 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of High-resolution Light Field Imaging via Beam Splitter-based Hybrid Lenses
Feb 29, 2024In this paper, we design a beam splitter-based hybrid light field imaging prototype to record 4D light field image and high-resolution 2D image simultaneously, and make a hybrid light field dataset. The 2D image could be considered as the high-resolution ground truth corresponding to the low-resolution central sub-aperture image of 4D light field image. Subsequently, we propose an unsupervised learning-based super-resolution framework with the hybrid light field dataset, which adaptively settles the light field spatial super-resolution problem with a complex degradation model. Specifically, we design two loss functions based on pre-trained models that enable the super-resolution network to learn the detailed features and light field parallax structure with only one ground truth. Extensive experiments demonstrate the same superiority of our approach with supervised learning-based state-of-the-art ones. To our knowledge, it is the first end-to-end unsupervised learning-based spatial super-resolution approach in light field imaging research, whose input is available from our beam splitter-based hybrid light field system. The hardware and software together may help promote the application of light field super-resolution to a great extent.
Light Field Imaging in the Restrictive Object Space based on Flexible Angular Plane
Dec 04, 2023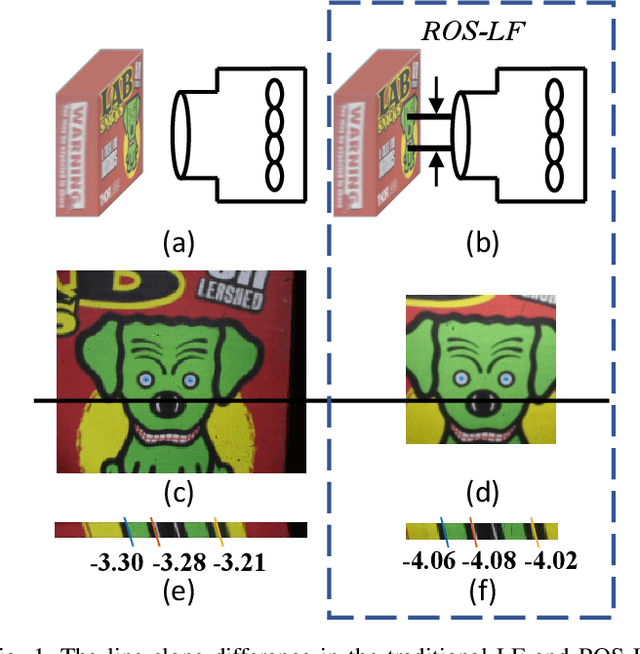

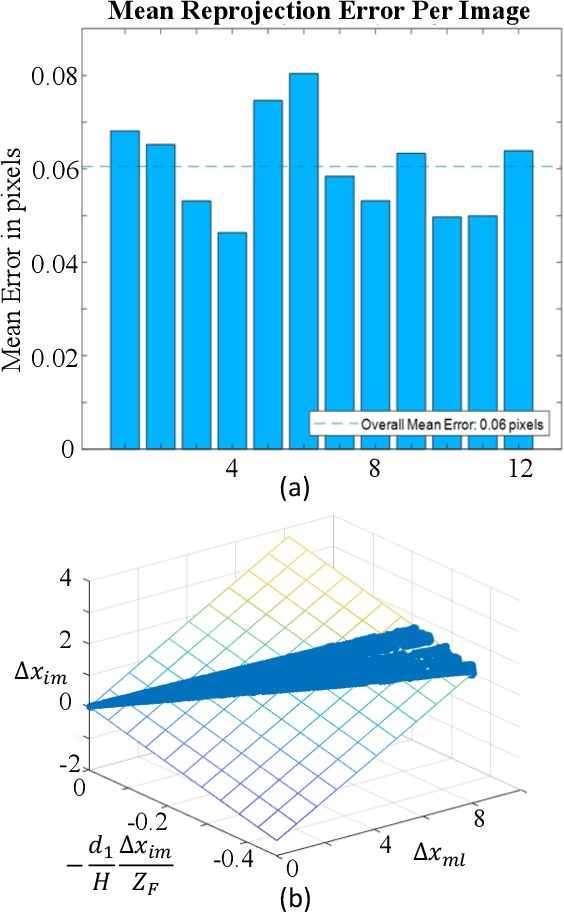
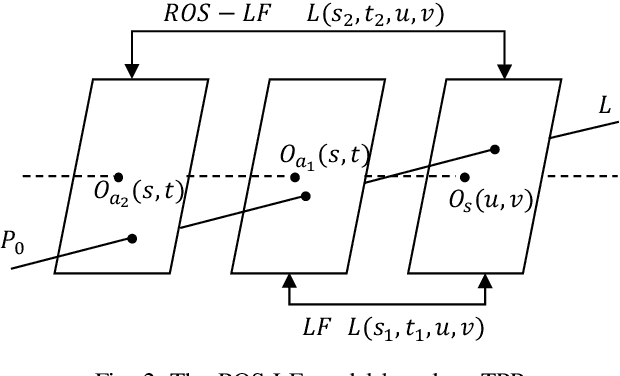
In some applications, the object space of light field imaging system is restrictive, such as industrial and medical endoscopes. If the traditional light field imaging system is used in the restrictive object space (ROS) directly but without any specific considerations, the ROS will lead to severe microlens image distortions and then affects light field decoding, calibration and 3D reconstruction. The light field imaging in restrictive object space (ROS-LF) is complicated but significant. In this paper, we first deduce that the reason of the microlens image deviation is the position variation of the angular plane, then we propose the flexible angular plane for ROS-LF, while in the traditional light field the angular plane always coincides with the main lens plane. Subsequently, we propose the microlens image non-distortion principle for ROS-LF and introduce the ROS-LF imaging principle. We demonstrate that the difference is an aperture constant term between the ROS-LF and traditional light field imaging models. At last, we design a ROS-LF simulated system and calibrate it to verify principles proposed in this paper.
