 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolygon-mamba: Retinal vessel segmentation using polygon scanning mamba and space-frequency collaborative attention
May 11, 2026Retinal vessel segmentation is crucial for diagnosis and assessment of ocular diseases. Notably, segmentation of small retinal vessels has been consistently recognized as a challenging and complex task. To tackle this challenge, we design a hybrid CNN-Mamba fusion network that integrates polygon scanning mamba and space-frequency collaborative attention mechanism for the detection of small vessels. Considering that the traditional mamba architecture with horizontal-vertical scanning may compromise the topological integrity of target structures and result in local discontinuities in small retinal vessels, we present a polygon scanning visual state space model (PS-VSS) to identify small vessel structural features by multi-layer reverse scanning way. Which effectively preserves pixels connectivity, thereby substantially mitigating the loss of information pertaining to small vessels. Furthermore, as we all known that the spatial domain prioritizes positional and structural information, while the frequency domain emphasizes global perception and local detail components, a space-frequency collaborative attention mechanism (SFCAM) is introduced within the skip connection to extract efficient features from the spatial and frequency domains. This strategy empowers the model to dynamically enhance the key features while effectively suppressing clutters. To assess the efficacy of our model, it was tested on three publicly available datasets: DRIVE, STARE, and CHASE_DB1. Compared to manual annotations, our model demonstrated F1 scores of 0.8283, 0.8282, and 0.8251, Area Under Curve (AUC) values of 0.9806, 0.9840, and 0.9866, and Sensitivity (SE) values of of 0.8268, 0.8314, and 0.8484 across three datasets, respectively. The effectiveness of our model was validated through both visual inspection and quantitative analysis.
Beyond Classification Accuracy: Neural-MedBench and the Need for Deeper Reasoning Benchmarks
Sep 26, 2025Recent advances in vision-language models (VLMs) have achieved remarkable performance on standard medical benchmarks, yet their true clinical reasoning ability remains unclear. Existing datasets predominantly emphasize classification accuracy, creating an evaluation illusion in which models appear proficient while still failing at high-stakes diagnostic reasoning. We introduce Neural-MedBench, a compact yet reasoning-intensive benchmark specifically designed to probe the limits of multimodal clinical reasoning in neurology. Neural-MedBench integrates multi-sequence MRI scans, structured electronic health records, and clinical notes, and encompasses three core task families: differential diagnosis, lesion recognition, and rationale generation. To ensure reliable evaluation, we develop a hybrid scoring pipeline that combines LLM-based graders, clinician validation, and semantic similarity metrics. Through systematic evaluation of state-of-the-art VLMs, including GPT-4o, Claude-4, and MedGemma, we observe a sharp performance drop compared to conventional datasets. Error analysis shows that reasoning failures, rather than perceptual errors, dominate model shortcomings. Our findings highlight the necessity of a Two-Axis Evaluation Framework: breadth-oriented large datasets for statistical generalization, and depth-oriented, compact benchmarks such as Neural-MedBench for reasoning fidelity. We release Neural-MedBench at https://neuromedbench.github.io/ as an open and extensible diagnostic testbed, which guides the expansion of future benchmarks and enables rigorous yet cost-effective assessment of clinically trustworthy AI.
A Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
Enhancing Diagnostic Reliability of Foundation Model with Uncertainty Estimation in OCT Images
Jun 18, 2024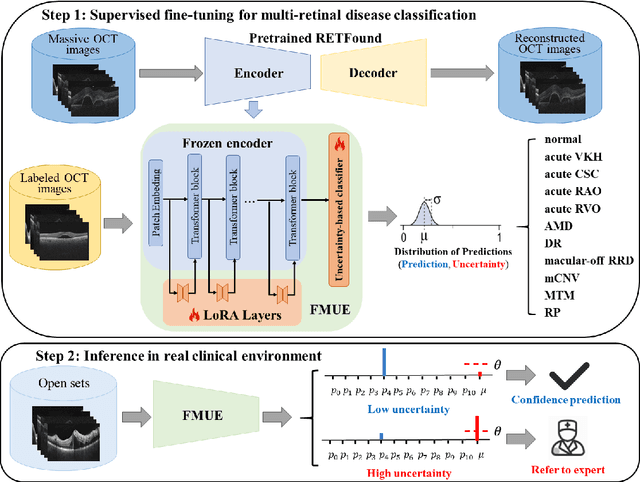
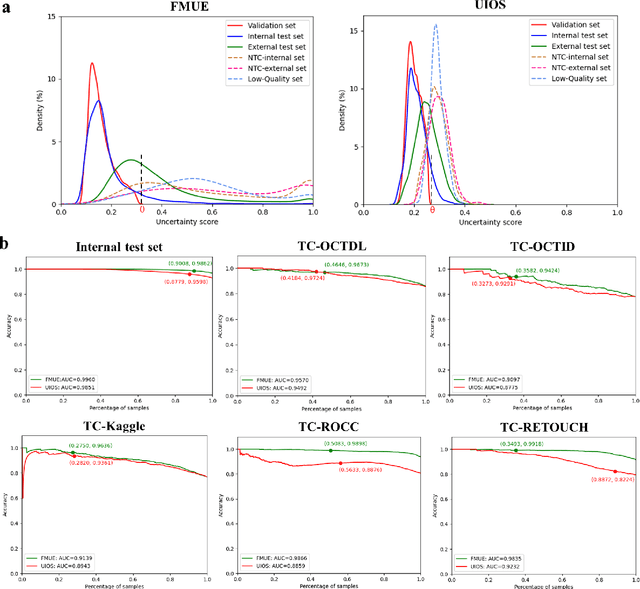
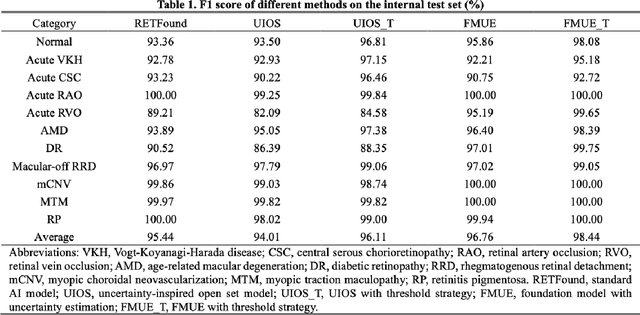
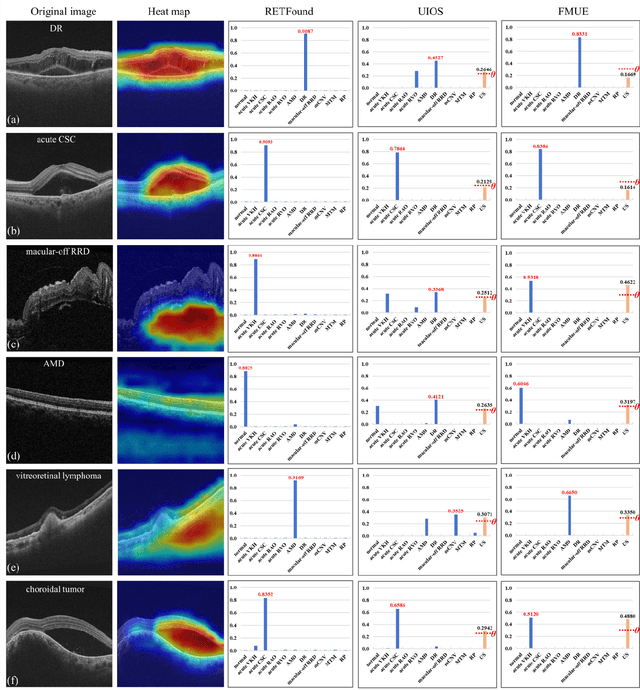
Inability to express the confidence level and detect unseen classes has limited the clinical implementation of artificial intelligence in the real-world. We developed a foundation model with uncertainty estimation (FMUE) to detect 11 retinal conditions on optical coherence tomography (OCT). In the internal test set, FMUE achieved a higher F1 score of 96.76% than two state-of-the-art algorithms, RETFound and UIOS, and got further improvement with thresholding strategy to 98.44%. In the external test sets obtained from other OCT devices, FMUE achieved an accuracy of 88.75% and 92.73% before and after thresholding. Our model is superior to two ophthalmologists with a higher F1 score (95.17% vs. 61.93% &71.72%). Besides, our model correctly predicts high uncertainty scores for samples with ambiguous features, of non-target-category diseases, or with low-quality to prompt manual checks and prevent misdiagnosis. FMUE provides a trustworthy method for automatic retinal anomalies detection in the real-world clinical open set environment.
