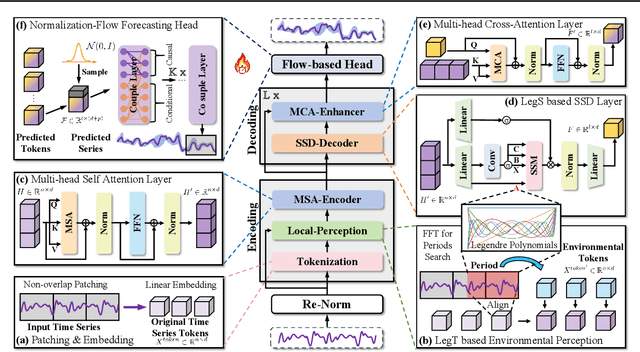

In this work, we introduce FLAME, a family of extremely lightweight and capable Time Series Foundation Models, which support both deterministic and probabilistic forecasting via generative probabilistic modeling, thus ensuring both efficiency and robustness. FLAME utilizes the Legendre Memory for strong generalization capabilities. Through adapting variants of Legendre Memory, i.e., translated Legendre (LegT) and scaled Legendre (LegS), in the Encoding and Decoding phases, FLAME can effectively capture the inherent inductive bias within data and make efficient long-range inferences. To enhance the accuracy of probabilistic forecasting while keeping efficient, FLAME adopts a Normalization Flow based forecasting head, which can model the arbitrarily intricate distributions over the forecasting horizon in a generative manner. Comprehensive experiments on well-recognized benchmarks, including TSFM-Bench and ProbTS, demonstrate the consistent state-of-the-art zero-shot performance of FLAME on both deterministic and probabilistic forecasting tasks.
Enhancing Time Series Forecasting through Selective Representation Spaces: A Patch Perspective
Oct 16, 2025Time Series Forecasting has made significant progress with the help of Patching technique, which partitions time series into multiple patches to effectively retain contextual semantic information into a representation space beneficial for modeling long-term dependencies. However, conventional patching partitions a time series into adjacent patches, which causes a fixed representation space, thus resulting in insufficiently expressful representations. In this paper, we pioneer the exploration of constructing a selective representation space to flexibly include the most informative patches for forecasting. Specifically, we propose the Selective Representation Space (SRS) module, which utilizes the learnable Selective Patching and Dynamic Reassembly techniques to adaptively select and shuffle the patches from the contextual time series, aiming at fully exploiting the information of contextual time series to enhance the forecasting performance of patch-based models. To demonstrate the effectiveness of SRS module, we propose a simple yet effective SRSNet consisting of SRS and an MLP head, which achieves state-of-the-art performance on real-world datasets from multiple domains. Furthermore, as a novel plugin-and-play module, SRS can also enhance the performance of existing patch-based models. The resources are available at https://github.com/decisionintelligence/SRSNet.
Unlocking the Power of Mixture-of-Experts for Task-Aware Time Series Analytics
Sep 26, 2025Time Series Analysis is widely used in various real-world applications such as weather forecasting, financial fraud detection, imputation for missing data in IoT systems, and classification for action recognization. Mixture-of-Experts (MoE), as a powerful architecture, though demonstrating effectiveness in NLP, still falls short in adapting to versatile tasks in time series analytics due to its task-agnostic router and the lack of capability in modeling channel correlations. In this study, we propose a novel, general MoE-based time series framework called PatchMoE to support the intricate ``knowledge'' utilization for distinct tasks, thus task-aware. Based on the observation that hierarchical representations often vary across tasks, e.g., forecasting vs. classification, we propose a Recurrent Noisy Gating to utilize the hierarchical information in routing, thus obtaining task-sepcific capability. And the routing strategy is operated on time series tokens in both temporal and channel dimensions, and encouraged by a meticulously designed Temporal \& Channel Load Balancing Loss to model the intricate temporal and channel correlations. Comprehensive experiments on five downstream tasks demonstrate the state-of-the-art performance of PatchMoE.