Learning based Deep Disentangling Light Field Reconstruction and Disparity Estimation Application
Nov 14, 2023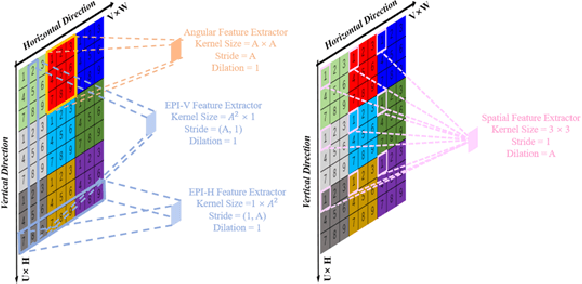
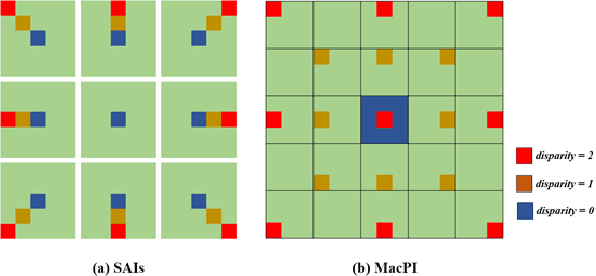
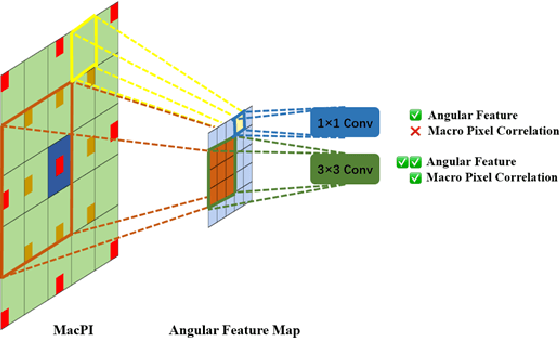
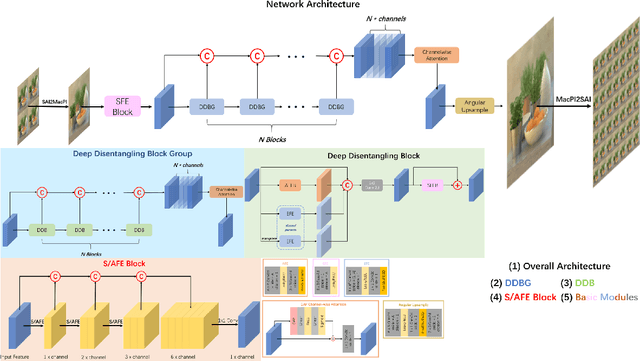
Light field cameras have a wide range of uses due to their ability to simultaneously record light intensity and direction. The angular resolution of light fields is important for downstream tasks such as depth estimation, yet is often difficult to improve due to hardware limitations. Conventional methods tend to perform poorly against the challenge of large disparity in sparse light fields, while general CNNs have difficulty extracting spatial and angular features coupled together in 4D light fields. The light field disentangling mechanism transforms the 4D light field into 2D image format, which is more favorable for CNN for feature extraction. In this paper, we propose a Deep Disentangling Mechanism, which inherits the principle of the light field disentangling mechanism and further develops the design of the feature extractor and adds advanced network structure. We design a light-field reconstruction network (i.e., DDASR) on the basis of the Deep Disentangling Mechanism, and achieve SOTA performance in the experiments. In addition, we design a Block Traversal Angular Super-Resolution Strategy for the practical application of depth estimation enhancement where the input views is often higher than 2x2 in the experiments resulting in a high memory usage, which can reduce the memory usage while having a better reconstruction performance.
An Interpretable Constructive Algorithm for Incremental Random Weight Neural Networks and Its Application