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024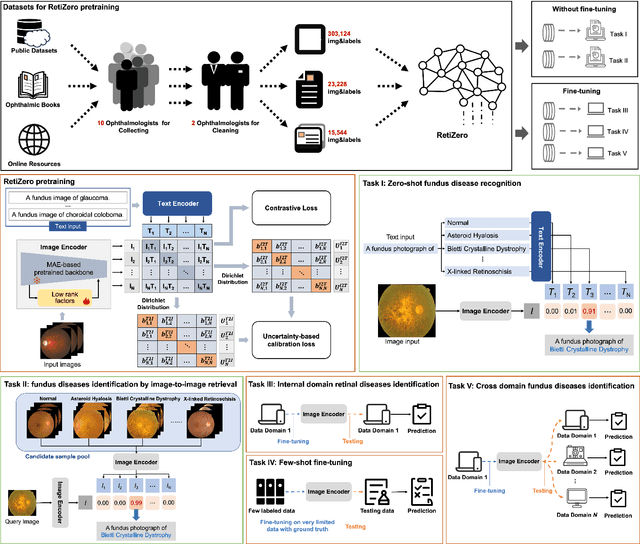
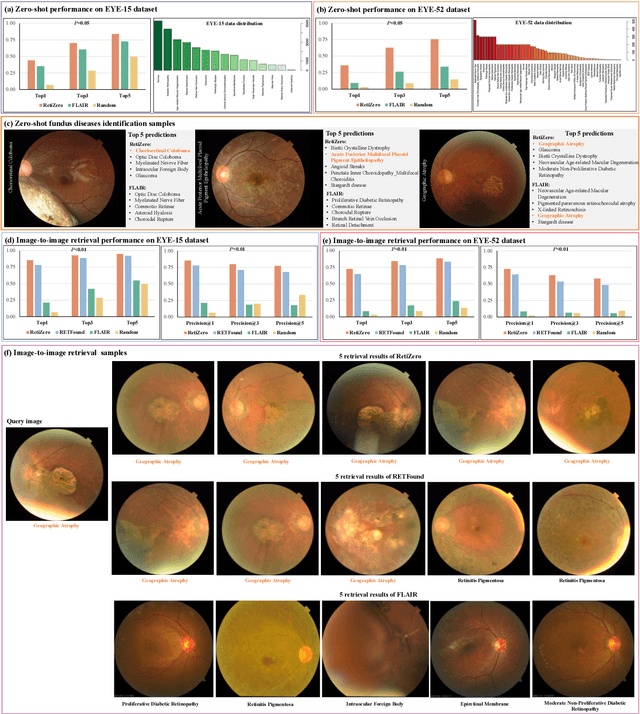
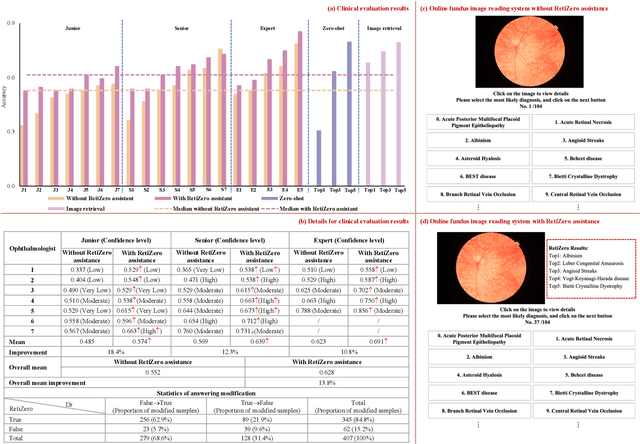
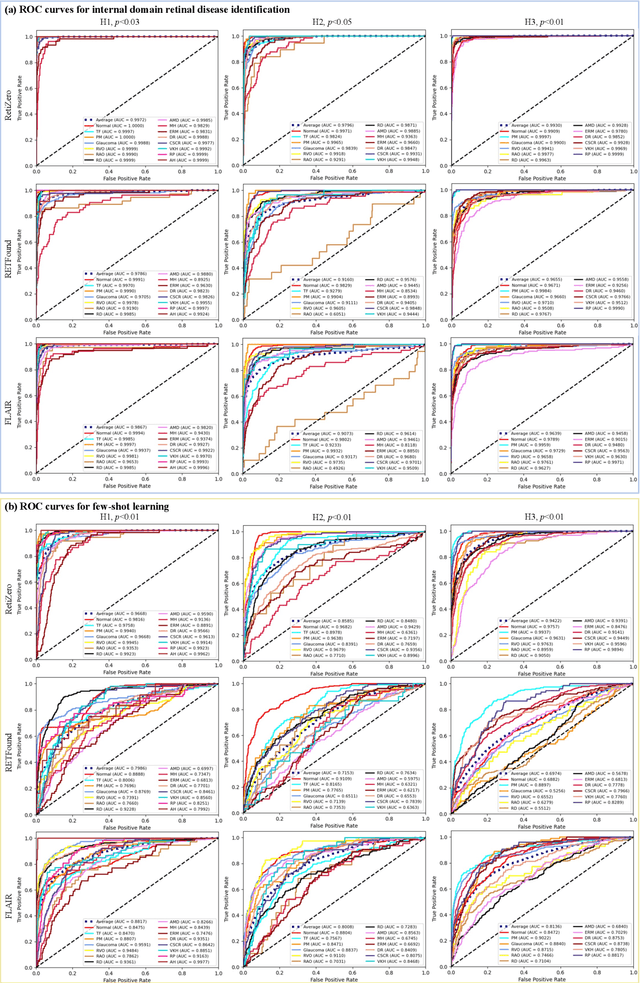
The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.
Segmentation of fundus vascular images based on a dual-attention mechanism
May 05, 2023Accurately segmenting blood vessels in retinal fundus images is crucial in the early screening, diagnosing, and evaluating some ocular diseases. However, significant light variations and non-uniform contrast in these images make segmentation quite challenging. Thus, this paper employ an attention fusion mechanism that combines the channel attention and spatial attention mechanisms constructed by Transformer to extract information from retinal fundus images in both spatial and channel dimensions. To eliminate noise from the encoder image, a spatial attention mechanism is introduced in the skip connection. Moreover, a Dropout layer is employed to randomly discard some neurons, which can prevent overfitting of the neural network and improve its generalization performance. Experiments were conducted on publicly available datasets DERIVE, STARE, and CHASEDB1. The results demonstrate that our method produces satisfactory results compared to some recent retinal fundus image segmentation algorithms.
