 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Encode-then-Decompose Approach to Unsupervised Time Series Anomaly Detection on Contaminated Training Data--Extended Version
Oct 21, 2025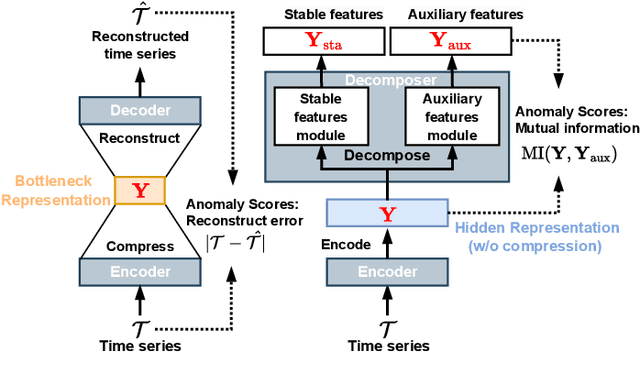
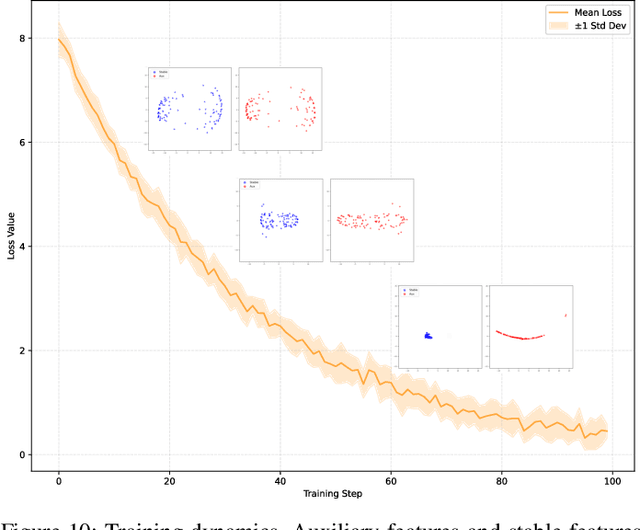
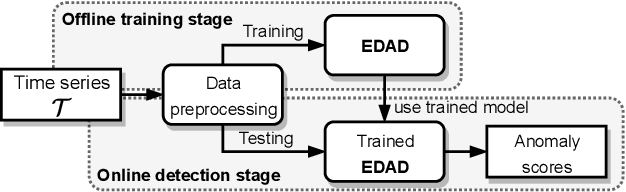
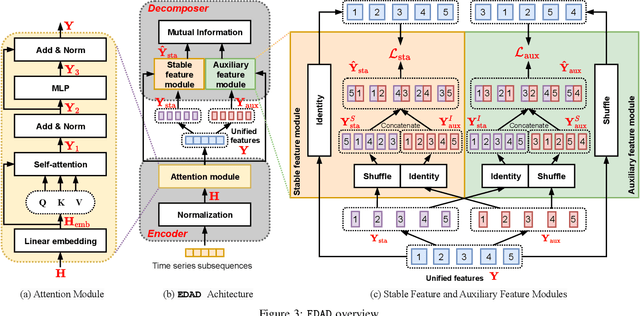
Time series anomaly detection is important in modern large-scale systems and is applied in a variety of domains to analyze and monitor the operation of diverse systems. Unsupervised approaches have received widespread interest, as they do not require anomaly labels during training, thus avoiding potentially high costs and having wider applications. Among these, autoencoders have received extensive attention. They use reconstruction errors from compressed representations to define anomaly scores. However, representations learned by autoencoders are sensitive to anomalies in training time series, causing reduced accuracy. We propose a novel encode-then-decompose paradigm, where we decompose the encoded representation into stable and auxiliary representations, thereby enhancing the robustness when training with contaminated time series. In addition, we propose a novel mutual information based metric to replace the reconstruction errors for identifying anomalies. Our proposal demonstrates competitive or state-of-the-art performance on eight commonly used multi- and univariate time series benchmarks and exhibits robustness to time series with different contamination ratios.