Jul 01, 2023Incremental random weight neural networks (IRWNNs) have gained attention in view of its easy implementation and fast learning. However, a significant drawback of IRWNNs is that the elationship between the hidden parameters (node)and the residual error (model performance) is difficult to be interpreted. To address the above issue, this article proposes an interpretable constructive algorithm (ICA) with geometric information constraint. First, based on the geometric relationship between the hidden parameters and the residual error, an interpretable geometric information constraint is proposed to randomly assign the hidden parameters. Meanwhile, a node pool strategy is employed to obtain hidden parameters that is more conducive to convergence from hidden parameters satisfying the proposed constraint. Furthermore, the universal approximation property of the ICA is proved. Finally, a lightweight version of ICA is presented for large-scale data modeling tasks. Experimental results on six benchmark datasets and a numerical simulation dataset demonstrate that the ICA outperforms other constructive algorithms in terms of modeling speed, model accuracy, and model network structure. Besides, two practical industrial application case are used to validate the effectiveness of ICA in practical applications.
Online Decomposition of Surface Electromyogram into Individual Motor Unit Activities Using Progressive FastICA Peel-off
Jan 05, 2023



Surface electromyogram (SEMG) decomposition provides a promising tool for decoding and understanding neural drive information non-invasively. In contrast to previous SEMG decomposition methods mainly developed in offline conditions, there are few studies on online SEMG decomposition. A novel method for online decomposition of SEMG data is presented using the progressive FastICA peel-off (PFP) algorithm. The online method consists of an offline prework stage and an online decomposition stage. More specifically, a series of separation vectors are first initialized by the originally offline version of the PFP algorithm from SEMG data recorded in advance. Then they are applied to online SEMG data to extract motor unit spike trains precisely. The performance of the proposed online SEMG decomposition method was evaluated by both simulation and experimental approaches. It achieved an online decomposition accuracy of 98.53% when processing simulated SEMG data. For decomposing experimental SEMG data, the proposed online method was able to extract an average of 12.00 +- 3.46 MUs per trial, with a matching rate of 90.38% compared with results from the expert-guided offline decomposition. Our study provides a valuable way of online decomposition of SEMG data with advanced applications in movement control and health.