Uncertainty-inspired Open Set Learning for Retinal Anomaly Identification
Apr 08, 2023
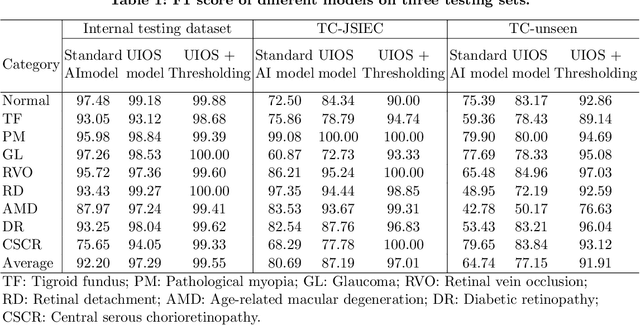


Failure to recognize samples from the classes unseen during training is a major limit of artificial intelligence (AI) in real-world implementation of retinal anomaly classification. To resolve this obstacle, we propose an uncertainty-inspired open-set (UIOS) model which was trained with fundus images of 9 common retinal conditions. Besides the probability of each category, UIOS also calculates an uncertainty score to express its confidence. Our UIOS model with thresholding strategy achieved an F1 score of 99.55%, 97.01% and 91.91% for the internal testing set, external testing set and non-typical testing set, respectively, compared to the F1 score of 92.20%, 80.69% and 64.74% by the standard AI model. Furthermore, UIOS correctly predicted high uncertainty scores, which prompted the need for a manual check, in the datasets of rare retinal diseases, low-quality fundus images, and non-fundus images. This work provides a robust method for real-world screening of retinal anomalies.
