 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Framework for Spatial Interpolation: Merging Data-driven with Domain Knowledge
Sep 04, 2024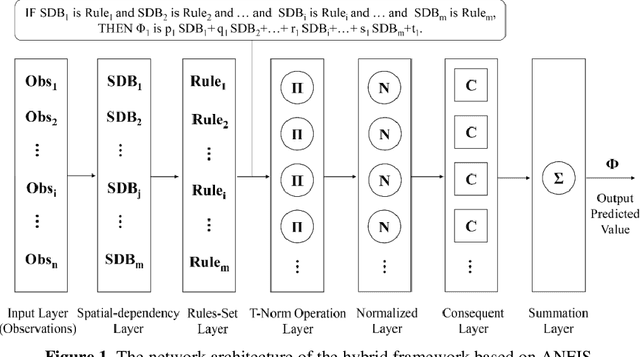

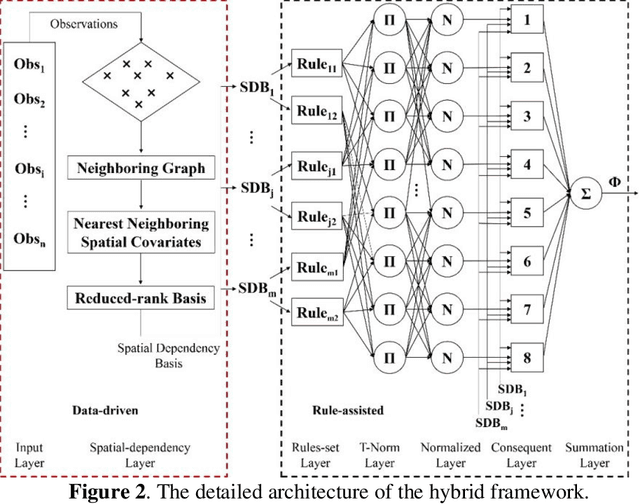
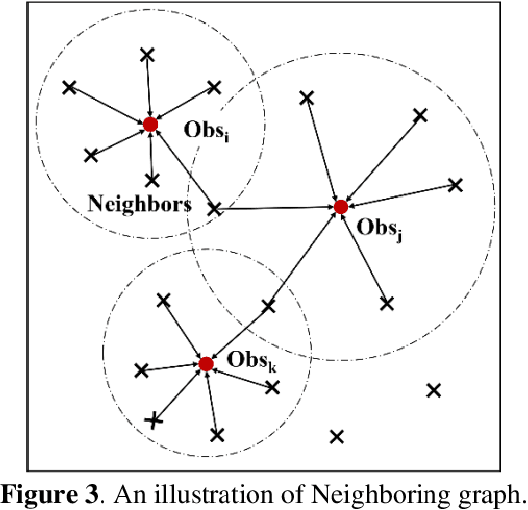
Estimating spatially distributed information through the interpolation of scattered observation datasets often overlooks the critical role of domain knowledge in understanding spatial dependencies. Additionally, the features of these data sets are typically limited to the spatial coordinates of the scattered observation locations. In this paper, we propose a hybrid framework that integrates data-driven spatial dependency feature extraction with rule-assisted spatial dependency function mapping to augment domain knowledge. We demonstrate the superior performance of our framework in two comparative application scenarios, highlighting its ability to capture more localized spatial features in the reconstructed distribution fields. Furthermore, we underscore its potential to enhance nonlinear estimation capabilities through the application of transformed fuzzy rules and to quantify the inherent uncertainties associated with the observation data sets. Our framework introduces an innovative approach to spatial information estimation by synergistically combining observational data with rule-assisted domain knowledge.
Toward Robust Early Detection of Alzheimer's Disease via an Integrated Multimodal Learning Approach
Aug 29, 2024


Alzheimer's Disease (AD) is a complex neurodegenerative disorder marked by memory loss, executive dysfunction, and personality changes. Early diagnosis is challenging due to subtle symptoms and varied presentations, often leading to misdiagnosis with traditional unimodal diagnostic methods due to their limited scope. This study introduces an advanced multimodal classification model that integrates clinical, cognitive, neuroimaging, and EEG data to enhance diagnostic accuracy. The model incorporates a feature tagger with a tabular data coding architecture and utilizes the TimesBlock module to capture intricate temporal patterns in Electroencephalograms (EEG) data. By employing Cross-modal Attention Aggregation module, the model effectively fuses Magnetic Resonance Imaging (MRI) spatial information with EEG temporal data, significantly improving the distinction between AD, Mild Cognitive Impairment, and Normal Cognition. Simultaneously, we have constructed the first AD classification dataset that includes three modalities: EEG, MRI, and tabular data. Our innovative approach aims to facilitate early diagnosis and intervention, potentially slowing the progression of AD. The source code and our private ADMC dataset are available at https://github.com/JustlfC03/MSTNet.
Are Linear Regression Models White Box and Interpretable?
Jul 16, 2024Explainable artificial intelligence (XAI) is a set of tools and algorithms that applied or embedded to machine learning models to understand and interpret the models. They are recommended especially for complex or advanced models including deep neural network because they are not interpretable from human point of view. On the other hand, simple models including linear regression are easy to implement, has less computational complexity and easy to visualize the output. The common notion in the literature that simple models including linear regression are considered as "white box" because they are more interpretable and easier to understand. This is based on the idea that linear regression models have several favorable outcomes including the effect of the features in the model and whether they affect positively or negatively toward model output. Moreover, uncertainty of the model can be measured or estimated using the confidence interval. However, we argue that this perception is not accurate and linear regression models are not easy to interpret neither easy to understand considering common XAI metrics and possible challenges might face. This includes linearity, local explanation, multicollinearity, covariates, normalization, uncertainty, features contribution and fairness. Consequently, we recommend the so-called simple models should be treated equally to complex models when it comes to explainability and interpretability.
Meta-Learning Siamese Network for Few-Shot Text Classification
Feb 05, 2023



Few-shot learning has been used to tackle the problem of label scarcity in text classification, of which meta-learning based methods have shown to be effective, such as the prototypical networks (PROTO). Despite the success of PROTO, there still exist three main problems: (1) ignore the randomness of the sampled support sets when computing prototype vectors; (2) disregard the importance of labeled samples; (3) construct meta-tasks in a purely random manner. In this paper, we propose a Meta-Learning Siamese Network, namely, Meta-SN, to address these issues. Specifically, instead of computing prototype vectors from the sampled support sets, Meta-SN utilizes external knowledge (e.g. class names and descriptive texts) for class labels, which is encoded as the low-dimensional embeddings of prototype vectors. In addition, Meta-SN presents a novel sampling strategy for constructing meta-tasks, which gives higher sampling probabilities to hard-to-classify samples. Extensive experiments are conducted on six benchmark datasets to show the clear superiority of Meta-SN over other state-of-the-art models. For reproducibility, all the datasets and codes are provided at https://github.com/hccngu/Meta-SN.