FFCNet: Fourier Transform-Based Frequency Learning and Complex Convolutional Network for Colon Disease Classification
Jul 04, 2022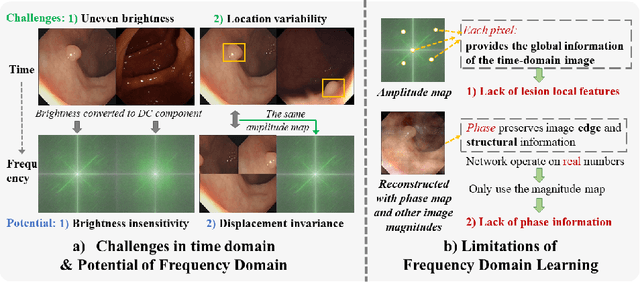
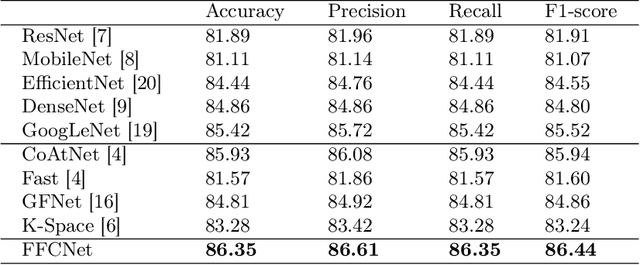
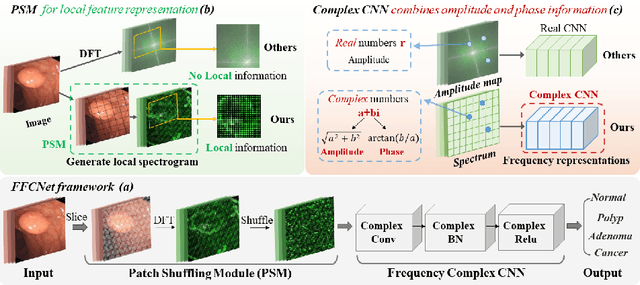
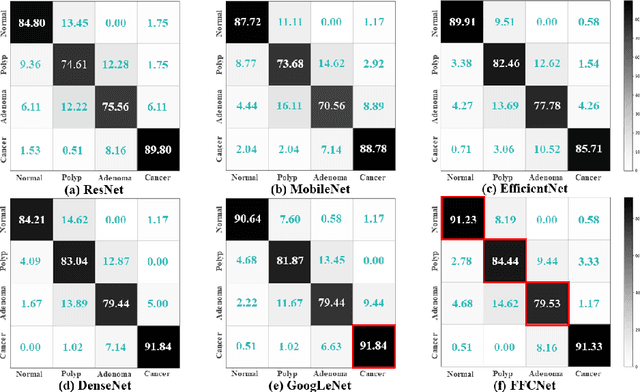
Reliable automatic classification of colonoscopy images is of great significance in assessing the stage of colonic lesions and formulating appropriate treatment plans. However, it is challenging due to uneven brightness, location variability, inter-class similarity, and intra-class dissimilarity, affecting the classification accuracy. To address the above issues, we propose a Fourier-based Frequency Complex Network (FFCNet) for colon disease classification in this study. Specifically, FFCNet is a novel complex network that enables the combination of complex convolutional networks with frequency learning to overcome the loss of phase information caused by real convolution operations. Also, our Fourier transform transfers the average brightness of an image to a point in the spectrum (the DC component), alleviating the effects of uneven brightness by decoupling image content and brightness. Moreover, the image patch scrambling module in FFCNet generates random local spectral blocks, empowering the network to learn long-range and local diseasespecific features and improving the discriminative ability of hard samples. We evaluated the proposed FFCNet on an in-house dataset with 2568 colonoscopy images, showing our method achieves high performance outperforming previous state-of-the art methods with an accuracy of 86:35% and an accuracy of 4.46% higher than the backbone. The project page with code is available at https://github.com/soleilssss/FFCNet.
