 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Atoms to Chains: Divergence-Guided Reasoning Curriculum for Unlabeled LLM Domain Adaptation
Jan 27, 2026Adapting Large Language Models (LLMs) to specialized domains without human-annotated data is a crucial yet formidable challenge. Widely adopted knowledge distillation methods often devolve into coarse-grained mimicry, where the student model inefficiently targets its own weaknesses and risks inheriting the teacher's reasoning flaws. This exposes a critical pedagogical dilemma: how to devise a reliable curriculum when the teacher itself is not an infallible expert. Our work resolves this by capitalizing on a key insight: while LLMs may exhibit fallibility in complex, holistic reasoning, they often exhibit high fidelity on focused, atomic sub-problems. Based on this, we propose Divergence-Guided Reasoning Curriculum (DGRC), which constructs a learning path from atomic knowledge to reasoning chains by dynamically deriving two complementary curricula from disagreements in reasoning pathways. When a student and teacher produce conflicting results, DGRC directs the teacher to perform a diagnostic analysis: it analyzes both reasoning paths to formulate atomic queries that target the specific points of divergence, and then self-answers these queries to create high-confidence atomic question-answer pairs. These pairs then serve a dual purpose: (1) providing an atomic curriculum to rectify the student's knowledge gaps, and (2) serving as factual criteria to filter the teacher's original reasoning chains, yielding a verified CoT curriculum that teaches the student how to integrate atomic knowledge into complete reasoning paths. Experiments across the medical and legal domains on student models of various sizes demonstrate the effectiveness of our DGRC framework. Notably, our method achieves a 7.76% relative improvement for the 1.5B student model in the medical domain over strong unlabeled baseline.
VIPER: Process-aware Evaluation for Generative Video Reasoning
Dec 31, 2025Recent breakthroughs in video generation have demonstrated an emerging capability termed Chain-of-Frames (CoF) reasoning, where models resolve complex tasks through the generation of continuous frames. While these models show promise for Generative Video Reasoning (GVR), existing evaluation frameworks often rely on single-frame assessments, which can lead to outcome-hacking, where a model reaches a correct conclusion through an erroneous process. To address this, we propose a process-aware evaluation paradigm. We introduce VIPER, a comprehensive benchmark spanning 16 tasks across temporal, structural, symbolic, spatial, physics, and planning reasoning. Furthermore, we propose Process-outcome Consistency (POC@r), a new metric that utilizes VLM-as-Judge with a hierarchical rubric to evaluate both the validity of the intermediate steps and the final result. Our experiments reveal that state-of-the-art video models achieve only about 20% POC@1.0 and exhibit a significant outcome-hacking. We further explore the impact of test-time scaling and sampling robustness, highlighting a substantial gap between current video generation and true generalized visual reasoning. Our benchmark will be publicly released.
VFaith: Do Large Multimodal Models Really Reason on Seen Images Rather than Previous Memories?
Jun 13, 2025Recent extensive works have demonstrated that by introducing long CoT, the capabilities of MLLMs to solve complex problems can be effectively enhanced. However, the reasons for the effectiveness of such paradigms remain unclear. It is challenging to analysis with quantitative results how much the model's specific extraction of visual cues and its subsequent so-called reasoning during inference process contribute to the performance improvements. Therefore, evaluating the faithfulness of MLLMs' reasoning to visual information is crucial. To address this issue, we first present a cue-driven automatic and controllable editing pipeline with the help of GPT-Image-1. It enables the automatic and precise editing of specific visual cues based on the instruction. Furthermore, we introduce VFaith-Bench, the first benchmark to evaluate MLLMs' visual reasoning capabilities and analyze the source of such capabilities with an emphasis on the visual faithfulness. Using the designed pipeline, we constructed comparative question-answer pairs by altering the visual cues in images that are crucial for solving the original reasoning problem, thereby changing the question's answer. By testing similar questions with images that have different details, the average accuracy reflects the model's visual reasoning ability, while the difference in accuracy before and after editing the test set images effectively reveals the relationship between the model's reasoning ability and visual perception. We further designed specific metrics to expose this relationship. VFaith-Bench includes 755 entries divided into five distinct subsets, along with an additional human-labeled perception task. We conducted in-depth testing and analysis of existing mainstream flagship models and prominent open-source model series/reasoning models on VFaith-Bench, further investigating the underlying factors of their reasoning capabilities.
