 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fair Graph Representation Learning in Social Networks
Oct 15, 2024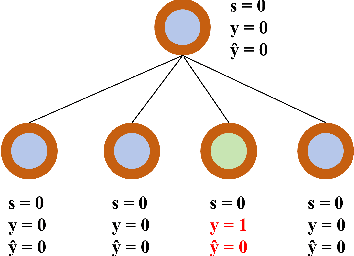
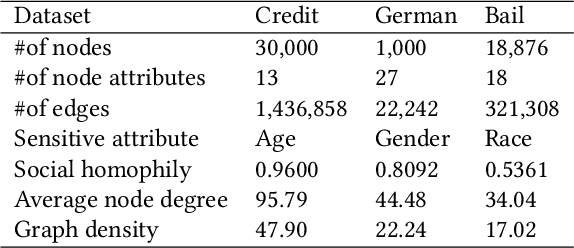
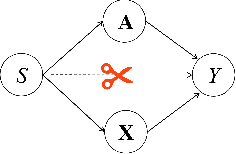
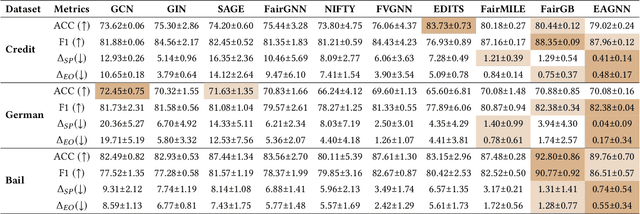
With the widespread use of Graph Neural Networks (GNNs) for representation learning from network data, the fairness of GNN models has raised great attention lately. Fair GNNs aim to ensure that node representations can be accurately classified, but not easily associated with a specific group. Existing advanced approaches essentially enhance the generalisation of node representation in combination with data augmentation strategy, and do not directly impose constraints on the fairness of GNNs. In this work, we identify that a fundamental reason for the unfairness of GNNs in social network learning is the phenomenon of social homophily, i.e., users in the same group are more inclined to congregate. The message-passing mechanism of GNNs can cause users in the same group to have similar representations due to social homophily, leading model predictions to establish spurious correlations with sensitive attributes. Inspired by this reason, we propose a method called Equity-Aware GNN (EAGNN) towards fair graph representation learning. Specifically, to ensure that model predictions are independent of sensitive attributes while maintaining prediction performance, we introduce constraints for fair representation learning based on three principles: sufficiency, independence, and separation. We theoretically demonstrate that our EAGNN method can effectively achieve group fairness. Extensive experiments on three datasets with varying levels of social homophily illustrate that our EAGNN method achieves the state-of-the-art performance across two fairness metrics and offers competitive effectiveness.
Mitigating Propensity Bias of Large Language Models for Recommender Systems
Sep 30, 2024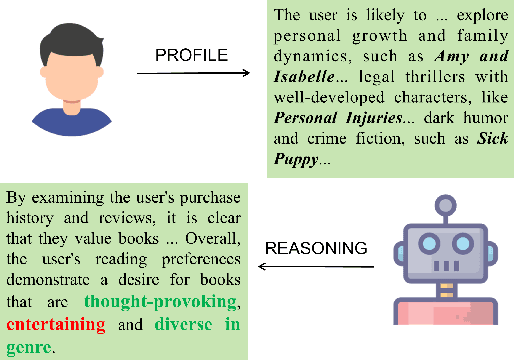

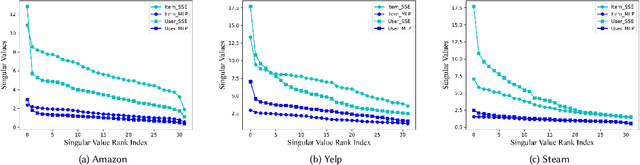
The rapid development of Large Language Models (LLMs) creates new opportunities for recommender systems, especially by exploiting the side information (e.g., descriptions and analyses of items) generated by these models. However, aligning this side information with collaborative information from historical interactions poses significant challenges. The inherent biases within LLMs can skew recommendations, resulting in distorted and potentially unfair user experiences. On the other hand, propensity bias causes side information to be aligned in such a way that it often tends to represent all inputs in a low-dimensional subspace, leading to a phenomenon known as dimensional collapse, which severely restricts the recommender system's ability to capture user preferences and behaviours. To address these issues, we introduce a novel framework named Counterfactual LLM Recommendation (CLLMR). Specifically, we propose a spectrum-based side information encoder that implicitly embeds structural information from historical interactions into the side information representation, thereby circumventing the risk of dimension collapse. Furthermore, our CLLMR approach explores the causal relationships inherent in LLM-based recommender systems. By leveraging counterfactual inference, we counteract the biases introduced by LLMs. Extensive experiments demonstrate that our CLLMR approach consistently enhances the performance of various recommender models.