3D Face Parsing via Surface Parameterization and 2D Semantic Segmentation Network
Jun 18, 2022
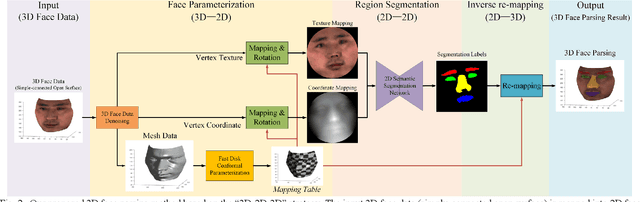
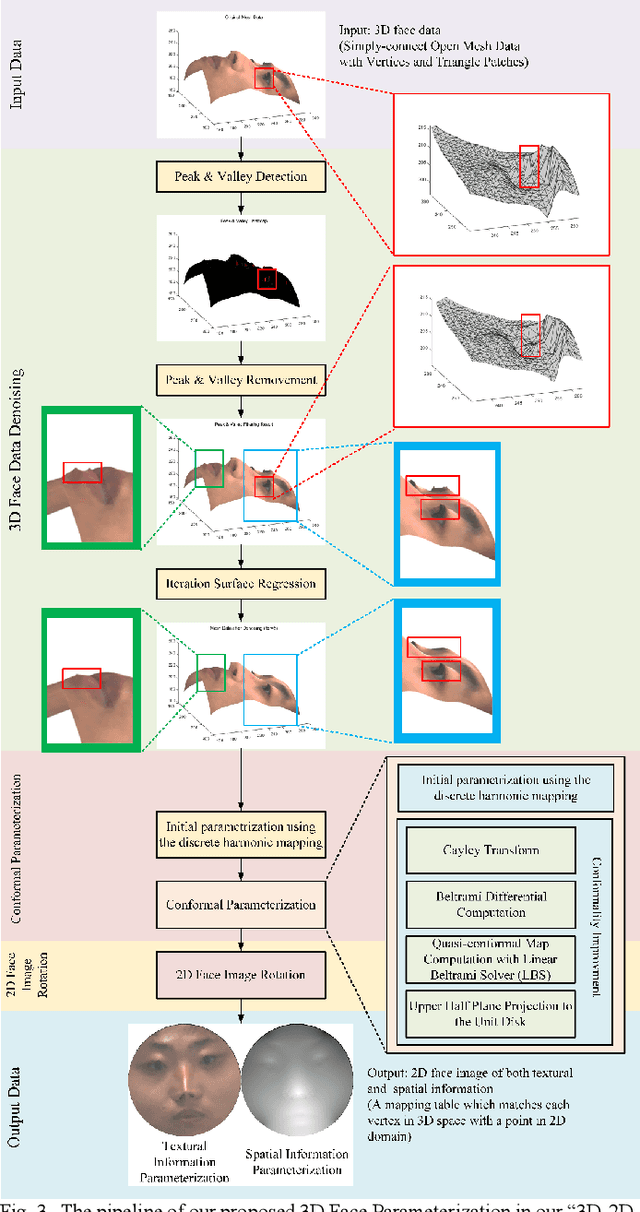
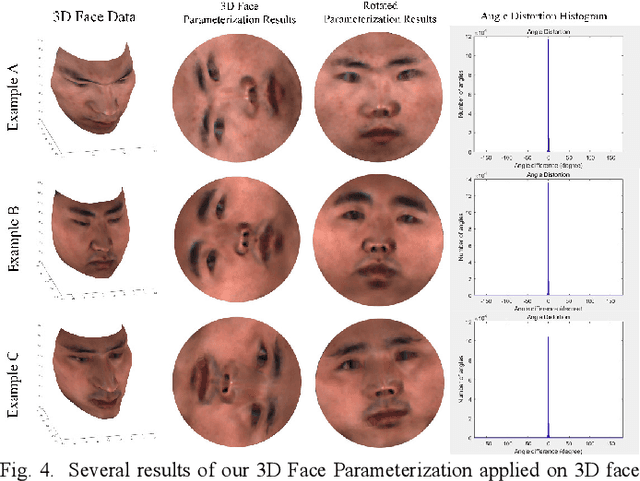
Face parsing assigns pixel-wise semantic labels as the face representation for computers, which is the fundamental part of many advanced face technologies. Compared with 2D face parsing, 3D face parsing shows more potential to achieve better performance and further application, but it is still challenging due to 3D mesh data computation. Recent works introduced different methods for 3D surface segmentation, while the performance is still limited. In this paper, we propose a method based on the "3D-2D-3D" strategy to accomplish 3D face parsing. The topological disk-like 2D face image containing spatial and textural information is transformed from the sampled 3D face data through the face parameterization algorithm, and a specific 2D network called CPFNet is proposed to achieve the semantic segmentation of the 2D parameterized face data with multi-scale technologies and feature aggregation. The 2D semantic result is then inversely re-mapped to 3D face data, which finally achieves the 3D face parsing. Experimental results show that both CPFNet and the "3D-2D-3D" strategy accomplish high-quality 3D face parsing and outperform state-of-the-art 2D networks as well as 3D methods in both qualitative and quantitative comparisons.