Curvilinear object segmentation in medical images based on ODoS filter and deep learning network
Jan 18, 2023Automatic segmentation of curvilinear objects in medical images plays an important role in the diagnosis and evaluation of human diseases, yet it is a challenging uncertainty for the complex segmentation task due to different issues like various image appearance, low contrast between curvilinear objects and their surrounding backgrounds, thin and uneven curvilinear structures, and improper background illumination. To overcome these challenges, we present a unique curvilinear structure segmentation framework based on oriented derivative of stick (ODoS) filter and deep learning network for curvilinear object segmentation in medical images. Currently, a large number of deep learning models emphasis on developing deep architectures and ignore capturing the structural features of curvature objects, which may lead to unsatisfactory results. In consequence, a new approach that incorporates the ODoS filter as part of a deep learning network is presented to improve the spatial attention of curvilinear objects. In which, the original image is considered as principal part to describe various image appearance and complex background illumination, the multi-step strategy is used to enhance contrast between curvilinear objects and their surrounding backgrounds, and the vector field is applied to discriminate thin and uneven curvilinear structures. Subsequently, a deep learning framework is employed to extract varvious structural features for curvilinear object segmentation in medical images. The performance of the computational model was validated in experiments with publicly available DRIVE, STARE and CHASEDB1 datasets. Experimental results indicate that the presented model has yielded surprising results compared with some state-of-the-art methods.
Pulmonary Fissure Segmentation in CT Images Based on ODoS Filter and Shape Features
Jan 23, 2022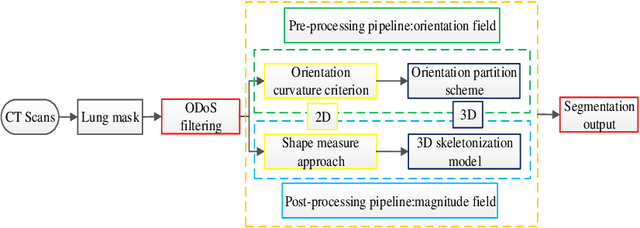
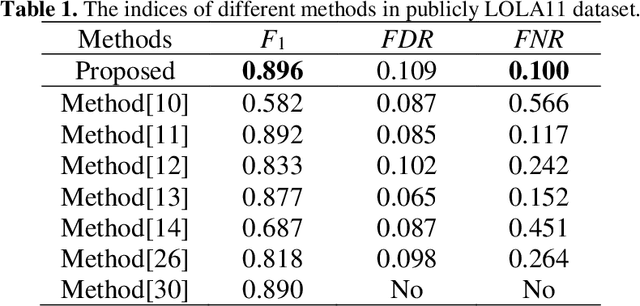
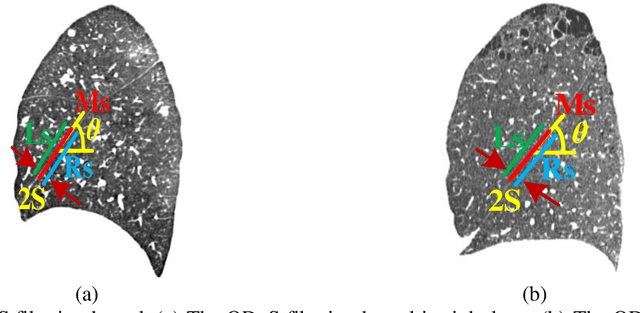

Priori knowledge of pulmonary anatomy plays a vital role in diagnosis of lung diseases. In CT images, pulmonary fissure segmentation is a formidable mission due to various of factors. To address the challenge, an useful approach based on ODoS filter and shape features is presented for pulmonary fissure segmentation. Here, we adopt an ODoS filter by merging the orientation information and magnitude information to highlight structure features for fissure enhancement, which can effectively distinguish between pulmonary fissures and clutters. Motivated by the fact that pulmonary fissures appear as linear structures in 2D space and planar structures in 3D space in orientation field, an orientation curvature criterion and an orientation partition scheme are fused to separate fissure patches and other structures in different orientation partition, which can suppress parts of clutters. Considering the shape difference between pulmonary fissures and tubular structures in magnitude field, a shape measure approach and a 3D skeletonization model are combined to segment pulmonary fissures for clutters removal. When applying our scheme to 55 chest CT scans which acquired from a publicly available LOLA11 datasets, the median F1-score, False Discovery Rate (FDR), and False Negative Rate (FNR) respectively are 0.896, 0.109, and 0.100, which indicates that the presented method has a satisfactory pulmonary fissure segmentation performance.