DAG: A Dual Causal Network for Time Series Forecasting with Exogenous Variables
Sep 18, 2025Time series forecasting is crucial in various fields such as economics, traffic, and AIOps. However, in real-world applications, focusing solely on the endogenous variables (i.e., target variables), is often insufficient to ensure accurate predictions. Considering exogenous variables (i.e., covariates) provides additional predictive information, thereby improving forecasting accuracy. However, existing methods for time series forecasting with exogenous variables (TSF-X) have the following shortcomings: 1) they do not leverage future exogenous variables, 2) they fail to account for the causal relationships between endogenous and exogenous variables. As a result, their performance is suboptimal. In this study, to better leverage exogenous variables, especially future exogenous variable, we propose a general framework DAG, which utilizes dual causal network along both the temporal and channel dimensions for time series forecasting with exogenous variables. Specifically, we first introduce the Temporal Causal Module, which includes a causal discovery module to capture how historical exogenous variables affect future exogenous variables. Following this, we construct a causal injection module that incorporates the discovered causal relationships into the process of forecasting future endogenous variables based on historical endogenous variables. Next, we propose the Channel Causal Module, which follows a similar design principle. It features a causal discovery module models how historical exogenous variables influence historical endogenous variables, and a causal injection module incorporates the discovered relationships to enhance the prediction of future endogenous variables based on future exogenous variables.
RCRank: Multimodal Ranking of Root Causes of Slow Queries in Cloud Database Systems
Mar 06, 2025



With the continued migration of storage to cloud database systems,the impact of slow queries in such systems on services and user experience is increasing. Root-cause diagnosis plays an indispensable role in facilitating slow-query detection and revision. This paper proposes a method capable of both identifying possible root cause types for slow queries and ranking these according to their potential for accelerating slow queries. This enables prioritizing root causes with the highest impact, in turn improving slow-query revision effectiveness. To enable more accurate and detailed diagnoses, we propose the multimodal Ranking for the Root Causes of slow queries (RCRank) framework, which formulates root cause analysis as a multimodal machine learning problem and leverages multimodal information from query statements, execution plans, execution logs, and key performance indicators. To obtain expressive embeddings from its heterogeneous multimodal input, RCRank integrates self-supervised pre-training that enhances cross-modal alignment and task relevance. Next, the framework integrates root-cause-adaptive cross Transformers that enable adaptive fusion of multimodal features with varying characteristics. Finally, the framework offers a unified model that features an impact-aware training objective for identifying and ranking root causes. We report on experiments on real and synthetic datasets, finding that RCRank is capable of consistently outperforming the state-of-the-art methods at root cause identification and ranking according to a range of metrics.
MM-Path: Multi-modal, Multi-granularity Path Representation Learning -- Extended Version
Nov 28, 2024



Developing effective path representations has become increasingly essential across various fields within intelligent transportation. Although pre-trained path representation learning models have shown improved performance, they predominantly focus on the topological structures from single modality data, i.e., road networks, overlooking the geometric and contextual features associated with path-related images, e.g., remote sensing images. Similar to human understanding, integrating information from multiple modalities can provide a more comprehensive view, enhancing both representation accuracy and generalization. However, variations in information granularity impede the semantic alignment of road network-based paths (road paths) and image-based paths (image paths), while the heterogeneity of multi-modal data poses substantial challenges for effective fusion and utilization. In this paper, we propose a novel Multi-modal, Multi-granularity Path Representation Learning Framework (MM-Path), which can learn a generic path representation by integrating modalities from both road paths and image paths. To enhance the alignment of multi-modal data, we develop a multi-granularity alignment strategy that systematically associates nodes, road sub-paths, and road paths with their corresponding image patches, ensuring the synchronization of both detailed local information and broader global contexts. To address the heterogeneity of multi-modal data effectively, we introduce a graph-based cross-modal residual fusion component designed to comprehensively fuse information across different modalities and granularities. Finally, we conduct extensive experiments on two large-scale real-world datasets under two downstream tasks, validating the effectiveness of the proposed MM-Path. The code is available at: https://github.com/decisionintelligence/MM-Path.