Light Field Depth Estimation Based on Stitched-EPI
Mar 29, 2022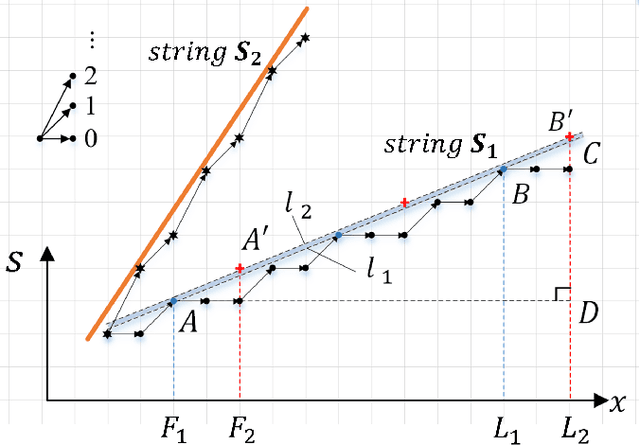
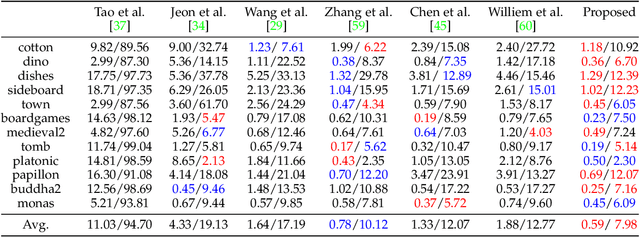
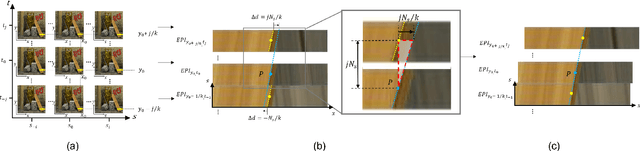
Depth estimation is one of the most essential problems for light field applications. In EPI-based methods, the slope computation usually suffers low accuracy due to the discretization error and low angular resolution. In addition, recent methods work well in most regions but often struggle with blurry edges over occluded regions and ambiguity over texture-less regions. To address these challenging issues, we first propose the stitched-EPI and half-stitched-EPI algorithms for non-occluded and occluded regions, respectively. The algorithms improve slope computation by shifting and concatenating lines in different EPIs but related to the same point in 3D scene, while the half-stitched-EPI only uses non-occluded part of lines. Combined with the joint photo-consistency cost proposed by us, the more accurate and robust depth map can be obtained in both occluded and non-occluded regions. Furthermore, to improve the depth estimation in texture-less regions, we propose a depth propagation strategy that determines their depth from the edge to interior, from accurate regions to coarse regions. Experimental and ablation results demonstrate that the proposed method achieves accurate and robust depth maps in all regions effectively.