Community Detection for Heterogeneous Multiple Social Networks
May 07, 2024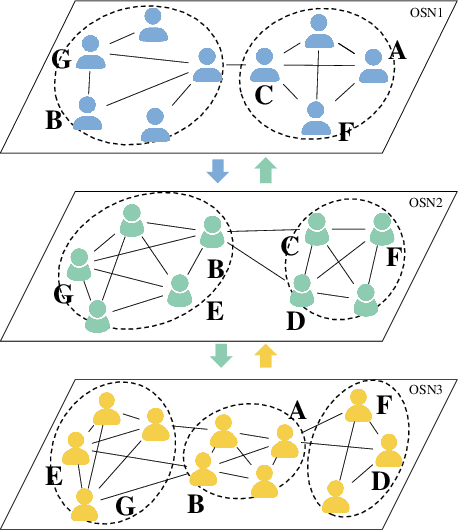
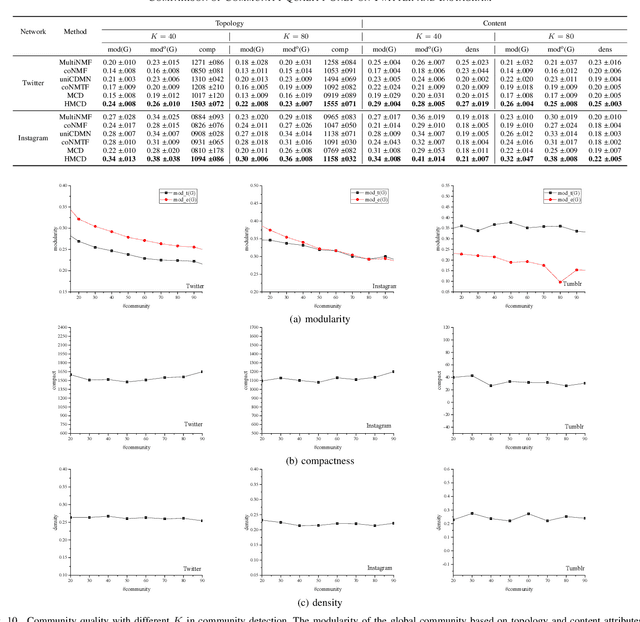
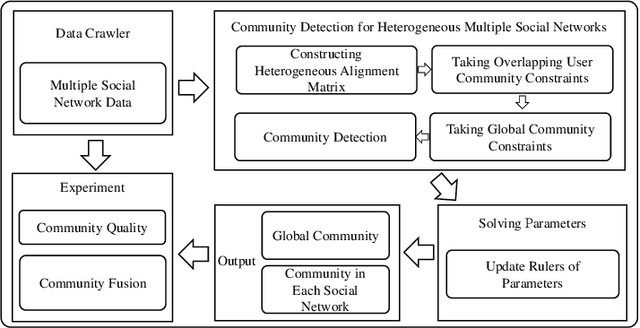
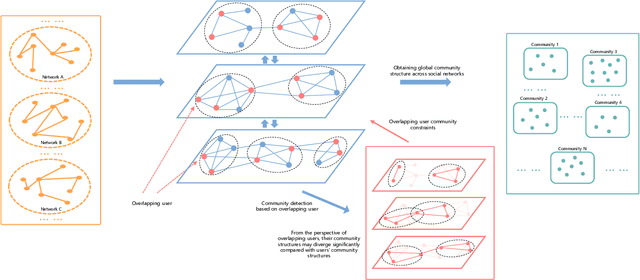
The community plays a crucial role in understanding user behavior and network characteristics in social networks. Some users can use multiple social networks at once for a variety of objectives. These users are called overlapping users who bridge different social networks. Detecting communities across multiple social networks is vital for interaction mining, information diffusion, and behavior migration analysis among networks. This paper presents a community detection method based on nonnegative matrix tri-factorization for multiple heterogeneous social networks, which formulates a common consensus matrix to represent the global fused community. Specifically, the proposed method involves creating adjacency matrices based on network structure and content similarity, followed by alignment matrices which distinguish overlapping users in different social networks. With the generated alignment matrices, the method could enhance the fusion degree of the global community by detecting overlapping user communities across networks. The effectiveness of the proposed method is evaluated with new metrics on Twitter, Instagram, and Tumblr datasets. The results of the experiments demonstrate its superior performance in terms of community quality and community fusion.
An Interpretable Constructive Algorithm for Incremental Random Weight Neural Networks and Its Application
Jul 01, 2023Incremental random weight neural networks (IRWNNs) have gained attention in view of its easy implementation and fast learning. However, a significant drawback of IRWNNs is that the elationship between the hidden parameters (node)and the residual error (model performance) is difficult to be interpreted. To address the above issue, this article proposes an interpretable constructive algorithm (ICA) with geometric information constraint. First, based on the geometric relationship between the hidden parameters and the residual error, an interpretable geometric information constraint is proposed to randomly assign the hidden parameters. Meanwhile, a node pool strategy is employed to obtain hidden parameters that is more conducive to convergence from hidden parameters satisfying the proposed constraint. Furthermore, the universal approximation property of the ICA is proved. Finally, a lightweight version of ICA is presented for large-scale data modeling tasks. Experimental results on six benchmark datasets and a numerical simulation dataset demonstrate that the ICA outperforms other constructive algorithms in terms of modeling speed, model accuracy, and model network structure. Besides, two practical industrial application case are used to validate the effectiveness of ICA in practical applications.