EasyTime: Time Series Forecasting Made Easy
Dec 23, 2024



Time series forecasting has important applications across diverse domains. EasyTime, the system we demonstrate, facilitates easy use of time-series forecasting methods by researchers and practitioners alike. First, EasyTime enables one-click evaluation, enabling researchers to evaluate new forecasting methods using the suite of diverse time series datasets collected in the preexisting time series forecasting benchmark (TFB). This is achieved by leveraging TFB's flexible and consistent evaluation pipeline. Second, when practitioners must perform forecasting on a new dataset, a nontrivial first step is often to find an appropriate forecasting method. EasyTime provides an Automated Ensemble module that combines the promising forecasting methods to yield superior forecasting accuracy compared to individual methods. Third, EasyTime offers a natural language Q&A module leveraging large language models. Given a question like "Which method is best for long term forecasting on time series with strong seasonality?", EasyTime converts the question into SQL queries on the database of results obtained by TFB and then returns an answer in natural language and charts. By demonstrating EasyTime, we intend to show how it is possible to simplify the use of time series forecasting and to offer better support for the development of new generations of time series forecasting methods.
Air Quality Prediction with Physics-Informed Dual Neural ODEs in Open Systems
Oct 25, 2024
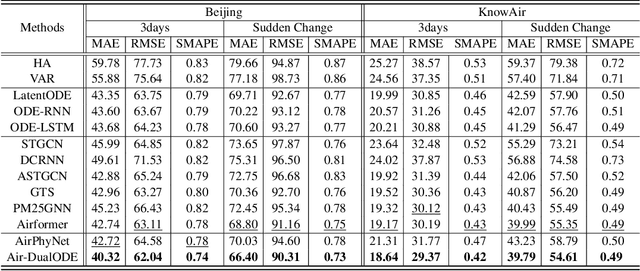
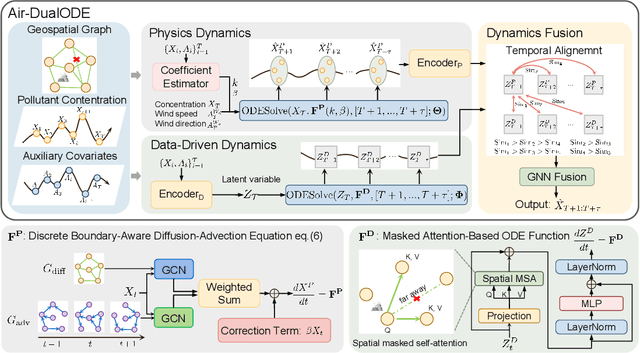
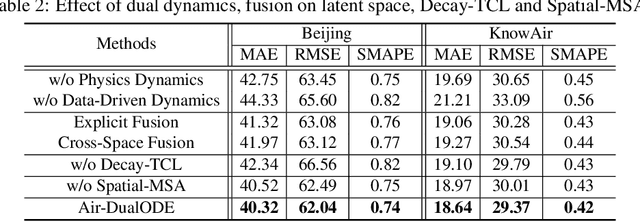
Air pollution significantly threatens human health and ecosystems, necessitating effective air quality prediction to inform public policy. Traditional approaches are generally categorized into physics-based and data-driven models. Physics-based models usually struggle with high computational demands and closed-system assumptions, while data-driven models may overlook essential physical dynamics, confusing the capturing of spatiotemporal correlations. Although some physics-informed approaches combine the strengths of both models, they often face a mismatch between explicit physical equations and implicit learned representations. To address these challenges, we propose Air-DualODE, a novel physics-informed approach that integrates dual branches of Neural ODEs for air quality prediction. The first branch applies open-system physical equations to capture spatiotemporal dependencies for learning physics dynamics, while the second branch identifies the dependencies not addressed by the first in a fully data-driven way. These dual representations are temporally aligned and fused to enhance prediction accuracy. Our experimental results demonstrate that Air-DualODE achieves state-of-the-art performance in predicting pollutant concentrations across various spatial scales, thereby offering a promising solution for real-world air quality challenges.