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO
May 22, 2025In this work, we aim to incentivize the reasoning ability of Multimodal Large Language Models (MLLMs) via reinforcement learning (RL) and develop an effective approach that mitigates the sparse reward and advantage vanishing issues during RL. To this end, we propose Share-GRPO, a novel RL approach that tackle these issues by exploring and sharing diverse reasoning trajectories over expanded question space. Specifically, Share-GRPO first expands the question space for a given question via data transformation techniques, and then encourages MLLM to effectively explore diverse reasoning trajectories over the expanded question space and shares the discovered reasoning trajectories across the expanded questions during RL. In addition, Share-GRPO also shares reward information during advantage computation, which estimates solution advantages hierarchically across and within question variants, allowing more accurate estimation of relative advantages and improving the stability of policy training. Extensive evaluations over six widely-used reasoning benchmarks showcase the superior performance of our method. Code will be available at https://github.com/HJYao00/R1-ShareVL.
Reinforced MLLM: A Survey on RL-Based Reasoning in Multimodal Large Language Models
Apr 30, 2025The integration of reinforcement learning (RL) into the reasoning capabilities of Multimodal Large Language Models (MLLMs) has rapidly emerged as a transformative research direction. While MLLMs significantly extend Large Language Models (LLMs) to handle diverse modalities such as vision, audio, and video, enabling robust reasoning across multimodal inputs remains a major challenge. This survey systematically reviews recent advances in RL-based reasoning for MLLMs, covering key algorithmic designs, reward mechanism innovations, and practical applications. We highlight two main RL paradigms--value-free and value-based methods--and analyze how RL enhances reasoning abilities by optimizing reasoning trajectories and aligning multimodal information. Furthermore, we provide an extensive overview of benchmark datasets, evaluation protocols, and existing limitations, and propose future research directions to address current bottlenecks such as sparse rewards, inefficient cross-modal reasoning, and real-world deployment constraints. Our goal is to offer a comprehensive and structured guide to researchers interested in advancing RL-based reasoning in the multimodal era.
Valley2: Exploring Multimodal Models with Scalable Vision-Language Design
Jan 13, 2025



Recently, vision-language models have made remarkable progress, demonstrating outstanding capabilities in various tasks such as image captioning and video understanding. We introduce Valley2, a novel multimodal large language model designed to enhance performance across all domains and extend the boundaries of practical applications in e-commerce and short video scenarios. Notably, Valley2 achieves state-of-the-art (SOTA) performance on e-commerce benchmarks, surpassing open-source models of similar size by a large margin (79.66 vs. 72.76). Additionally, Valley2 ranks second on the OpenCompass leaderboard among models with fewer than 10B parameters, with an impressive average score of 67.4. The code and model weights are open-sourced at https://github.com/bytedance/Valley.
Reverse Modeling in Large Language Models
Oct 13, 2024



Humans are accustomed to reading and writing in a forward manner, and this natural bias extends to text understanding in auto-regressive large language models (LLMs). This paper investigates whether LLMs, like humans, struggle with reverse modeling, specifically with reversed text inputs. We found that publicly available pre-trained LLMs cannot understand such inputs. However, LLMs trained from scratch with both forward and reverse texts can understand them equally well during inference. Our case study shows that different-content texts result in different losses if input (to LLMs) in different directions -- some get lower losses for forward while some for reverse. This leads us to a simple and nice solution for data selection based on the loss differences between forward and reverse directions. Using our selected data in continued pretraining can boost LLMs' performance by a large margin across different language understanding benchmarks.