Pulmonary Fissure Segmentation in CT Images Based on ODoS Filter and Shape Features
Jan 23, 2022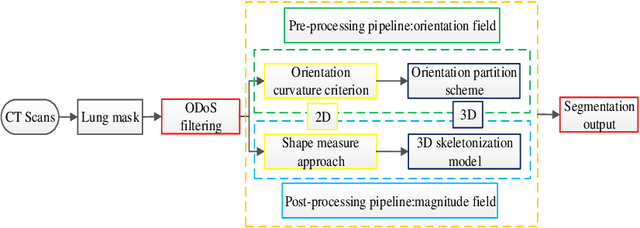
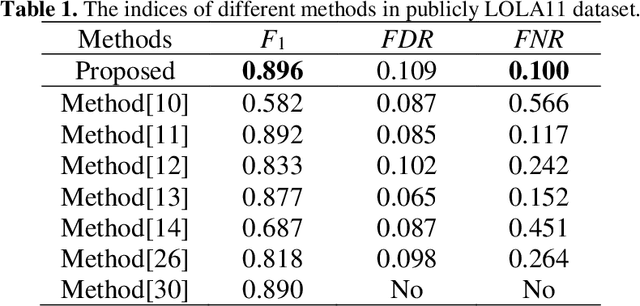
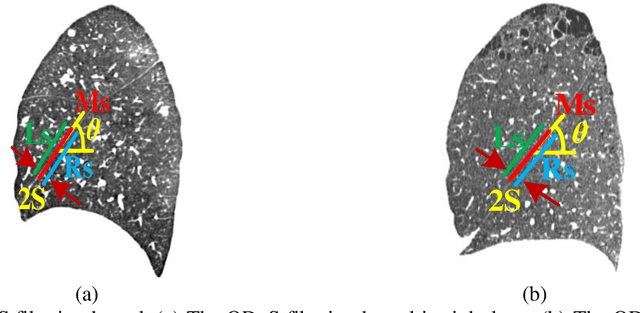

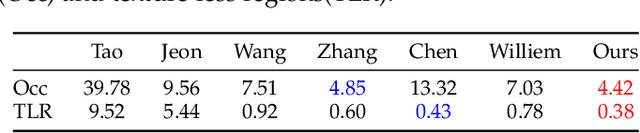
Priori knowledge of pulmonary anatomy plays a vital role in diagnosis of lung diseases. In CT images, pulmonary fissure segmentation is a formidable mission due to various of factors. To address the challenge, an useful approach based on ODoS filter and shape features is presented for pulmonary fissure segmentation. Here, we adopt an ODoS filter by merging the orientation information and magnitude information to highlight structure features for fissure enhancement, which can effectively distinguish between pulmonary fissures and clutters. Motivated by the fact that pulmonary fissures appear as linear structures in 2D space and planar structures in 3D space in orientation field, an orientation curvature criterion and an orientation partition scheme are fused to separate fissure patches and other structures in different orientation partition, which can suppress parts of clutters. Considering the shape difference between pulmonary fissures and tubular structures in magnitude field, a shape measure approach and a 3D skeletonization model are combined to segment pulmonary fissures for clutters removal. When applying our scheme to 55 chest CT scans which acquired from a publicly available LOLA11 datasets, the median F1-score, False Discovery Rate (FDR), and False Negative Rate (FNR) respectively are 0.896, 0.109, and 0.100, which indicates that the presented method has a satisfactory pulmonary fissure segmentation performance.