FoundTS: Comprehensive and Unified Benchmarking of Foundation Models for Time Series Forecasting
Oct 15, 2024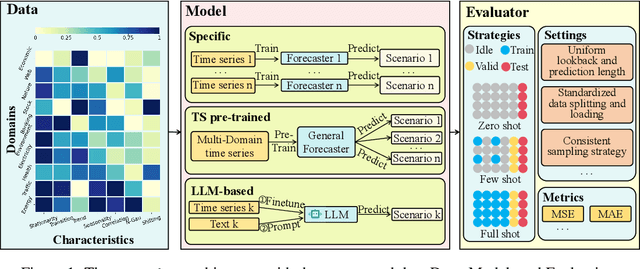
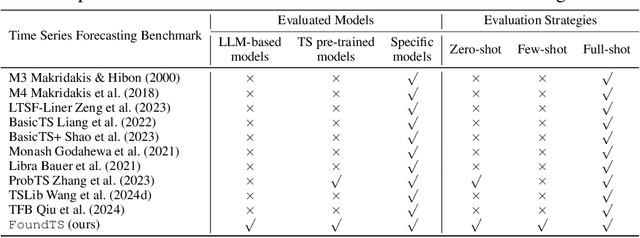
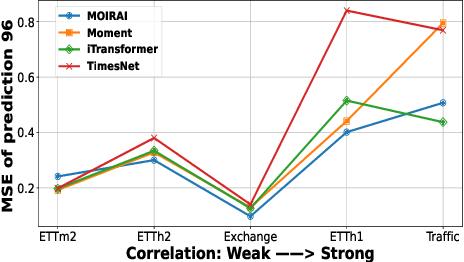
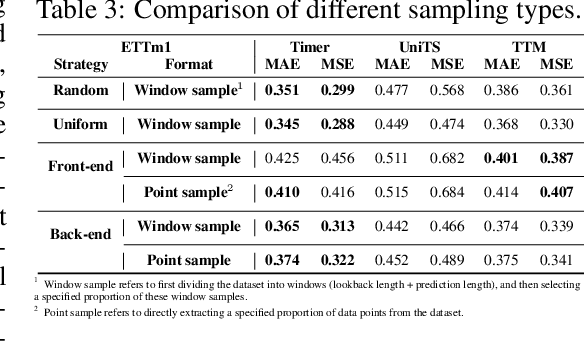
Time Series Forecasting (TSF) is key functionality in numerous fields, including in finance, weather services, and energy management. While TSF methods are emerging these days, many of them require domain-specific data collection and model training and struggle with poor generalization performance on new domains. Foundation models aim to overcome this limitation. Pre-trained on large-scale language or time series data, they exhibit promising inferencing capabilities in new or unseen data. This has spurred a surge in new TSF foundation models. We propose a new benchmark, FoundTS, to enable thorough and fair evaluation and comparison of such models. FoundTS covers a variety of TSF foundation models, including those based on large language models and those pretrained on time series. Next, FoundTS supports different forecasting strategies, including zero-shot, few-shot, and full-shot, thereby facilitating more thorough evaluations. Finally, FoundTS offers a pipeline that standardizes evaluation processes such as dataset splitting, loading, normalization, and few-shot sampling, thereby facilitating fair evaluations. Building on this, we report on an extensive evaluation of TSF foundation models on a broad range of datasets from diverse domains and with different statistical characteristics. Specifically, we identify pros and cons and inherent limitations of existing foundation models, and we identify directions for future model design. We make our code and datasets available at https://anonymous.4open.science/r/FoundTS-C2B0.
TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods
Apr 08, 2024



Time series are generated in diverse domains such as economic, traffic, health, and energy, where forecasting of future values has numerous important applications. Not surprisingly, many forecasting methods are being proposed. To ensure progress, it is essential to be able to study and compare such methods empirically in a comprehensive and reliable manner. To achieve this, we propose TFB, an automated benchmark for Time Series Forecasting (TSF) methods. TFB advances the state-of-the-art by addressing shortcomings related to datasets, comparison methods, and evaluation pipelines: 1) insufficient coverage of data domains, 2) stereotype bias against traditional methods, and 3) inconsistent and inflexible pipelines. To achieve better domain coverage, we include datasets from 10 different domains: traffic, electricity, energy, the environment, nature, economic, stock markets, banking, health, and the web. We also provide a time series characterization to ensure that the selected datasets are comprehensive. To remove biases against some methods, we include a diverse range of methods, including statistical learning, machine learning, and deep learning methods, and we also support a variety of evaluation strategies and metrics to ensure a more comprehensive evaluations of different methods. To support the integration of different methods into the benchmark and enable fair comparisons, TFB features a flexible and scalable pipeline that eliminates biases. Next, we employ TFB to perform a thorough evaluation of 21 Univariate Time Series Forecasting (UTSF) methods on 8,068 univariate time series and 14 Multivariate Time Series Forecasting (MTSF) methods on 25 datasets. The benchmark code and data are available at https://github.com/decisionintelligence/TFB.
Survey of Natural Language Processing for Education: Taxonomy, Systematic Review, and Future Trends
Jan 31, 2024



Natural Language Processing (NLP) aims to analyze the text via techniques in the computer science field. It serves the applications in healthcare, commerce, and education domains. Particularly, NLP has been applied to the education domain to help teaching and learning. In this survey, we review recent advances in NLP with a focus on solving problems related to the education domain. In detail, we begin with introducing the relevant background. Then, we present the taxonomy of NLP in the education domain. Next, we illustrate the task definition, challenges, and corresponding techniques based on the above taxonomy. After that, we showcase some off-the-shelf demonstrations in this domain and conclude with future directions.
TransPrompt v2: A Transferable Prompting Framework for Cross-task Text Classification
Aug 29, 2023Text classification is one of the most imperative tasks in natural language processing (NLP). Recent advances with pre-trained language models (PLMs) have shown remarkable success on this task. However, the satisfying results obtained by PLMs heavily depend on the large amounts of task-specific labeled data, which may not be feasible in many application scenarios due to data access and privacy constraints. The recently-proposed prompt-based fine-tuning paradigm improves the performance of PLMs for few-shot text classification with task-specific templates. Yet, it is unclear how the prompting knowledge can be transferred across tasks, for the purpose of mutual reinforcement. We propose TransPrompt v2, a novel transferable prompting framework for few-shot learning across similar or distant text classification tasks. For learning across similar tasks, we employ a multi-task meta-knowledge acquisition (MMA) procedure to train a meta-learner that captures the cross-task transferable knowledge. For learning across distant tasks, we further inject the task type descriptions into the prompt, and capture the intra-type and inter-type prompt embeddings among multiple distant tasks. Additionally, two de-biasing techniques are further designed to make the trained meta-learner more task-agnostic and unbiased towards any tasks. After that, the meta-learner can be adapted to each specific task with better parameters initialization. Extensive experiments show that TransPrompt v2 outperforms single-task and cross-task strong baselines over multiple NLP tasks and datasets. We further show that the meta-learner can effectively improve the performance of PLMs on previously unseen tasks. In addition, TransPrompt v2 also outperforms strong fine-tuning baselines when learning with full training sets.