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024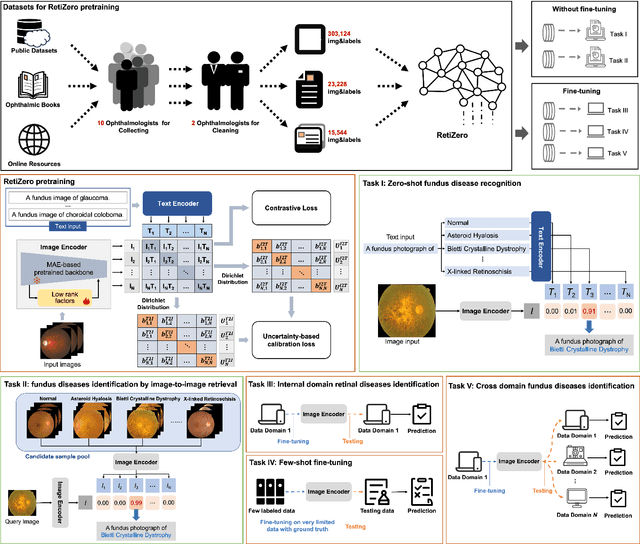
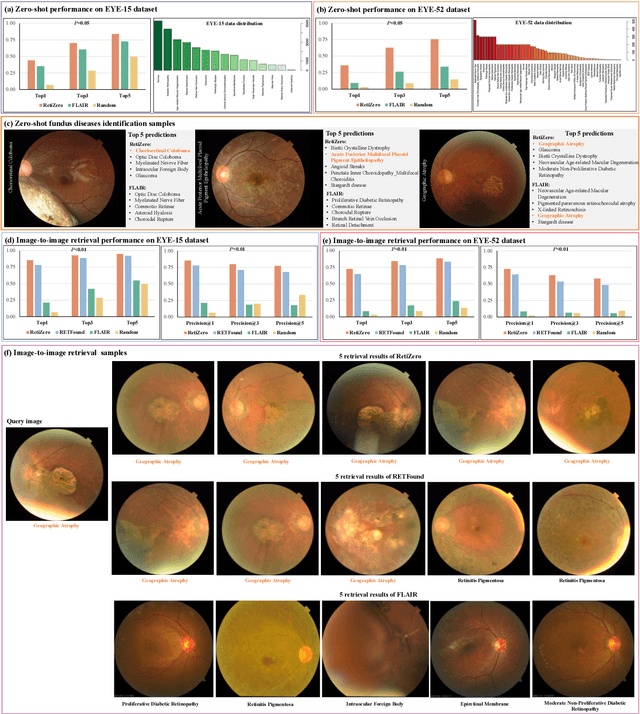
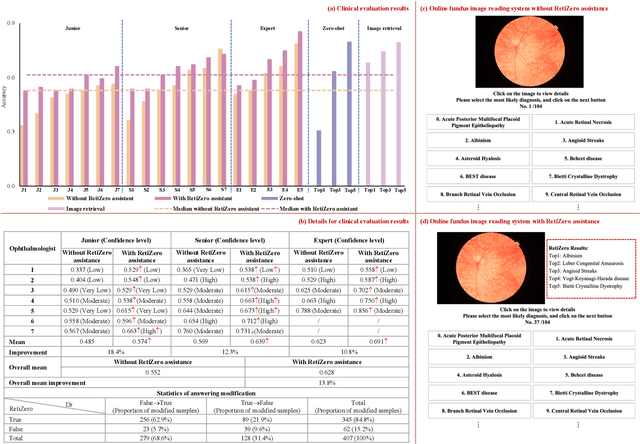
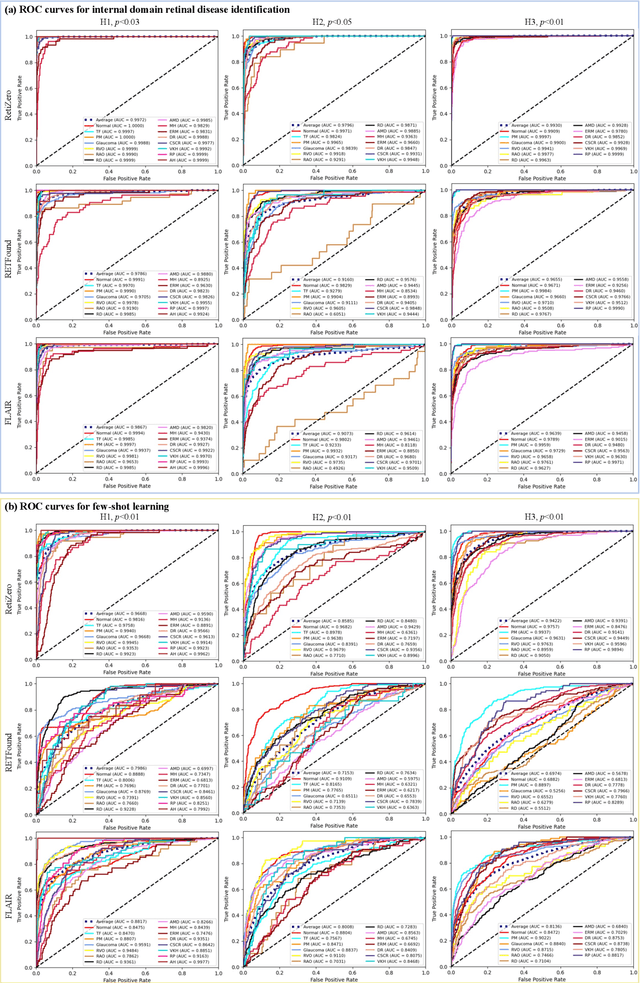
The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.