Automatic segmentation of novel coronavirus pneumonia lesions in CT images utilizing deep-supervised ensemble learning network
Nov 17, 2021
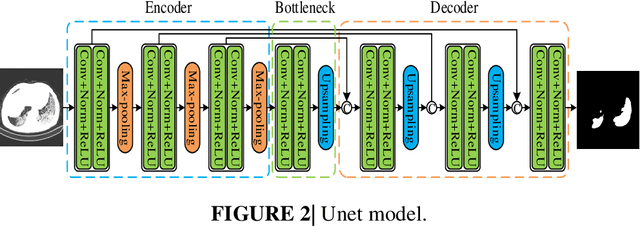
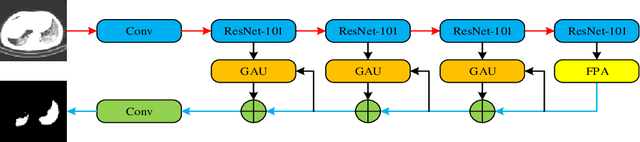
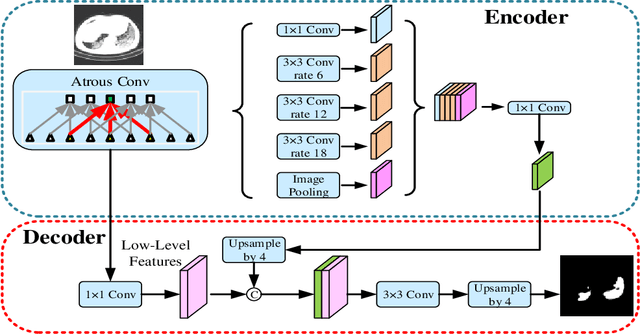
Background: The 2019 novel coronavirus disease (COVID-19) has been spread widely in the world, causing a huge threat to people's living environment. Objective: Under computed tomography (CT) imaging, the structure features of COVID-19 lesions are complicated and varied greatly in different cases. To accurately locate COVID-19 lesions and assist doctors to make the best diagnosis and treatment plan, a deep-supervised ensemble learning network is presented for COVID-19 lesion segmentation in CT images. Methods: Considering the fact that a large number of COVID-19 CT images and the corresponding lesion annotations are difficult to obtained, a transfer learning strategy is employed to make up for the shortcoming and alleviate the overfitting problem. Based on the reality that traditional single deep learning framework is difficult to extract COVID-19 lesion features effectively, which may cause some lesions to be undetected. To overcome the problem, a deep-supervised ensemble learning network is presented to combine with local and global features for COVID-19 lesion segmentation. Results: The performance of the proposed method was validated in experiments with a publicly available dataset. Compared with manual annotations, the proposed method acquired a high intersection over union (IoU) of 0.7279. Conclusion: A deep-supervised ensemble learning network was presented for coronavirus pneumonia lesion segmentation in CT images. The effectiveness of the proposed method was verified by visual inspection and quantitative evaluation. Experimental results shown that the proposed mehtod has a perfect performance in COVID-19 lesion segmentation.