Uncertainty-aware Self-training for Low-resource Neural Sequence Labeling
Feb 17, 2023

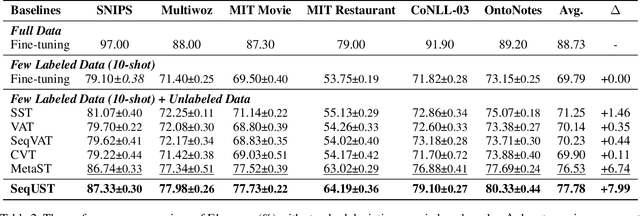

Neural sequence labeling (NSL) aims at assigning labels for input language tokens, which covers a broad range of applications, such as named entity recognition (NER) and slot filling, etc. However, the satisfying results achieved by traditional supervised-based approaches heavily depend on the large amounts of human annotation data, which may not be feasible in real-world scenarios due to data privacy and computation efficiency issues. This paper presents SeqUST, a novel uncertain-aware self-training framework for NSL to address the labeled data scarcity issue and to effectively utilize unlabeled data. Specifically, we incorporate Monte Carlo (MC) dropout in Bayesian neural network (BNN) to perform uncertainty estimation at the token level and then select reliable language tokens from unlabeled data based on the model confidence and certainty. A well-designed masked sequence labeling task with a noise-robust loss supports robust training, which aims to suppress the problem of noisy pseudo labels. In addition, we develop a Gaussian-based consistency regularization technique to further improve the model robustness on Gaussian-distributed perturbed representations. This effectively alleviates the over-fitting dilemma originating from pseudo-labeled augmented data. Extensive experiments over six benchmarks demonstrate that our SeqUST framework effectively improves the performance of self-training, and consistently outperforms strong baselines by a large margin in low-resource scenarios
* 11 pages, 3 figures
Meta-Learning Siamese Network for Few-Shot Text Classification
Feb 05, 2023



Few-shot learning has been used to tackle the problem of label scarcity in text classification, of which meta-learning based methods have shown to be effective, such as the prototypical networks (PROTO). Despite the success of PROTO, there still exist three main problems: (1) ignore the randomness of the sampled support sets when computing prototype vectors; (2) disregard the importance of labeled samples; (3) construct meta-tasks in a purely random manner. In this paper, we propose a Meta-Learning Siamese Network, namely, Meta-SN, to address these issues. Specifically, instead of computing prototype vectors from the sampled support sets, Meta-SN utilizes external knowledge (e.g. class names and descriptive texts) for class labels, which is encoded as the low-dimensional embeddings of prototype vectors. In addition, Meta-SN presents a novel sampling strategy for constructing meta-tasks, which gives higher sampling probabilities to hard-to-classify samples. Extensive experiments are conducted on six benchmark datasets to show the clear superiority of Meta-SN over other state-of-the-art models. For reproducibility, all the datasets and codes are provided at https://github.com/hccngu/Meta-SN.
Understanding Long Programming Languages with Structure-Aware Sparse Attention
May 27, 2022
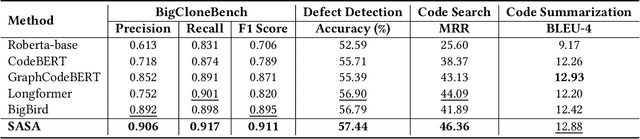

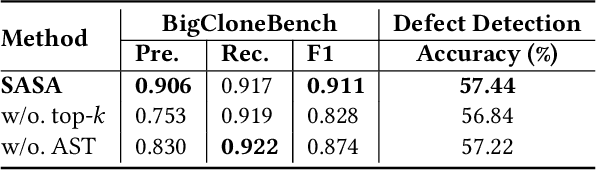
Programming-based Pre-trained Language Models (PPLMs) such as CodeBERT have achieved great success in many downstream code-related tasks. Since the memory and computational complexity of self-attention in the Transformer grow quadratically with the sequence length, PPLMs typically limit the code length to 512. However, codes in real-world applications are generally long, such as code searches, which cannot be processed efficiently by existing PPLMs. To solve this problem, in this paper, we present SASA, a Structure-Aware Sparse Attention mechanism, which reduces the complexity and improves performance for long code understanding tasks. The key components in SASA are top-$k$ sparse attention and Abstract Syntax Tree (AST)-based structure-aware attention. With top-$k$ sparse attention, the most crucial attention relation can be obtained with a lower computational cost. As the code structure represents the logic of the code statements, which is a complement to the code sequence characteristics, we further introduce AST structures into attention. Extensive experiments on CodeXGLUE tasks show that SASA achieves better performance than the competing baselines.