VoCoT: Unleashing Visually Grounded Multi-Step Reasoning in Large Multi-Modal Models
May 28, 2024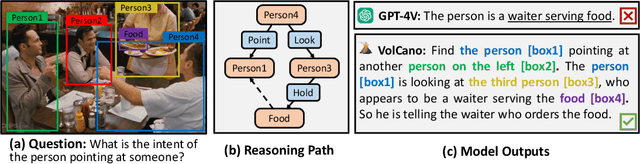

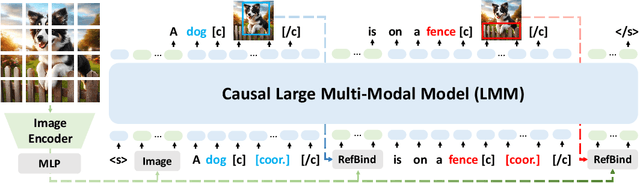
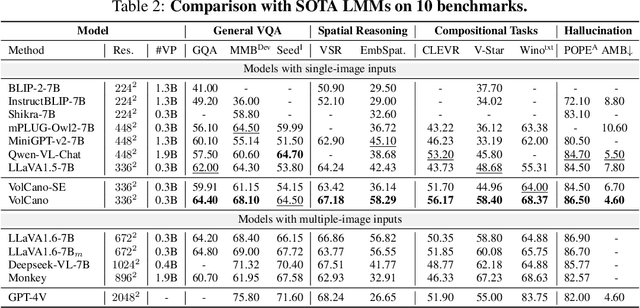
While large multi-modal models (LMMs) have exhibited impressive capabilities across diverse tasks, their effectiveness in handling complex tasks has been limited by the prevailing single-step reasoning paradigm. To this end, this paper proposes VoCoT, a multi-step Visually grounded object-centric Chain-of-Thought reasoning framework tailored for inference with LMMs. VoCoT is characterized by two key features: (1) object-centric reasoning paths that revolve around cross-modal shared object-level information, and (2) visually grounded representation of object concepts in a multi-modal interleaved and aligned manner, which effectively bridges the modality gap within LMMs during long-term generation. Additionally, we construct an instruction dataset to facilitate LMMs in adapting to reasoning with VoCoT. By introducing VoCoT into the prevalent open-source LMM architecture, we introduce VolCano. With only 7B parameters and limited input resolution, VolCano demonstrates excellent performance across various scenarios, surpassing SOTA models, including GPT-4V, in tasks requiring complex reasoning. Our code, data and model will be available at https://github.com/RupertLuo/VoCoT.
CODA: A COst-efficient Test-time Domain Adaptation Mechanism for HAR
Mar 22, 2024In recent years, emerging research on mobile sensing has led to novel scenarios that enhance daily life for humans, but dynamic usage conditions often result in performance degradation when systems are deployed in real-world settings. Existing solutions typically employ one-off adaptation schemes based on neural networks, which struggle to ensure robustness against uncertain drifting conditions in human-centric sensing scenarios. In this paper, we propose CODA, a COst-efficient Domain Adaptation mechanism for mobile sensing that addresses real-time drifts from the data distribution perspective with active learning theory, ensuring cost-efficient adaptation directly on the device. By incorporating a clustering loss and importance-weighted active learning algorithm, CODA retains the relationship between different clusters during cost-effective instance-level updates, preserving meaningful structure within the data distribution. We also showcase its generalization by seamlessly integrating it with Neural Network-based solutions for Human Activity Recognition tasks. Through meticulous evaluations across diverse datasets, including phone-based, watch-based, and integrated sensor-based sensing tasks, we demonstrate the feasibility and potential of online adaptation with CODA. The promising results achieved by CODA, even without learnable parameters, also suggest the possibility of realizing unobtrusive adaptation through specific application designs with sufficient feedback.