FoundTS: Comprehensive and Unified Benchmarking of Foundation Models for Time Series Forecasting
Oct 15, 2024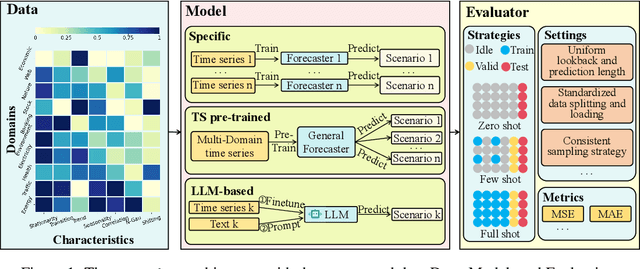
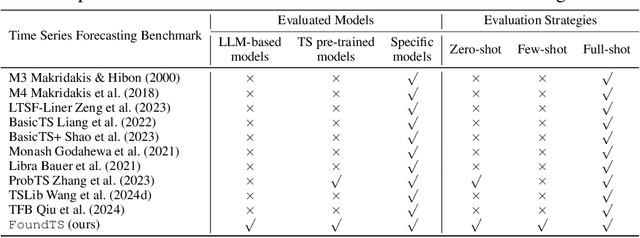
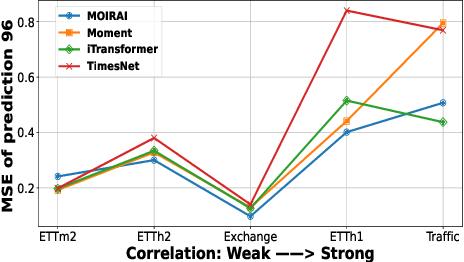
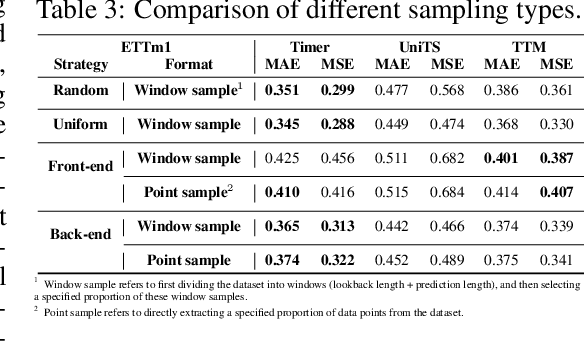
Time Series Forecasting (TSF) is key functionality in numerous fields, including in finance, weather services, and energy management. While TSF methods are emerging these days, many of them require domain-specific data collection and model training and struggle with poor generalization performance on new domains. Foundation models aim to overcome this limitation. Pre-trained on large-scale language or time series data, they exhibit promising inferencing capabilities in new or unseen data. This has spurred a surge in new TSF foundation models. We propose a new benchmark, FoundTS, to enable thorough and fair evaluation and comparison of such models. FoundTS covers a variety of TSF foundation models, including those based on large language models and those pretrained on time series. Next, FoundTS supports different forecasting strategies, including zero-shot, few-shot, and full-shot, thereby facilitating more thorough evaluations. Finally, FoundTS offers a pipeline that standardizes evaluation processes such as dataset splitting, loading, normalization, and few-shot sampling, thereby facilitating fair evaluations. Building on this, we report on an extensive evaluation of TSF foundation models on a broad range of datasets from diverse domains and with different statistical characteristics. Specifically, we identify pros and cons and inherent limitations of existing foundation models, and we identify directions for future model design. We make our code and datasets available at https://anonymous.4open.science/r/FoundTS-C2B0.