AWSnet: An Auto-weighted Supervision Attention Network for Myocardial Scar and Edema Segmentation in Multi-sequence Cardiac Magnetic Resonance Images
Jan 14, 2022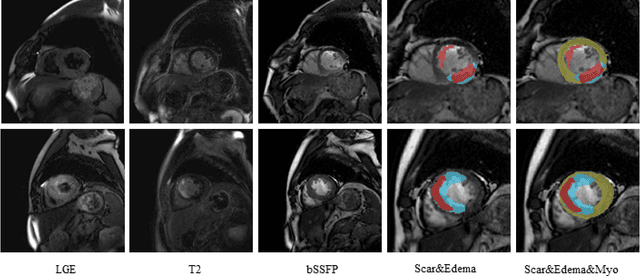
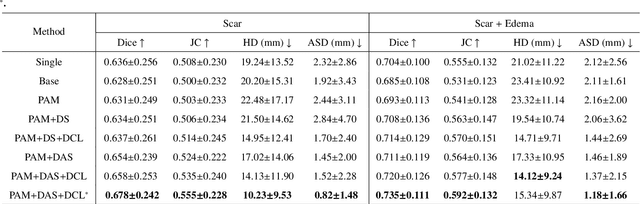
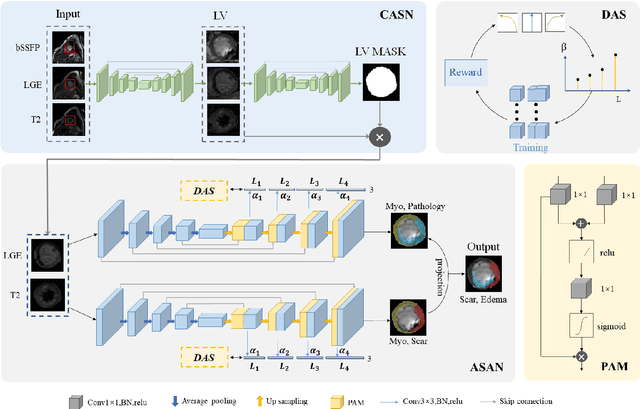
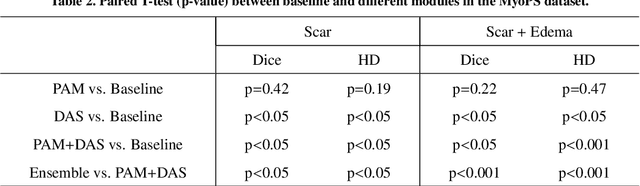
Multi-sequence cardiac magnetic resonance (CMR) provides essential pathology information (scar and edema) to diagnose myocardial infarction. However, automatic pathology segmentation can be challenging due to the difficulty of effectively exploring the underlying information from the multi-sequence CMR data. This paper aims to tackle the scar and edema segmentation from multi-sequence CMR with a novel auto-weighted supervision framework, where the interactions among different supervised layers are explored under a task-specific objective using reinforcement learning. Furthermore, we design a coarse-to-fine framework to boost the small myocardial pathology region segmentation with shape prior knowledge. The coarse segmentation model identifies the left ventricle myocardial structure as a shape prior, while the fine segmentation model integrates a pixel-wise attention strategy with an auto-weighted supervision model to learn and extract salient pathological structures from the multi-sequence CMR data. Extensive experimental results on a publicly available dataset from Myocardial pathology segmentation combining multi-sequence CMR (MyoPS 2020) demonstrate our method can achieve promising performance compared with other state-of-the-art methods. Our method is promising in advancing the myocardial pathology assessment on multi-sequence CMR data. To motivate the community, we have made our code publicly available via https://github.com/soleilssss/AWSnet/tree/master.